某电商B2C商铺新用户复购预测
1.项目需求
在有⾜够商户,⼴告位在产品中安排较合理的情况下现要求⼴告收⼊较上半年⽉平均提升5%的业务需求,如何达到要求⽬标?
1.1 业务思路
拆解提升广告收入的问题
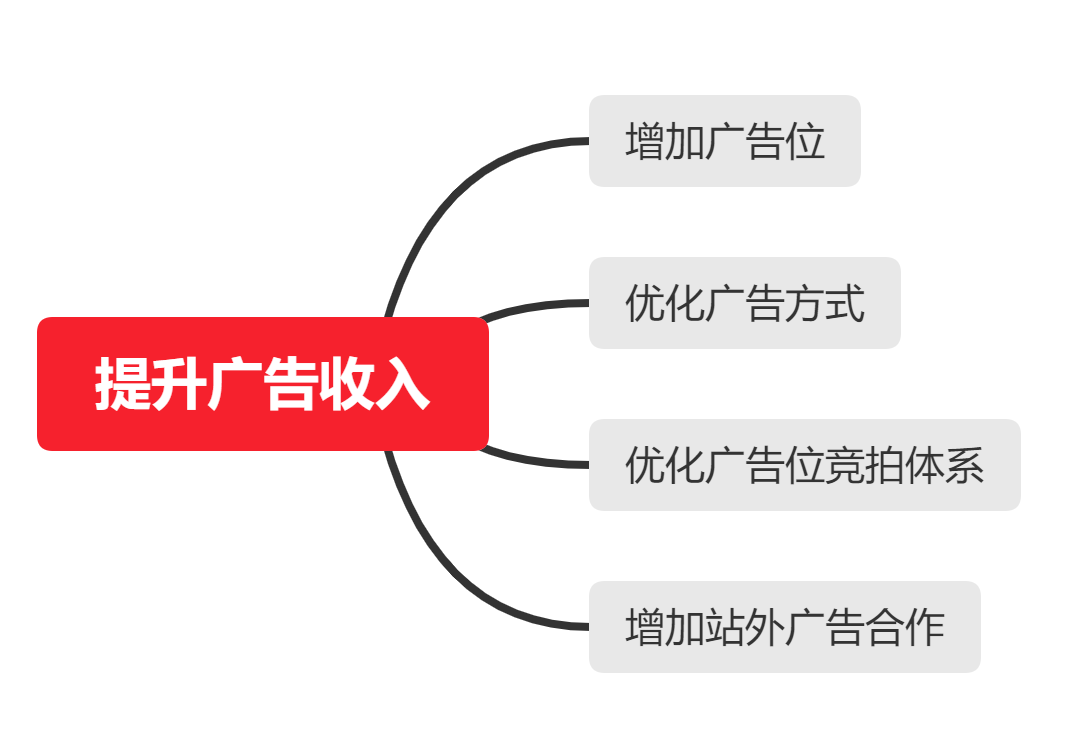
1.2 商户运营面临的困境
- 用户来了就走
- 对运营活动有依赖,有活动就来,没活动就不来
- 运营活动带不来预期效果
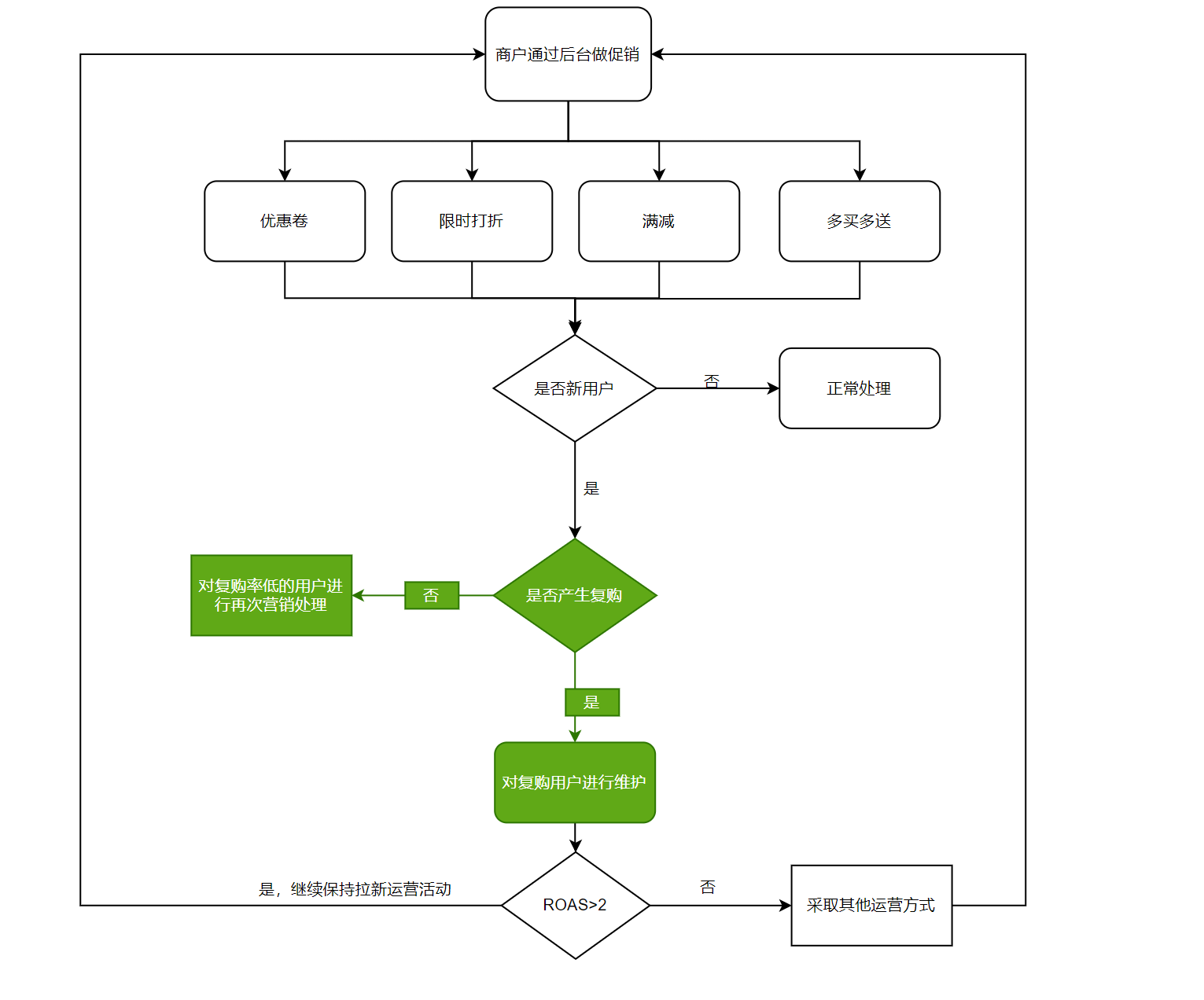
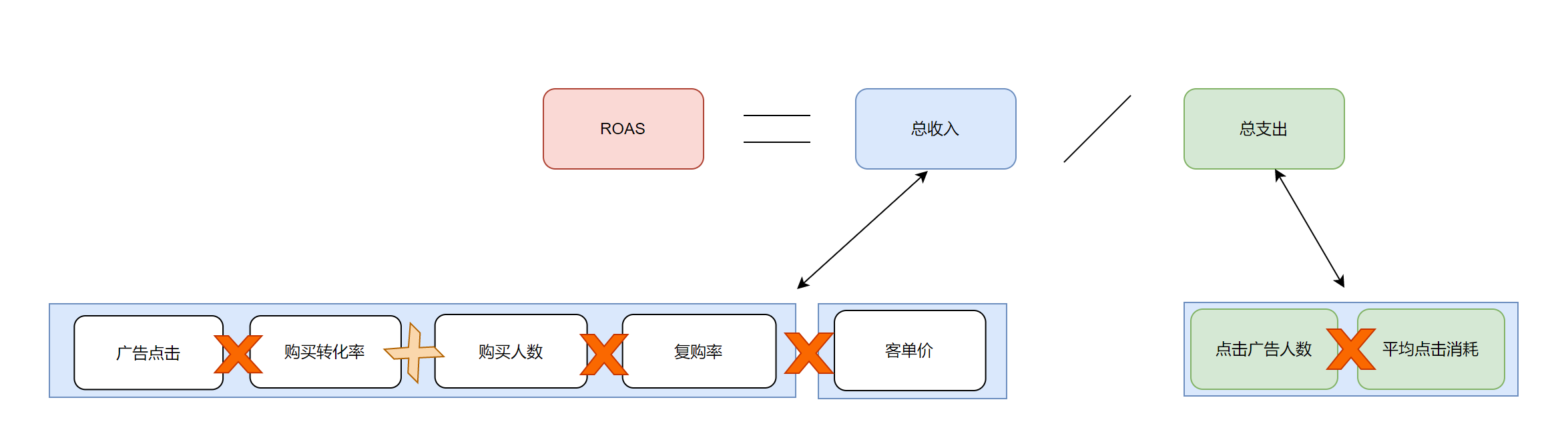
通过对新用户复购预测功能模块使用,维护好新用户,使其发挥相应的价值,从而提高ROI
1.3 解决问题流程
- 明确问题(提高广告收入)
- 拆解问题(通过稳定引流,提高商家ROAS,使商家更积极竞标广告位)
- 量化目标(本次推荐改进目标:提高5%的广告收入)
- 制定方案(方案:开发商家大促新用户的预测功能)
- 目标评估(对比之前是否收入提升5%以上)
- 实验(可行则逐渐全面推广)
- 分析实验结果(以之前购买广告位商家的10%,20%推全并逐步观测结果)
- 结案报告(如达成目标)
1.4 目标
商业目标:提高广告收入,新功能作为预测新用户复购情况,提升用户价值,从而促使更多的商家购买广告
挖掘目标:预测指定商家的新买家将来是否会成为忠实客户,即需要预测这些新买家在接下来某个时间段内再次在同一商家购买商品的概率。
2.数据挖掘
2.1 用户信息表
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
user_info = pd.read_csv(r"user_info.csv")
user_info.head()
"""
# 买家ID, 买家年龄范围,买家性别
# 其中⽤户年龄范围。<18岁为1;[18,24]为2; [25,29]为3; [30,34]为4;[35,39]为5;[40,49]为6; > = 50时为7和8; 0和NULL表示未知
user_id age_range gender
0 376517 6.0 1.0
1 234512 5.0 0.0
2 344532 5.0 0.0
3 186135 5.0 0.0
4 30230 5.0 0.0
"""
- 数据处理
# 删除缺失值(数据量足够)
user_info.dropna(axis=0,inplace=True)
user_info.duplicated().sum()
# user_info.drop_duplicates(inplace=True)
user_info.gender.value_counts()
user_info.age_range.value_counts()
# 处理字段“gender=2和NULL”,"age_range>50时为7和8"; "age_range=0和NULL";
user_info = user_info.loc[(user_info.gender != 2) & (user_info.age_range != 0),:]
user_info.age_range[user_info.age_range == 8] = 7
用户行为表经过清洗后,由原来424170(42w) 条数据量变为317840 (31万)条数据量。
2.2 用户商铺复购表
user_merchant = pd.read_csv(r"user_merchant.csv")
user_merchant.head()
"""
# 买家ID,商家ID, label包括0,1,其中1表示重复买家,0表示非重复买家
user_id merchant_id label
0 34176 3906 0
1 34176 121 0
2 34176 4356 1
3 34176 2217 0
4 230784 4818 0
"""
- 数据处理
# 查看标签比例(是否复购,也是待预测标签)
user_merchant.label.value_counts()
# 发现非复购用户数远远多于复购用户数,复购用户数占比6%(小于10%,认为出现数据不平衡问题)
#### 失衡数据处理 ####
from imblearn.under_sampling import RandomUnderSampler # 欠采样
X_resampled, y_resampled = RandomUnderSampler().fit_resample(user_merchant.loc[:,["user_id","merchant_id"]],user_merchant.label)
user_merchant = pd.concat([X_resampled,y_resampled],axis=1)
# 根据user_merchant的抽样结果(失衡数据处理),对user_info 表的数据进⾏筛选
user_info = user_info.loc[user_info.user_id.isin(user_merchant.user_id.unique()),:]
用户商铺复购表经过清洗后,原来260864(26w)条数据量变为31904(3w)条数据量。
2.3 用户行为表
user_log = pd.read_csv(r"user_log.csv")
user_log.head()
"""
#买家ID,商家ID,商品类别,店铺ID,商品品牌,时间,用户行为类别(0点击,1加入购物车,2购买,3收藏)
user_id item_id cat_id seller_id brand_id time_stamp action_type
0 328862 323294 833 2882 2661.0 829 0
1 328862 844400 1271 2882 2661.0 829 0
2 328862 575153 1271 2882 2661.0 829 0
3 328862 996875 1271 2882 2661.0 829 0
4 328862 1086186 1271 1253 1049.0 829 0
"""
- 数据处理
######### 利用用户商铺复购表失衡数据处理的结果过滤用户行为表 ########
user_log = user_log.loc[user_log.user_id.isin(user_merchant.user_id.unique()),:]
user_log = user_log.loc[user_log.seller_id.isin(user_merchant.merchant_id.unique()),:]
# 查找缺失值,以及缺失值占比
user_log.apply(lambda x:[x.isnull().sum(),x.isnull().sum()/x.size], axis=0)
#删除缺失值
user_log = user_log[user_log.brand_id.isna()==False]
用户行为表经过处理,原来54925330(5492w)条数据量变为1992348(199w)条数据量
2.4 特征提取
2.4.1 用户特征
- ⽤户交互总次数
user_features = user_log.groupby('user_id')['action_type'].count().to_frame()
user_features.head()
- ⽤户各种⾏为总次数统计(点击、加购、收藏和购买)
#透视表教程:https://zhuanlan.zhihu.com/p/31952948
# 透视是谁? --> index, 层次顺序 index = [x1, x2],先按x1分再x2分组
# 数据筛选 --> values
# 聚合函数 --> aggfunc
# 以列为分割 --> columns
user_features_2 = pd.pivot_table(user_log, index='user_id',columns='action_type', aggfunc='count',values='brand_id')
user_features_2.head()
# 合并数据(与上面的数据一起合并)
user_features = user_features.merge(user_features_2,on='user_id')
user_features.head()
# 给刚刚合并好的数据重命名(列)
user_features.columns =["total_log","click","add_car","buy","collect"]
user_features.head()
- ⽤户交互了多少商铺数,多少种商品,多少商品类别和多少商品品牌数量
user_feautures_2 = user_log.groupby("user_id")["seller_id","item_id","cat_id","brand_id"].nunique()
user_feautures_2.head()
#### unique 以numpy.ndarray格式返回特征唯一值
#### nunique 返回对象唯一特征的数目
# 给刚刚合并好的数据重命名(列)
user_feautures_2.columns = ["seller_count","item_count","cat_count","brand_count"]
user_feautures_2.head()
# 合并数据(与上面的数据一起合并)
user_features = user_features.merge(user_features_2, on='user_id')
user_features.head()
增加时间月和日两列(拆分原有的time_stamp字段)
# 比如time_stamp=1107,拆分 月=11,日=07
user_log['month'] = user_log.time_stamp // 100
user_log['day'] = user_log.time_stamp % 100
- ⽤户平均每天交互、购买的次数 ,⽤户平均每⽉交互、购买的次数
user_features_2 = user_log.groupby('user_id')['month','time_stamp'].nunique()
user_features_2.columns = ["month_count","day_count"]
user_features_2.head()
user_features = user_features.merge(user_features_2,on="user_id")
user_features.head()
# 求平均
user_features['day_avg_log'] = user_features.total_log/user_features.day_count
user_features['day_avg_buy'] = np.where(user_features.buy.isna(),0,user_features.buy/user_features.day_count)
user_features['month_avg_log'] = user_features.total_log/user_features.month_count
user_features['month_avg_buy'] = np.where(user_features.buy.isna(),0,user_features.buy/user_features.month_count)
user_features.head()
## where解读:cond=x.isna()为na时,等于0,否则直接后面的条件
2.4.2 商铺特征
- 商铺下所有交互总次数
shop_feature = user_log.groupby('seller_id')['user_id'].count().to_frame()
shop_feature.columns=['total_count']
shop_feature.head()
- 商铺下各种⾏为总次数统计(点击、加购、收藏和购买)
shop_feature_2 = pd.pivot_table(user_log, index='seller_id', columns='action_type', aggfunc='count', values='user_id')
shop_feature_2.columns=["click","add_car","buy","collect"]
shop_feature = shop_feature.merge(shop_feature_2, on='seller_id')
shop_feature.head()
- 商铺下交互的总⽤户数,多少被交互的商品,商品类别和商品品牌数量
shop_feature_2 = user_log.groupby("seller_id")["user_id","item_id","cat_id","brand_id"].nunique()
shop_feature_2.columns = ["user_count","item_count","cat_count","brand_count"]
shop_feature = shop_feature.merge(shop_feature_2, on='seller_id')
shop_feature.head()
- 商铺⽉平均有多少⽤户交互
shop_feature_2 = user_log.groupby('seller_id')['month'].nunique()
shop_feature = shop_feature.merge(shop_feature_2, on='seller_id')
shop_feature.head()
shop_feature['month_avg_user'] = shop_feature.user_count/shop_feature.month
shop_feature.head()
- 获取用户详细信息(两表关联)
user_log = user_log.merge(user_info,on="user_id")
user_log.head()
- 商铺下交互的⽤户按年龄段和性别分别统计
# 按年龄段
shop_feature_2 = pd.pivot_table(user_log, index='seller_id',values='user_id', columns='age_range', aggfunc='nunique')
shop_feature_2.columns=["less18","between18and24","between25and29","between30and34","between35and39","between40and49","grate50"]
shop_feature_2.head()
shop_feature= shop_feature.merge(shop_feature_2,on="seller_id")
shop_feature.head()
# 按性别
shop_feature_2 = pd.pivot_table(user_log,index="seller_id",columns="gender",values="user_id",aggfunc="nunique")
shop_feature_2.head()
shop_feature_2.columns=["gender_F","gender_M"]
shop_feature= shop_feature.merge(shop_feature_2,on="seller_id")
shop_feature.head()
- 合并用户和商铺特征到--用户行为复购表
user_features = user_features.reset_index()
user_merchant = user_merchant.merge(user_features, on='user_id', how='left')
shop_feature = shop_feature.reset_index()
user_merchant = user_merchant.merge(shop_feature, left_on='merchant_id', right_on='seller_id', how='left')
2.4.3 用户商铺交叉特征
- ⽤户在某商铺中交互的次数
user_shop_feature = user_log.groupby(['seller_id','user_id'])['item_id'].count()
user_shop_feature = user_shop_feature.reset_index()
user_shop_feature.columns= ["seller_id","user_id","us_total"]
user_shop_feature.head()
- ⽤户在某商铺中各种⾏为次数(点击、加购、收藏和购买)
user_shop_feature_2 = pd.pivot_table(user_log, index=['seller_id', 'user_id'], columns='action_type', values='cat_id', aggfunc='count')
user_shop_feature_2 = user_shop_feature_2.reset_index()
user_shop_feature_2.columns = ["seller_id","user_id","us_click","us_add_car","us_buy","us_collect"]
user_shop_feature_2.head()
# 与前面数据一起合并
user_shop_feature = user_shop_feature.merge(user_shop_feature_2, on=['seller_id','user_id'])
user_shop_feature.head()
- ⽤户在商铺中⽉的平均交互次数
# 月交互次数
user_shop_feature_2 = user_log.groupby(['seller_id', 'user_id'])['month'].nunique()
user_shop_feature_2 = user_shop_feature_2.reset_index()
user_shop_feature_2.columns =["seller_id","user_id","us_month"]
user_shop_feature_2.head()
# 合并月交互次数到用户商铺特征表
user_shop_feature = user_shop_feature.merge(user_shop_feature_2, on=['seller_id','user_id'])
user_shop_feature.head()
# ⽤户在商铺中平均月交互次数
user_shop_feature['us_month_avg_total'] = user_shop_feature.us_total/user_shop_feature.us_month
- ⽤户在商铺中⽉平均的各种⾏为次数(点击、加购、收藏和购买)
user_shop_feature['us_month_avg_click'] = user_shop_feature.us_click/user_shop_feature.us_month
user_shop_feature['us_month_avg_addcar'] = np.where(user_shop_feature.us_add_car.isnull(),0,user_shop_feature.us_click/user_shop_feature.us_month)
user_shop_feature['us_month_avg_collect'] = np.where(user_shop_feature.us_buy.isnull(),0,user_shop_feature.us_buy/user_shop_feature.us_month)
user_shop_feature['us_month_avg_buy'] = np.where(user_shop_feature.us_buy.isnull(),0,user_shop_feature.us_buy/user_shop_feature.us_month)
user_shop_feature.head()
- ⽤户在商铺中第⼀次和最后⼀次交互的时间差
# 使用分组聚合grouyby().agg()
user_shop_feature_2 = user_log.groupby(['seller_id', 'user_id'])['time_stamp'].agg(['min', 'max'])
user_shop_feature_2 = user_shop_feature_2.reset_index()
user_shop_feature_2.columns=["seller_id","user_id","us_min","us_max"]
user_shop_feature_2.head()
# 求差
user_shop_feature_2['diff'] = user_shop_feature_2.us_max - user_shop_feature_2.us_min
user_shop_feature_2.head()
# 合并
user_shop_feature_2 = user_shop_feature_2.loc[:,["seller_id","user_id",'diff']]## 过滤掉刚刚用的不必要字段
user_shop_feature = user_shop_feature.merge(user_shop_feature_2,on=["seller_id","user_id"])
user_shop_feature.head()
- ⽤户在商铺中交互有⼏个⽉
user_shop_feature_2 = user_log.groupby(['seller_id', 'user_id'])['month'].nunique()
user_shop_feature_2 = user_shop_feature_2.reset_index()
user_shop_feature_2.columns = ["seller_id","user_id","us_month"]
user_shop_feature = user_shop_feature.merge(user_shop_feature_2, on=['seller_id', 'user_id'])
user_shop_feature.head()
- ⽤户在商铺中交互有多少天
user_shop_feature_2 = user_log.groupby(['seller_id', 'user_id'])['time_stamp'].nunique()
user_shop_feature_2 = user_shop_feature_2.reset_index()
user_shop_feature_2.columns = ["seller_id","user_id","us_days"]
user_shop_feature = user_shop_feature.merge(user_shop_feature_2, on=['seller_id', 'user_id'])
user_shop_feature.head()
- ⽤户在商铺中交互的商品、商品类别和商品品牌的总个数
user_shop_feature_2 = user_log.groupby(['seller_id', 'user_id'])["item_id","cat_id",'brand_id'].nunique()
user_shop_feature_2 = user_shop_feature_2.reset_index()
user_shop_feature_2.columns=["seller_id","user_id","us_item_count","us_cat_count","us_brand_count"]
user_shop_feature = user_shop_feature.merge(user_shop_feature_2, on=['seller_id', 'user_id'])
user_shop_feature.head()
- 合并用户-商铺特征(user_shop_feature)数据框到user_merchant表
user_merchant = user_merchant.merge(user_shop_feature, left_on=["merchant_id","user_id"], right_on=["seller_id","user_id"])
user_merchant.head()
2.4.4 比值特征提取
- ⽤户交互次数在所有⽤户交互总次数的占⽐
all_user_log = user_log.shape[0]
user_merchant["user_total_log_p"] = user_merchant.total_log/all_user_log
user_merchant.head()
- ⽤户购买次数在所有⽤户购买总次数的占⽐
all_user_log_buy = (user_log.action_type == 2).sum()
user_merchant['user_total_buy_p'] = user_merchant.buy_x/all_user_log_buy
user_merchant.head()
- 商铺交互次数在所有商铺交互总次数的占⽐
user_merchant['shop_total_log_p'] = user_merchant.total_count/all_user_log
- 商铺购买次数在所有商铺购买总次数的占⽐
user_merchant["shop_total_buy_p"] = user_merchant.buy_y/all_user_log_buy
- 商铺中购买的⽤户数在所有商铺购买⽤户数的占⽐
# 购买用户数
shop_feat = user_log.loc[user_log.action_type==2].groupby("seller_id")["user_id"].nunique()
shop_feat = shop_feat.reset_index()
shop_feat.columns = ["seller_id","Shop_buy_users"]
shop_feat.head()
## 合并
user_merchant = user_merchant.merge(shop_feat, left_on='seller_id_y', right_on = 'seller_id')
user_merchant.head()
# 所有店铺购买用户数
all_buy_user_count = user_log.user_id[user_log.action_type==2].nunique()
# 商铺中购买的⽤户数在所有商铺购买⽤户数的占⽐
user_merchant["shop_buyuser_totalbuyuser_p"] = user_merchant.Shop_buy_users/all_buy_user_count
user_merchant.head()
- ⽤户在某商铺的交互次数在该⽤户所有交互次数的占⽐
user_merchant["us_user_log_p"] = user_merchant.us_total/user_merchant.total_log
- ⽤户在某商铺的购买次数在该⽤户所有购买次数的占⽐
user_merchant["us_user_buy_p"] = user_merchant.us_buy/user_merchant.buy_x
- ⽤户在某商铺的交互次数在该商铺所有交互次数中的占⽐
user_merchant["us_shop_log_p"] = user_merchant.us_total/user_merchant.total_count
- ⽤户在某商铺的购买次数在该商铺所有购买次数中的占⽐
user_merchant["us_shop_buy_p"] = user_merchant.us_buy/user_merchant.buy_y
- 商铺中回购(购买次数>1)的⽤户数占总回购⽤户数的⽐例
user_log["uid_day"] = user_log.user_id.astype("str") +"_"+ user_log.time_stamp.astype("str")
# 假设认为一天为一个订单(加上unique)
temp = user_log.uid_day[user_log.action_type==2].unique()
# 总回购用户数
buy_double_user = (pd.Series(map(lambda x:x.split("_")[0],temp)).value_counts()>1).sum()
#定义函数获得指定店铺的回购用户数(返回店铺id和店铺回购用户数)
def get_shop_double(shop_id):
temp = user_log.uid_day[(user_log.action_type==2) & (user_log.seller_id == shop_id)].unique()#店铺购买用户
buy_double_user = (pd.Series(map(lambda x:x.split("_")[0],temp)).value_counts()>1).sum()
return [shop_id,buy_double_user]
#遍历每个店铺获得其回购用户数
temp = pd.DataFrame(map(get_shop_double,user_log.seller_id.unique()),columns=["seller_id","double_user"])
## 合并到user_merchant表
user_merchant = user_merchant.merge(temp,right_on="seller_id",left_on="merchant_id")
temp.head()
#计算比值
user_merchant["shop_doubleU_totaldoubleU_p"] = user_merchant.double_user/buy_double_user
user_merchant.head()
- 商铺中回购的总次数占商铺中⽤户总购买次数的⽐例
#获得指定店铺的回购用户比
def get_shop_double_order(shop_id):
temp = user_log.uid_day[(user_log.action_type==2) & (user_log.seller_id == shop_id)].unique()
temp = pd.Series(map(lambda x:x.split("_")[0],temp)).value_counts() # 输出Series格式: (用户id 购买次数)
total_buy = temp.sum()
double = (temp-1).sum()
return [shop_id,double/total_buy]
#测试
get_shop_double_order(3614)
#遍历每一个店铺,获得其商铺中回购的总次数占商铺中用户总购买次数的比例
temp = pd.DataFrame(map(get_shop_double_order,user_log.seller_id.unique()),columns=["merchant_id","shop_Repurchase_P"])
temp.head()
## 合并
user_merchant = user_merchant.merge(temp,on="merchant_id")
user_merchant.head()
- 商铺中回购的商品类别总数在商铺中⽤户购买商品类别总数的占⽐
def get_shop_double_cat(shop_id):
temp = user_log.cat_id[(user_log.action_type==2) & (user_log.seller_id == shop_id)].value_counts()
total_buy = temp.sum()
double = (temp-1).sum()
return [shop_id,double/total_buy]
#遍历所有商铺,获得其品类回购率
temp =pd.DataFrame(list(map(get_shop_double_cat,user_log.seller_id.unique())),columns=["merchant_id","shop_Repurchase_cat_P"])
## 合并
user_merchant = user_merchant.merge(temp,on="merchant_id")
user_merchant.head()
- ⽤户有回购的商铺数在该⽤户所有购买⾏为商铺数的占⽐
def get_shop_double_us(user_id):
temp = user_log.seller_id[(user_log.action_type==2) & (user_log.user_id == user_id)].value_counts()
total_buy = temp.size
double = (temp>1).sum()
return [user_id,double/total_buy]
#遍历所有用户,获得其有回购的商铺数在该用户所有购买行为商铺数的占比
temp=pd.DataFrame(list(map(get_shop_double_us,user_log.user_id.unique())),columns=["user_id","User_RepurchaseShop_P"])
##合并
user_merchant = user_merchant.merge(temp,on="user_id")
user_merchant.head()
- ⽤户回购次数在该⽤户所有购买总次数的占⽐
def get_User_Repurchase(user_id):
temp = user_log.uid_day[(user_log.action_type==2) & (user_log.user_id == user_id)].unique()
temp = pd.Series(map(lambda x:x.split("_")[0],temp)).value_counts()
total_buy = temp.sum()
double = (temp-1).sum()
return [user_id,double/total_buy]
#遍历所有用户 ,获得其回购次数在该用户所有购买总次数的占比
temp =pd.DataFrame(list(map(get_User_Repurchase,user_log.user_id.unique())),columns=["user_id","User_Repurchase_P"])
user_merchant = user_merchant.merge(temp,on="user_id")
user_merchant.head()
- 建模前再对数据过滤处理
#缺失值设置为0
user_merchant.fillna(0,inplace=True)
#删除不需要的列
user_merchant = user_merchant.drop(["seller_id_x","seller_id_y","user_id","merchant_id"],axis=1)
user_merchant.columns # 所有特征字段
2.5 建模及评估
import os
import time
# 模型处理模块
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
# 标准化处理模块
from sklearn.preprocessing import StandardScaler
# 常规模型
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
# 集成学习和stacking模型
from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier, RandomForestClassifier
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
from mlxtend.classifier import StackingClassifier
# 评价标准模块
from sklearn import metrics
from sklearn.metrics import accuracy_score,roc_auc_score,recall_score,precision_score,classification_report
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
# 划分数据集
X_train,X_test,y_train,y_test = train_test_split(user_merchant.iloc[:,1:],user_merchant.label,test_size=0.3,random_state=6)
# 封装模型、评估函数
def train_model(X_train, y_train, X_test, y_test,
model,model_name):
print('训练{}'.format(model_name))
clf=model
start = time.time()
clf.fit(X_train, y_train.values.ravel())
#验证模型
print('训练准确率:{:.4f}'.format(clf.score(X_train, y_train)))
predict=clf.predict(X_test)
score = clf.score(X_test, y_test)
precision=precision_score(y_test,predict)
recall=recall_score(y_test,predict)
print('测试准确率:{:.4f}'.format(score))
print('测试精确率:{:.4f}'.format(precision))
print('测试召回率:{:.4f}'.format(recall))
end = time.time()
duration = end - start
print('模型训练耗时:{:6f}s'.format(duration))
return clf, score,precision,recall, duration
# 选择最优模型
model_name_param_dict = { 'LR': (LogisticRegression(penalty ="l2")),
'DT': (DecisionTreeClassifier(max_depth=10,min_samples_split=10)),
'AdaBoost': (AdaBoostClassifier()),
'GBDT': (GradientBoostingClassifier()),
'RF': (RandomForestClassifier()),
'XGBoost':(XGBClassifier())
}
result_df = pd.DataFrame(columns=['Accuracy (%)','precision(%)','recall(%)','Time (s)'],
index=list(model_name_param_dict.keys()))
for model_name, model in model_name_param_dict.items():
clf, acc,pre,recall, mean_duration = train_model(X_train, y_train,
X_test, y_test,
model,model_name)
result_df.loc[model_name, 'Accuracy (%)'] = acc
result_df.loc[model_name, 'precision(%)'] = pre
result_df.loc[model_name, 'recall(%)'] = recall
result_df.loc[model_name, 'Time (s)'] = mean_duration
result_df.to_csv(os.path.join('model_comparison.csv'))
# 选取一两个模型效果好的模型,比如随机森林,然后使用网格搜索做参数调优
param_grid = {'n_estimators': [20, 50, 100,300], 'max_features': [10,20,30,40,50,60],"max_depth":[4,6,8,10,12],
"min_samples_split": [10,20,30,40],"min_samples_leaf": [5,10,20,30]},
model = RandomForestClassifier()
grid_search = GridSearchCV(model, param_grid, cv=5, scoring='roc_auc')
result = grid_search.fit(X_train, y_train)
result.best_params_
result.best_score_
# 利用参数调优后的模型进行预测
pre = result.predict(X_test)
print(precision_score(y_test,pre),recall_score(y_test,pre))
# 选取一两个模型效果好的模型,比如XGBoost(提升树),然后使用网格搜索做参数调优
param_grid = {'n_estimators': [20, 50, 100,300],"max_depth":[4,6,8,10,12],
"subsample": [0.3,0.5,0.6,0.7,0.8],"colsample_bytree": [0.3,0.5,0.6,0.7,0.8]},
model = XGBClassifier()
grid_search = GridSearchCV(model, param_grid, cv=3, scoring='roc_auc')
temp=grid_search.fit(X_train, y_train)
temp.best_params_
# 利用参数调优后的模型进行预测
pre = clf.predict(X_test)
print(precision_score(y_test,pre),recall_score(y_test,pre))
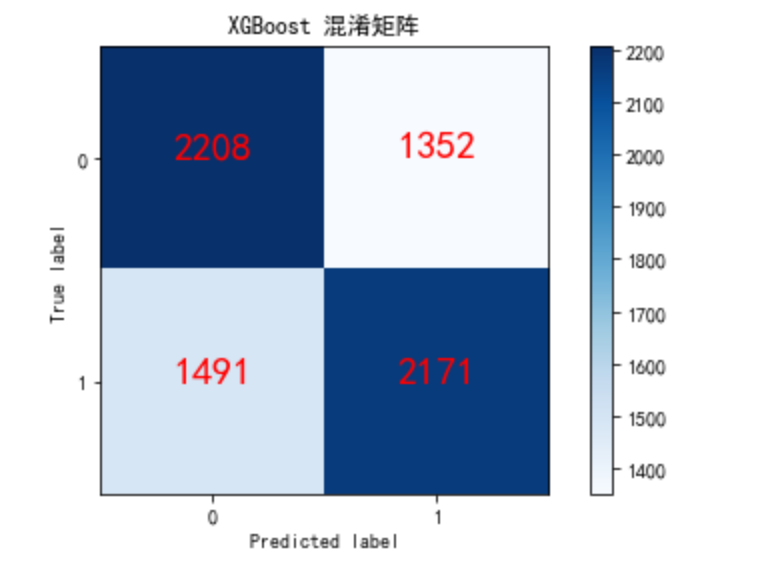
2.5.1 混淆矩阵可视化
import itertools
def plot_confusion_matrix(cm, classes, normalize = False, title = 'Confusion matrix"', cmap = plt.cm.Blues):
plt.figure()
plt.imshow(cm, interpolation = 'nearest', cmap = cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation = 0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j], horizontalalignment = 'center', color = 'red',size=20 if cm[i, j] > thresh else 'black')
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
# 真正TP、假正FP,假负FN,真负TN
def show_metrics():
tp = cm[1,1]
fn = cm[1,0]
fp = cm[0,1]
tn = cm[0,0]
print('精确率: {:.3f}'.format(tp/(tp+fp)))
print('召回率: {:.3f}'.format(tp/(tp+fn)))
print('F1值: {:.3f}'.format(2*(((tp/(tp+fp))*(tp/(tp+fn)))/((tp/(tp+fp))+(tp/(tp+fn))))))
# 显示模型评估分数
show_metrics()
"""
精确率: 0.616
召回率: 0.593
F1值: 0.604
"""
# 计算混淆矩阵,并显示
cm = confusion_matrix(y_test,pre)
class_names = [0,1]
plt.rcParams['font.sans-serif'] = ['Simhei']
# 显示混淆矩阵
c=plot_confusion_matrix(cm, classes = class_names, title = 'XGBoost 混淆矩阵')
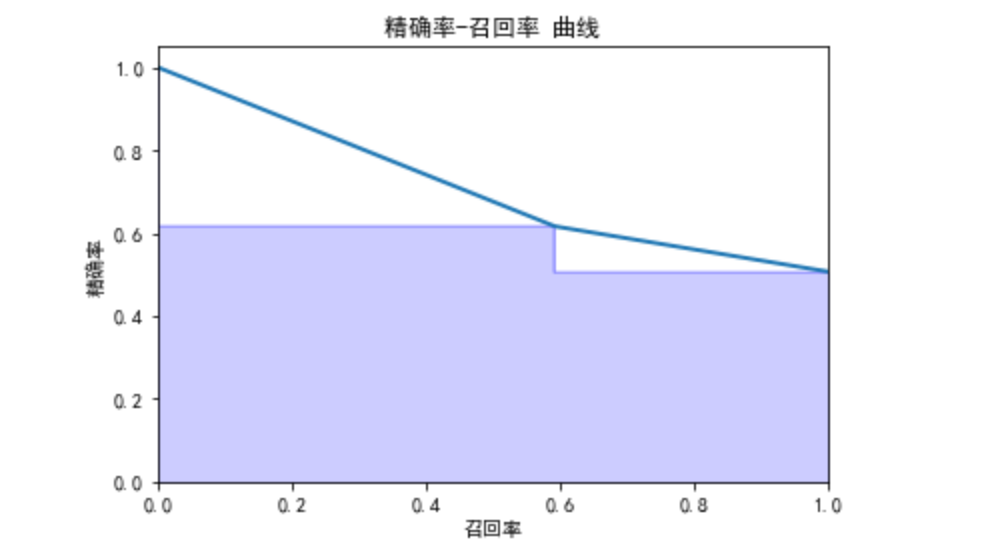
2.5.2 绘制精确率和召回率的曲线关系
# 绘制精确率-召回率曲线
def plot_precision_recall():
plt.step(recall, precision, color = 'b', alpha = 0.2, where = 'post')
plt.fill_between(recall, precision, step ='post', alpha = 0.2, color = 'b')
plt.plot(recall, precision, linewidth=2)
plt.xlim([0.0,1])
plt.ylim([0.0,1.05])
plt.xlabel('召回率')
plt.ylabel('精确率')
plt.title('精确率-召回率 曲线')
plt.show()
# 计算精确率,召回率,阈值用于可视化
precision, recall, thresholds = precision_recall_curve(y_test,pre)
plot_precision_recall()
2.6 模型保存
import joblib
#保存模型
joblib.dump(temp,'model.model') # temp模型
#加载模型
#clf=joblib.load('model.model')
提问环节
1.B2C是什么?
答:B2C 是直接⾯向消费者销售产品和服务商业零售模式
2.特征衍生是什么?一般有哪些?
答:
特征衍生是指利用现有的特征进行某种组合生成新的特征,
- 比如业务衍生:从业务意义出发,生成不同层面业务含义的新特征。
方法:逻辑关联(比如交叉特征)、增量、频率分析、比值分析
3.商业目标一般有哪些?采取什么样的措施,该怎么做?举个例子说说
答:
比如:
- 提高dau,做一些运营活动(对流失用户进行找回),挖掘目标则按规则或模型找出流失用户。
- 提高销量,做一些运营活动(用户促销、商品打折、捆绑销售),挖掘目标时,用户促销:挖掘可能购买的用户;商品打折:挖掘可能购买以及价格敏感的用户;捆绑销售:挖掘产品之间关联规则等等。
