Selenium:Web自动化模拟
Selenium的使用
Selenium是一个自动化测试工具,它直接运行在浏览器中,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作。
对于一些JavaScript动态渲染的页面来说,此种抓取方式非常有效
1. 基本使用
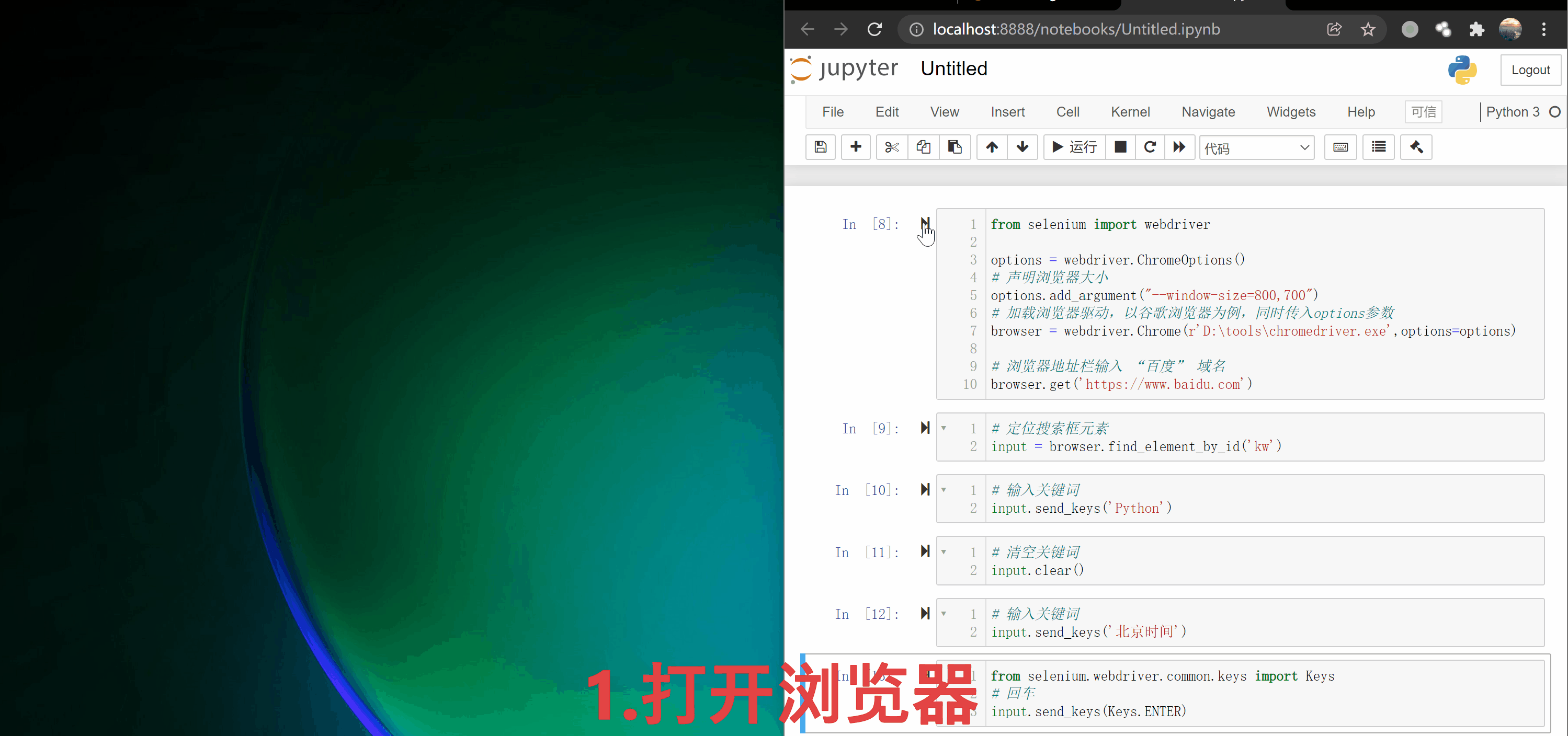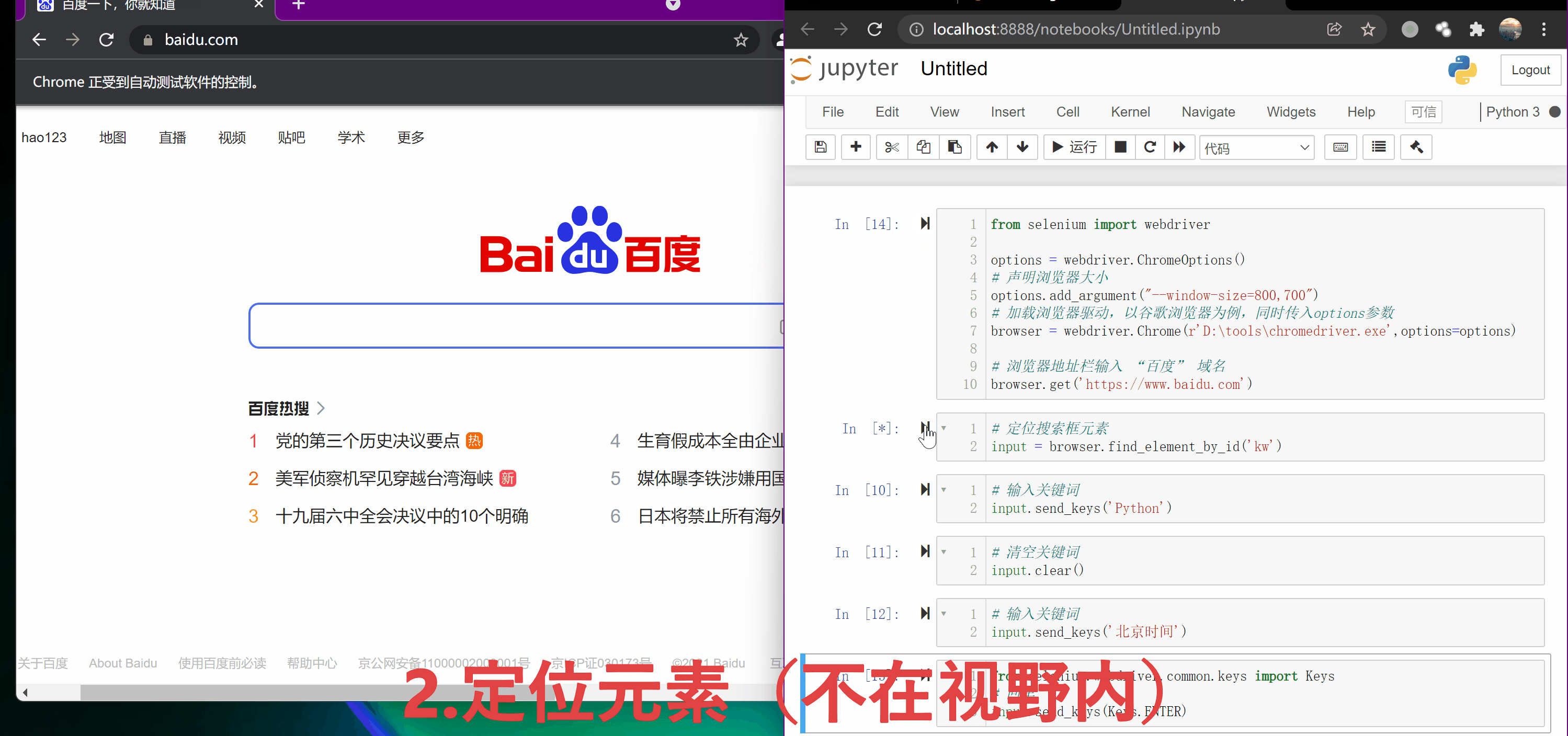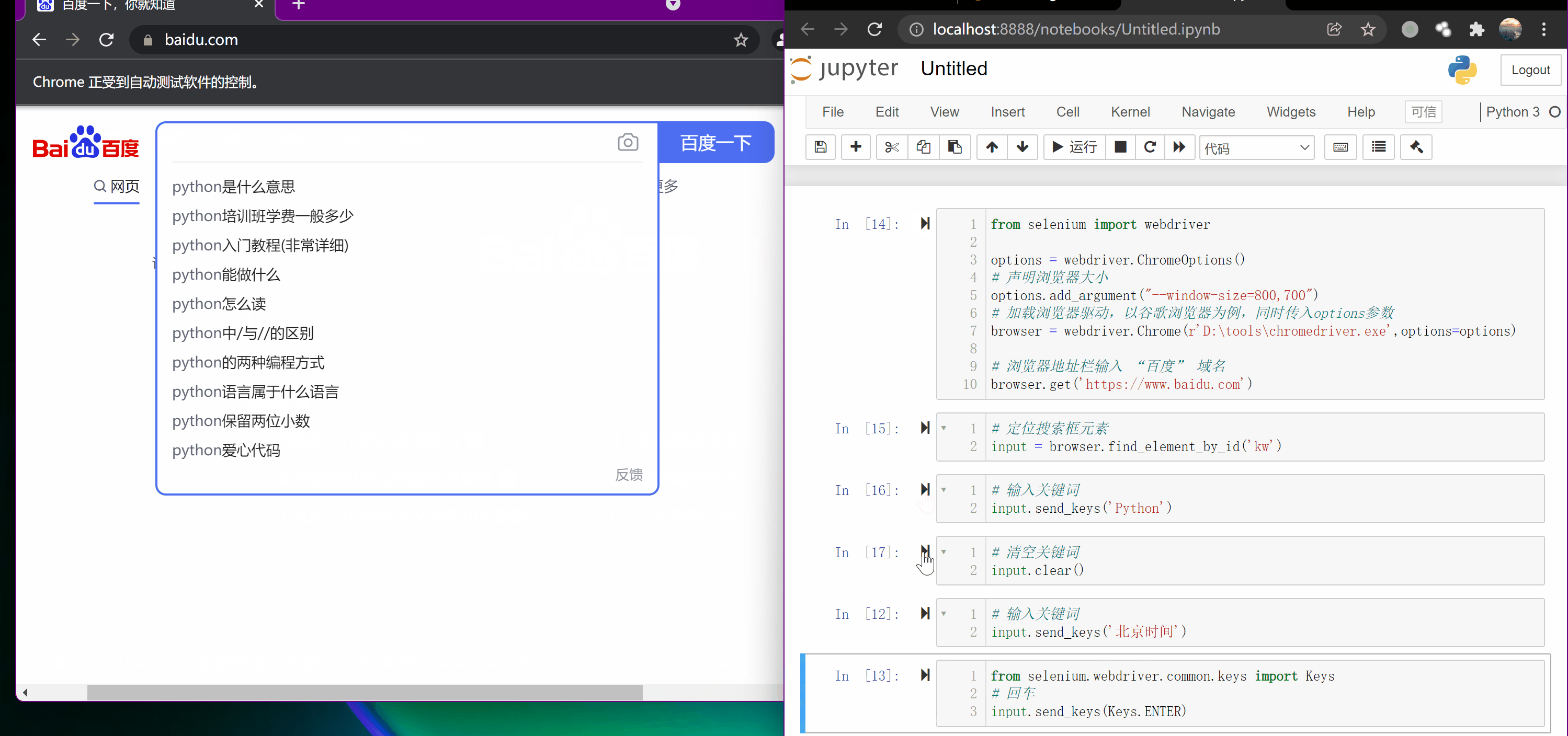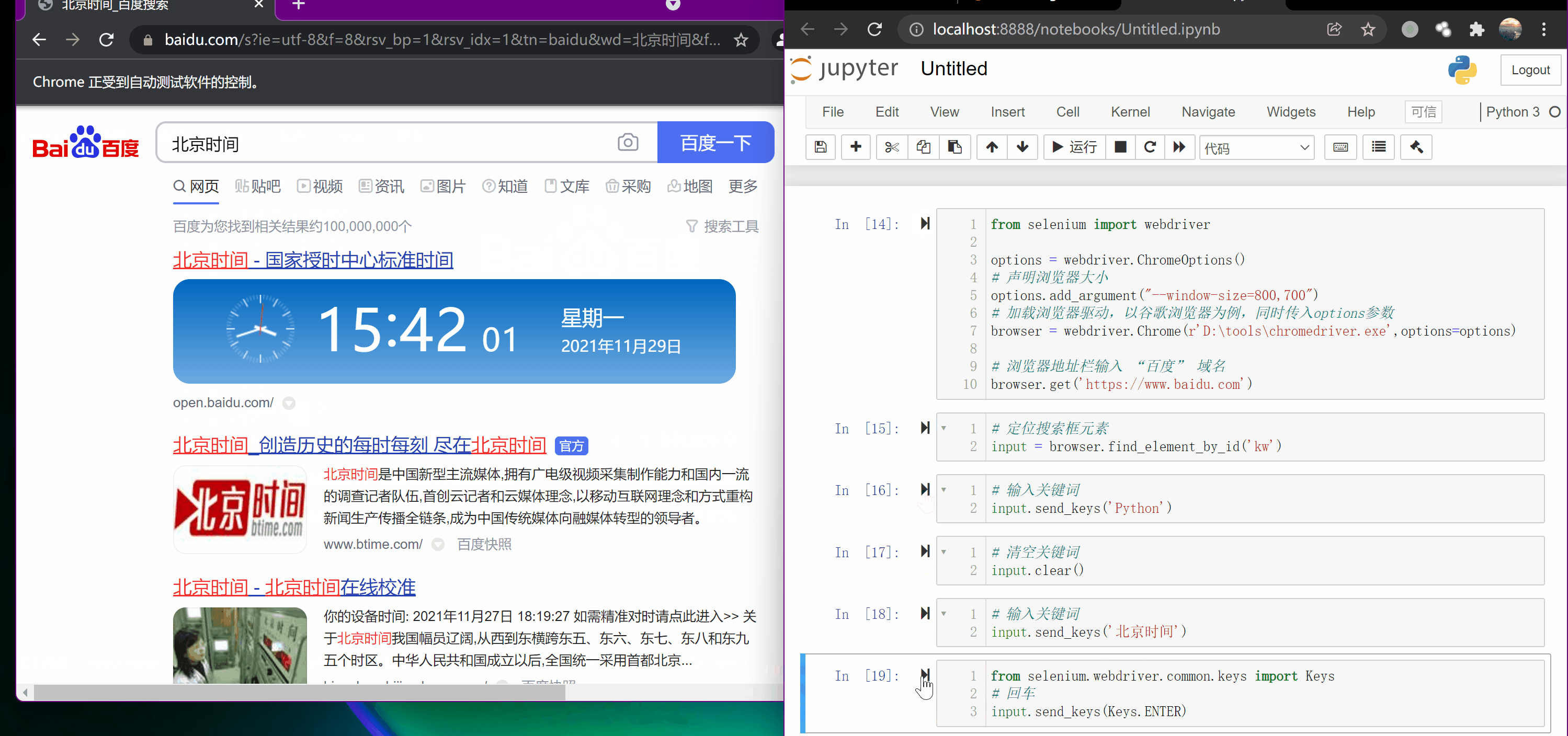
开始前,以一个简单的例子展示一下selenium有一些怎样的功能。
from selenium import webdriver # 浏览器驱动
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
try:
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw')
input.send_keys('Python')
input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser, 10)
wait.until(EC.presence_of_element_located((By.ID, 'content_left')))
print(browser.current_url)
print(browser.get_cookies())
print(browser.page_source)
finally:
browser.close()
2. 声明浏览器对象
Selenium支持非常多的浏览器,如Chrome、Firefox、Edge等,还有Android、BlackBerry等手机端的浏览器。另外,也支持无界面浏览器PhantomJS
"""
声明浏览器对象
"""
from selenium import webdriver
browser = webdriver.Chrome() # 可传入驱动浏览器的具体路径
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
完成浏览器对象的初始化并将其赋值为browser对象,接下来调用该对象即可执行各个动作以模拟浏览器操作。
3. 访问页面
"""
访问页面
"""
from selenium import webdriver
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
browser.get('https://163.com')
print(browser.page_source) #获取网页源代码
browser.close()
4. 查找节点
比如我们想要完成某个输入框输入文字,总需要知道这个输入框在哪里把?接下来通过以下方法来获取想要的节点,以便下一步执行一些动作或提取信息。
- 单个节点
# <input type="submit" value="百度一下" id="su" class="btn self-btn bg s_btn">
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
browser.get('https://www.baidu.com')
input_first = browser.find_element_by_id('su')
input_second = browser.find_element_by_xpath('//*[@id="su"]')
input_third = browser.find_element_by_xpath('//*[@value="百度一下"]')
print(input_first, input_second, input_third) # output: 三个节点都是WebElement类型,结果完全一致
print(browser.find_element(By.XPATH, '//*[@id = "su"]')) # 等同于find_element_by_xpath方法
browser.close()
列出所有获取单个节点的方法:
find_element()是一个通用方法,也是查找单个节点,需要传入两个参数:查找方式By和值
- 多个节点
顾名思义,find_elements()就是查找多个节点,列出的以下方法得到的结果均为列表类型,列表中的每个节点都是WebElement类型
5. 节点交互
接下来让浏览器模拟执行一些动作。
比较常用的方法:输入文字时用send_keys()方法,清空文字时用clear()方法,点击按钮时用click()
以下的例子中,首先驱动浏览器打开百度,然后用find_element_by_xpath()方法获取输入框,然后用send_keys()方法输入()文字,等待一秒用clear()方法清空输入框,再次调用send_keys()方法输入()文字,之后用find_element_by_xpath方法获取搜索按钮,最后再调用click()方法完成搜索动作。
from selenium import webdriver
import time
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
browser.get('https://www.baidu.com')
input = browser.find_element_by_xpath('//*[@id="kw"]')
input.send_keys('你好')
time.sleep(1)
input.clear()
input.send_keys('清空')
button = browser.find_element_by_xpath('//*[@value="百度一下"]')
button.click()
更多的操作可以参见官网文档的交互动作介绍:7. WebDriver API - Selenium Python Bindings 2 documentation
6. 动作链
在一些场景中,我们可能想实现一些操作,它们没有特定的执行对象,比如鼠标拖拽、键盘按键等,这些动作用另一种方式来执行,那就是动作链。
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
url = 'https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
# frame()传参:按索引、名称或webelement将焦点切换到指定的框架,
# switch_to return:一个包含所有焦点切换选项的对象
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_xpath('//*[@id="draggable"]')
target = browser.find_element_by_xpath('//*[@id="droppable"]')
actions = ActionChains(browser) # 创建新的ActionChains
actions.drag_and_drop(source, target) # 按住源元素上的鼠标左键,然后移动到目标元素并释放鼠标按钮。
actions.perform() # 执行所有存储的操作
更多的动作链操作参考官网文档:https://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains
7. 执行JavaScript
对于某些操作,Selenium API并没有提供。比如,下拉进度条,它可以通过执行execute_script()方法来实现。
from selenium import webdriver
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
browser.get('https://www.zhihu.com/explore')
browser.execute_script("window.scrollTo(0, document.body.scrollHeight)")
browser.execute_script('alert("To bottom")')
8. 获取节点信息
Selenium内部提供了提取节点信息的方法,比如属性、文本等。而无需通过解析源代码来提取信息
- 获取属性
使用get_attribute()方法来获取节点属性
from selenium import webdriver
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
browser.get('https://www.zhihu.com/explore')
logo = browser.find_element_by_xpath("//*[@class='AppHeader-inner css-qqgmyv']")
print(logo) # output:<selenium.webdriver.remote.webelement.WebElement (session="642919cb27ccfc133f5cdf22268c53d3", element="2393fb26-5896-43da-bb07-d6ef8bf5f844")>
print(logo.get_attribute('class')) # output:AppHeader-inner css-qqgmyv
- 获取文本值
每个WebElement节点都有text属性,直接调用这个属性即可获取节点内部的文本信息
相当于Beautiful Soup的get_text()方法、Pyquery的text()方法
from selenium import webdriver
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
browser.get('https://www.zhihu.com/explore')
input = browser.find_element_by_xpath("//*[@class='ExploreColumnCard-title']")
print(input.text)
- 获取id、位置、标签名和大小
from selenium import webdriver
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
browser.get('https://www.zhihu.com/explore')
input = browser.find_element_by_xpath("//*[@class='ExploreColumnCard-title']")
print(input.id) #获取节点id
print(input.location) # 获取该节点在页面中的相对位置
print(input.tag_name) # 获取标签名称
print(input.size) # 获取节点的大小,也就是宽高
9. 切换frame
Selenium打开页面后,它默认是在父级Frame里面操作,而此时如果页面中还有子Frame,它是不能获取到子Frame里面的节点的,需要使用switch_to.frame()方法来切换frame
from selenium.common.exceptions import NoSuchElementException
from selenium import webdriver
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
url = 'https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame(browser.find_element_by_tag_name('iframe')) # 找到子frame
try:
logo = browser.find_element_by_class_name('logo')
except NoSuchElementException:
print('No logo')
browser.switch_to.parent_frame() # 切换父级frame
logo = browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)
10. 延时等待
在Selenium中,get()方法会在网页框架加载结束后结束执行,此时如果获取page_source,可能并不是浏览器完全加载完成的页面,如某些页面有额外的Ajax请求,在网页源代码中也不定能成功获取到。所以,需要延时等待一定时间,确保节点已经加载出来。
- 隐式等待
有点像全局等待,换句话说,selenium执行完,其DOM没有加载完节点,如果设置了等待时间,则继续等待一段时间再查找DOM,否则抛出找不到节点的异常,默认的时间是0。
implicitly_wait()方法实现了隐式等待。
from selenium import webdriver
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
browser.implicitly_wait(10)
browser.get('https://www.163.com')
input = browser.find_element_by_class_name('channel_ad_2016')
print(input)
- 显式等待
显式等待则指定了要查找的节点,然后指定一个等待时间,如果在规定时间内加载出来这个节点,就返回查找的节点,否则抛出超时异常
引入WebDriverWait对象,指定最长等待时间,然后调用它的until()方法,传入等待条件expected_condition(预期条件),比如下面的例子传入的是presence_of_element_located这个条件,其参数的节点的定位元组 ,也就是class=channel_ad_2016的节点
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
browser.get('https://www.163.com')
wait = WebDriverWait(browser, 5) #
# presence_of_element_located()方法是节点出现
input = wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'channel_ad_2016')))
# element_to_be_clickable()方法是可点击
button = wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'hp_textlink1_nav_l')))
# 标题是某内容
title = wait.until(EC.title_is(('网易')))
# 某个节点文本包含某文字
text_to = wait.until(EC.text_to_be_present_in_element((By.TAG_NAME, 'h1'), '网易'))
print(input, button, title)
print(text_to)
关于等待条件,其实有很多,下面列出了所有的等待条件
| 等待条件 | 含义 |
|---|---|
| title_is | 标题是某内容 |
| title_contains | 标题包含某内容 |
| presence_of_element_located | 节点加载出来,传入定位元组,如(By.ID, 'p') |
| visibility_of_element_located | 节点可见,传入定位元组 |
| visibility_of | 可见,传入节点对象 |
| presence_of_all_elements_located | 所有节点加载出来 |
| text_to_be_present_in_element | 某个节点文本包含某文字,包含则返回True |
| text_to_be_present_in_element_value | 某个节点值包含某文字 |
| frame_to_be_available_and_switch_to_it | 加载并切换 |
| invisibility_of_element_located | 节点不可见 |
| element_to_be_clickable | 节点可点击 |
| staleness_of | 判断一个节点是否存在DOM,可判断页面是否已经刷新 |
| element_to_be_selected | 节点可选择,传节点对象 |
| element_locatd_to_be_selected | 节点可选择,传节点对象 |
| element_selection_state_to_be | 传入节点对象以及状态 ,相等返回True,否则返回False |
| element_located_selection_state_to_be | 传入定位元组以及状态,相等返回True,否则返回False |
| alert_is_present | 是否出现警告 |
更多的等待条件的参数及用法,参考文档:https://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions
11. 前进和后退
使用back()方法后退,forward()方法前进
import time
from selenium import webdriver
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
browser.get('https://www.163.com')
browser.get('https://www.qq.com')
browser.get('https://www.baidu.com')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
12. Cookies
对Cookies进行一些操作,比如获取、添加、删除等
from selenium import webdriver
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
browser.get('https://www.163.com')
print(browser.get_cookies())
# 获取cookie, output:[{'domain': '.163.com', 'expiry': 4778559675, 'httpOnly': False, 'name': '_ntes_nnid', 'path': '/', 'secure': False, 'value': '29d1c351b6648b7e75e1ea5e2f140526,1624959675407'}, {'domain': '.www.163.com', 'expiry': 1624959915, 'httpOnly': False, 'name': 'W_USERIP', 'path': '/', 'secure': False, 'value': '%E5%B9%BF%E5%B7%9E%7C%E5%B9%BF%E4%B8%9C'}, {'domain': '.www.163.com', 'expiry': 1625046075, 'httpOnly': False, 'name': 'W_HPTEXTLINK', 'path': '/', 'secure': False, 'value': 'old'}, {'domain': '.www.163.com', 'httpOnly': False, 'name': '_antanalysis_s_id', 'path': '/', 'secure': False, 'value': '1624959674562'}, {'domain': '.163.com', 'httpOnly': False, 'name': '_ntes_nuid', 'path': '/', 'secure': False, 'value': 'bccd69b6351d9993c9a4202c0e775873'}]
browser.add_cookie({'name': 'zhangsan', 'domain': 'www.163.com', 'value': 'test'}) # 添加cookie
print(browser.get_cookies())
# output:[{'domain': '.163.com', 'expiry': 4778559675, 'httpOnly': False, 'name': '_ntes_nnid', 'path': '/', 'secure': False, 'value': '29d1c351b6648b7e75e1ea5e2f140526,1624959675407'}, {'domain': '.www.163.com', 'httpOnly': False, 'name': 'zhangsan', 'path': '/', 'secure': True, 'value': 'test'}, {'domain': '.www.163.com', 'expiry': 1624959915, 'httpOnly': False, 'name': 'W_USERIP', 'path': '/', 'secure': False, 'value': '%E5%B9%BF%E5%B7%9E%7C%E5%B9%BF%E4%B8%9C'}, {'domain': '.www.163.com', 'expiry': 1625046075, 'httpOnly': False, 'name': 'W_HPTEXTLINK', 'path': '/', 'secure': False, 'value': 'old'}, {'domain': '.www.163.com', 'httpOnly': False, 'name': '_antanalysis_s_id', 'path': '/', 'secure': False, 'value': '1624959674562'}, {'domain': '.163.com', 'httpOnly': False, 'name': '_ntes_nuid', 'path': '/', 'secure': False, 'value': 'bccd69b6351d9993c9a4202c0e775873'}]
browser.delete_all_cookies() # 删除cookie
print(browser.get_cookies())
# output:[]
13. 选项卡管理
访问网页的时候,会开启一个个选项卡,在selenium中,也可以对选项卡进行操作。
import time
from selenium import webdriver
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
browser.get('https://www.163.com')
browser.execute_script('window.open()') # 使用js新开启一个选项卡
print(browser.window_handles) # 获取当前开启的所有选项卡
browser.switch_to.window(browser.window_handles[1]) # 跳转到第二个选项卡
browser.get('https://www.qq.com')
time.sleep(1)
browser.switch_to.window(browser.window_handles[0]) # 跳转到第一个选项卡
browser.get('https://python.org')
14. 异常处理
在selenium的过程中,难免会遇到一些异常,例如超时、节点未找到等错误,一旦出现此类错误,程序便不会继续运行了。这里我们可以使用try except语句来捕获各种异常。
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementException
browser = webdriver.Chrome(r'D:\tools\chromedriver.exe')
try:
browser.get('https://www.163.com')
except TimeoutException: #超时
print('Time out')
try:
browser.find_element_by_id('test')
except NoSuchElementException: #节点未找到
print('No element')
finally:
browser.close()
# output: No element
更多的异常类,参考官网文档:https://selenium-python.readthedocs.io/api.html#module-selenium.common.exceptions
15. Options
初始化
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--window-size=1920,1080") # 屏幕大小
prefs = {"profile.managed_default_content_settings.images": 2} # 不显示图片提高代码速度
options.add_experimental_option("prefs", prefs)
options.add_experimental_option('excludeSwitches', ['enable-automation'])# 规避检测
#设置编码格式
options.add_argument('lang=zh_CN.UTF-8')
# 模拟设备
options.add_argument('--user-agent="MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"')
# 设置Chrome为隐身模式(无痕模式)
options.add_argument('--incognito')
# 设置代理
add_argument('--proxy-server=http://%s' % proxy)
建议
在练习模拟操作时,建议使用jupyter notebook(如文中开头所演示),把每一步操作尽量保存到本地内存中,方便调试
