ubuntu搭建hadoop+hive环境
步骤1:创建Hadoop用户
创建一个Hadoop用户,具体步骤如下:
-
安装openssh服务器和客户端
sudo apt install openssh-server openssh-client -y
-
创建 Hadoop 用户
sudo adduser hdoop
-
切换到新建的用户
su - hdoop
-
为hadoop用户启用无密码ssh
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
-
使用cat命令将公钥作为authorized_keys存储在ssh目录中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
-
使用以下chmod命令为用户设置权限
chmod 0600 ~/.ssh/authorized_keys
-
验证是否可用
ssh localhost
现在hdoop用户无需每次都输入密码即可使用ssh(创建hdoop用户提供给Hadoop使用)
步骤2:下载
- Hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
- Hve
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
- Java
sudo apt install openjdk-8-jdk -y
查看java版本,后面用到
java -version;javac -version
步骤3:安装Hadoop详细步骤
下载完Hadoop安装包后解压,比如我的是3.3.1版本,下文以该版本为例演示。
tar xvf hadoop-3.3.1.tar.gz
配置Hadoop环境变量
vim .bashrc
将以下内容添加到文件末尾来定义Hadoop环境变量
#Hadoop Related Options
export HADOOP_HOME=/home/hdoop/hadoop-3.3.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
执行以下命令使当前运行环境生效配置
source ~/.bashrc
编辑hadoop-env.sh文件
该文件主要配置HDFS,MapReduce和Hadoop相关的项目设置
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
把Java环境配置进来
寻找刚刚下载好java所在路径
# 方法一,使用find命令查找
find / -name java*
# 方法二,先使用which定位Java路径,然后根据输出的Java的路径,再使用readlink命令,具体如下
which javac # --> 比如这里输出Java路径:/usr/bin/javac
readlink -f /usr/bin/javac # --> 最终输出:/usr/lib/jvm/java-8-openjdk-amd64/bin/javac,截取其中部分:/usr/lib/jvm/java-8-openjdk-amd64
把Java目录路径,如下的openjdk环境追加到文件中(与系统上Java安装的位置匹配)
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
编辑 core-site.xml 文件
该文件主要设置hadoop,需要指定NameNode的URL,以及Hadoop用于映射和生成临时目录
vim $HADOOP_HOME/etc/hadoop/core-site.xml
添加以下配置覆盖临时目录的默认值,添加HDFS URL替换默认的本地文件设置
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdoop/tmpdata</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
</configuration>
不要忘记创建临时目录哦
mkdir tmpdata
编辑 hdfs-site.xml 文件
该文件主要设置存储节点的元数据、fsimage文件和编辑日志文件的位置。
通过定义NameNode和DataNode存储目录来配置文件
vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
编辑 mapred-site.xml 文件
该文件主要定义MapReduce的值
vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
添加以下配置将默认MapReduce框架名称值更改为yarn
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
编辑 yarn-site.xml 文件
该文件用于定义相关设置yarn,它包含Node Manager、Resource Manager、Containers 和 Application Master 的配置
添加以下配置到文件中
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>ubuntu</value>
</property>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
格式化 HDFS NameNode
第一次启动Hadoop服务之前格式化NameNode:
hdfs namenode -format
启动 Hadoop 集群
切换目录
cd hadoop-3.3.1/sbin/
执行以下命令启动NameNode 和 DataNode
start-dfs.sh
# 停止
stop-dfs.sh
启动 YARN 资源和节点管理器
start-yarn.sh
# 停止
stop-yarn.sh
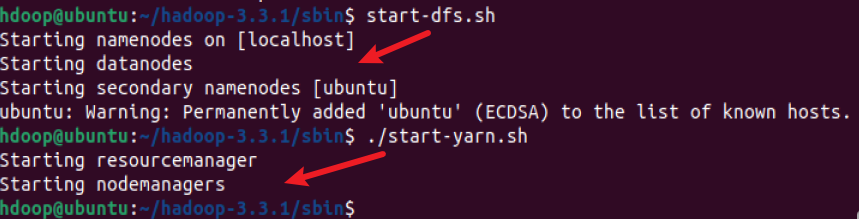
当然你也可以一步到位
start-all.sh
# 停止
# stop-all.sh
输入jps检查所有守护进程是否都处于活动状态并作为 Java 进程运行
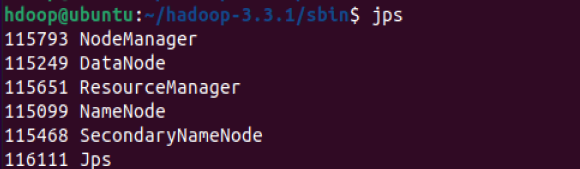
- 检查监听端口
netstat -nltup | grep java
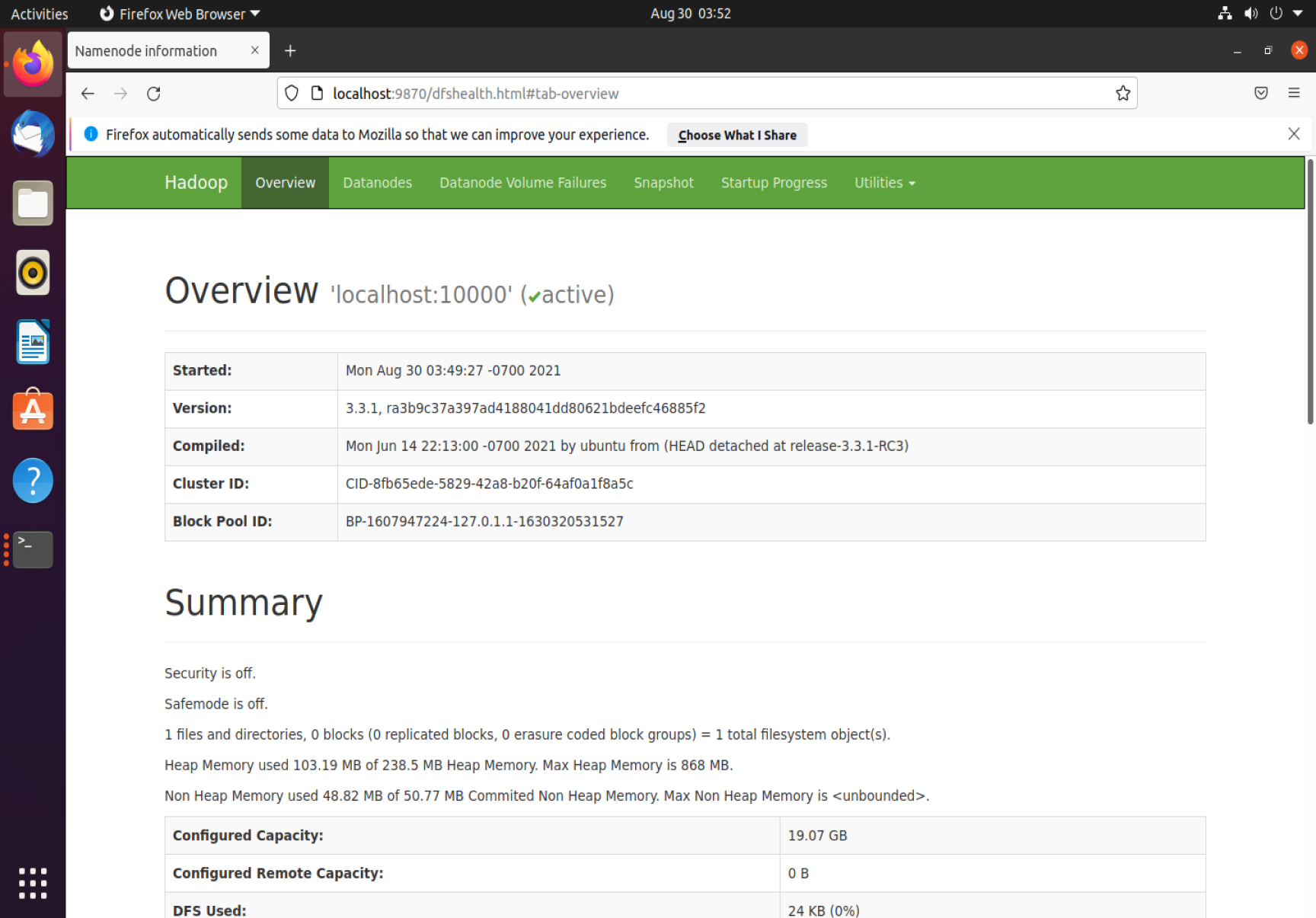
从浏览器访问Hadoop NameNode(默认端口号9870)
从浏览器访问单个 DataNode(默认端口9864)
YARN 资源管理器可在端口8088上访问
资源管理器是一个非常宝贵的工具,可让您监控 Hadoop 集群中所有正在运行的进程。
步骤4:安装Apeche Hive详细步骤
下载完成后解压
tar xzf apache-hive-3.1.2-bin.tar.gz
配置Hive环境变量
vim ~/.bashrc
添加以下Hive环境变量到.bashrc文件
export HIVE_HOME=/home/hdoop/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin
编辑 hive-config.sh 文件
该文件主要配置与Hadoop分布式文件系统交互。
vim $HIVE_HOME/bin/hive-config.sh
添加如下代码
export HADOOP_HOME=/home/hdoop/hadoop-3.3.1
在 HDFS 中创建 Hive 目录
- 创建临时tmp目录将存储Hive进程的中间结果
- 该仓库目是要存储相关单元的表(数据表)
创建tmp目录
在hdfs存储中创建一个tmp目录,该目录主要将存储hive发送hdfs的中间数据
hdfs dfs -mkdir /tmp
给tmp设置权限
hdfs dfs -chmod g+w /tmp
检查权限
hdfs dfs -ls /
创建仓库目录
在/user/hive/父目录中创建仓库目录:
hdfs dfs -mkdir -p /user/hive/warehouse
为仓库组成员添加写入和执行权限:
hdfs dfs -chmod g+w /user/hive/warehouse
# 赋予其它组内成员写入和执行权限
hdfs dfs -chmod 777 /user
检查权限
hdfs dfs -ls /user/hive
配置 hive-site.xml 文件(可选)
Apache Hive 发行版默认包含模板配置文件。模板文件位于 Hive conf目录中,并概述了默认的 Hive 设置。
hive-site.xml 文件控制 Hive 操作的各个方面。可用的高级设置的数量可能非常多且非常具体。自定义 Hive 和 Hive Metastore 设置时,请定期查阅官方 Hive 配置文档。
cd $HIVE_HOME/conf
创建hive-site.xml文件
cp hive-default.xml.template hive-site.xml
访问
vim hive-site.xml
以独立模式而不是在现实生活中的 Apache Hadoop 集群中使用 Hive 对新手来说是一个安全的选择。通过将hive.metastore.warehouse.dir参数值设置为Hive仓库目录的位置,您可以将系统配置为使用本地存储而不是 HDFS 层。
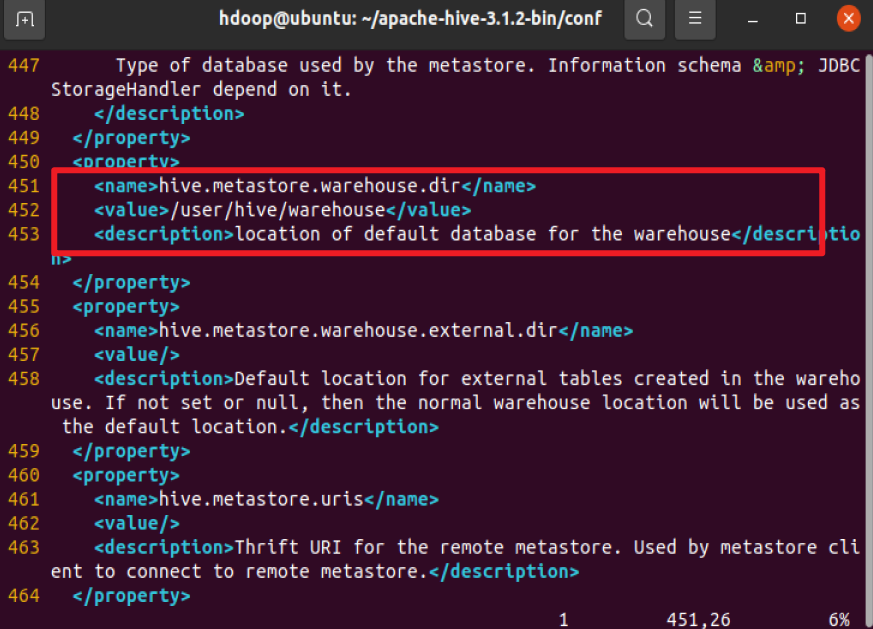
启动 Derby 数据库
Apache Hive 使用 Derby 数据库来存储元数据,Derby 是一个单线程数据库,不允许多个连接,它不适用生产环境
使用以下命令从 Hive bin目录启动 Derby 数据库schematool:
$HIVE_HOME/bin/schematool -dbType derby -initSchema
Derby 是 Hive 的默认元数据存储。
- 因为在本地模式下玩,可以删除 Metastore DB 并重新恢复它
cd $HIVE_HOME/bin
rm -rf metastore_db/
$HIVE_HOME/bin/schematool -dbType derby -initSchema
配置Mysql作为Hive MetaStore
如果不想使用Derby数据库,按照下面步骤实现Hive Metastore 到 MySQL
下载MySQL
sudo apt-get install mysql-server
下载 MySQL 连接器
下载地址:https://dev.mysql.com/downloads/connector/j/5.1.html,下载MySql连接器(connector)。
sudo dpkg -i mysql-connector-java_8.0.26-1ubuntu20.04_all.deb
查找安装连接器所在位置
find / -name mysql-connector-java*
# /usr/share/java/mysql-connector-java-8.0.26.jar
复制到$HIVE_HOME/lib目录下
cp /usr/share/java/mysql-connector-java-8.0.26.jar $HIVE_HOME/lib
创建/编辑配置文件hive-site.xml
vim $HIVE_HOME/conf/hive-site.xml
# 添加以下条目
<configuration>
<property>
<name>hive.metastore.local</name>
<value>true</value>
<description>指定本地仓库,那么对应就要仓库目录,创建目录:hdfs dfs -mkdir -p /user/hive/warehouse,在赋予权限:hdfs dfs -chmod g+w /user/hive/warehouse</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<descrition>创建指定谁来访问元数据存储,创建一个连接用户,同时需要给予它一定的权限,否则有可能造成权限不足</descrition>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
</property>
<value>hadoop</value>
<description>在MySQL中创建一个名为hadoop的用户</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
<description>用户名和密码都为hadoop</description>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>ubuntu</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
<description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description>
</property>
<property>
<name>hive.server2.thrift.http.port</name>
<value>10001</value>
<description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'http'.</description>
</property>
<property>
<name>hive.server2.thrift.client.user</name>
<value>hdoop</value>
<description>Username to use against thrift client</description>
</property>
<property>
<name>hive.server2.thrift.client.password</name>
<value>hdoop</value>
<description>Password to use against thrift client</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://ubuntu:9083</value>
<description>Thrift uri for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
</configuration>
这里默认你已经创建了一个MySQL用户名和密码一样的hadoop,否则
CREATE USER 'hadoop'@'localhost' IDENTIFIED BY 'hadoop';
GRANT ALL PRIVILEGES ON *.* TO 'hadoop'@'localhost' WITH GRANT OPTION;
flush privileges;
# 删除用户:delete from user where user = 'hadoop' and user.host = '%';
# 查看用户权限:show grants for hadoop@'%';(查询结果:GRANT USAGE ON *.* TO `hadoop`@`%` ,带有USAGE ON *.*表示该用户对任何数据库和任何表都没有权限)
# 使用 GRANT 语句创建一个新的用户 hadoop,密码为 hadoop。用户hadoop对所有的数据有查询、插入权限,并授予 GRANT 权限。
# grant select,insert,update,delete on *.* to hadoop@'localhost' identified by 'hadoop';
- 初始化Mysql
cd $HIVE_HOME/bin
rm -rf metastore_db/ # 如果前面用过Derby数据,然后改成MySQL
$HIVE_HOME/bin/schematool -dbType mysql -initSchema
- 测试Hive连接Mysql是否正常
$HIVE_HOME/bin/hive -e "create table tmp(id int);"
# 上面执行无报错,进入本地Mysql查看数据库
show databases;
# 看看是否已经生成一个名为Hive数据库,这里的数据库名在hive-site.xml自定义。
在 Ubuntu 上启动 Hive
cd $HIVE_HOME/bin # 切换到hive所在目录
hive # 启动hive
隐式测试Hive是否使用正常
hive -e "show databases"
通过HiveServer2访问Hive
#切换目录
cd $HIVE_HOME/bin
# 启动metastore
hive --service metastore
# 指定端口:hive --service metastore -p 9083
# 启动hive_service2
hive --service hiveserver2
# 后台运行metastore
nohup hive --service metastore &
# 后台运行hive_service2
nohup hive --service hiveserver2 &
#################
## 通过beeline测试
#################
# 启动beeline客户端(采用JDBC方式借助于Hive Thrift服务访问Hive数据仓库)
./apache-hive-3.1.2-bin/bin/beeline
# 启动hiveserver2
beeline> !connect jdbc:hive2://ubuntu:10000
# 显示需要输入的用户名和密码就是上面hive-site.xml中thrift client指定的Username和Password
# 出错排除日志tail -f n 200 /tmp/hdoop/hive.log (hdoop是当前用户名)
步骤5:部署Hue
部署前的准备工作
配置Python环境
hue需要使用到Python模块,为它配置一个环境变量
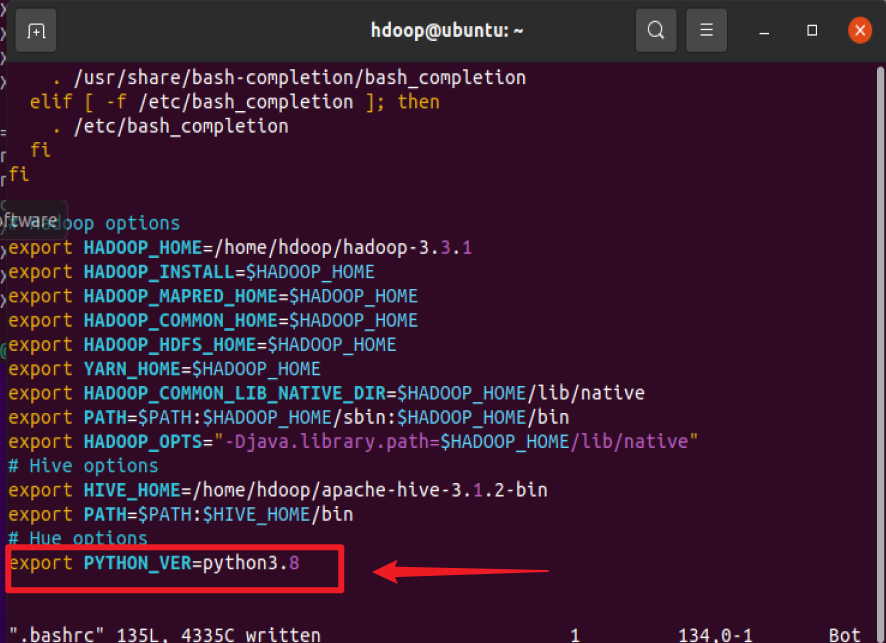
vim ~/.bashrc
添加如下代码
export PYTHON_VER=python3.8
执行生效
source ~/.bashrc
安装npm命令
sudo apt-get install npm
安装操作系统依赖包
Ubuntu系统
sudo apt-get install git ant gcc g++ libffi-dev libkrb5-dev libmysqlclient-dev libsasl2-dev libsasl2-modules-gssapi-mit libsqlite3-dev libssl-dev libxml2-dev libxslt-dev make maven libldap2-dev python-dev python-setuptools libgmp3-dev
使用 Python 3,还有:
sudo apt-get install python3.8-dev python3-distutils
下载安装Hue
- 开发版
git clone https://github.com/cloudera/hue.git
cd hue
make apps
./build/env/bin/hue runserver
- 稳定版
wget https://github.com/cloudera/hue/archive/refs/tags/release-4.10.0.tar.gz
tar zxvf release-4.10.0.tar.gz
cd release-4.10.0
make apps
./build/env/bin/hue runserver 0.0.0.0:8888
- 构建所需的表
~/hue$ ./build/env/bin/hue migrate
部署zookeeper
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0.tar.gz
tar -zxvf apache-zookeeper-3.7.0.tar.gz
cd apache-zookeeper-3.7.0/conf
cp zoo_sample.cfg zoo.cfg
cd ../bin
期间遇到的报错收集
解决办法:
sudo killall apt apt-get # 第一步
sudo rm /var/lib/apt/lists/lock # 第二步
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/lock*
sudo dpkg --configure -a # 第三步
sudo apt update # 第四步
Starting namenodes on [localhost]
ERROR: Attempting to operate on hdfs namenode as root
解决办法:添加以下代码到$HADOOP_HOME/etc/hadoop/hadoop-env.sh
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
-
这篇文章讲的很详细以及说明如何去解决
https://cwiki.apache.org/confluence/display/Hive/Hive+Schema+Tool
-
hdoop is not in the sudoers file. This incident will be reported.
-
TSocket read 0 bytes (code THRIFTTRANSPORT): TTransportException('TSocket read 0 bytes')
检查Hiveservice2服务器是否开始正常
-
初始化MySQL元存储失败
Starting metastore schema initialization to 3.1.0
Initialization script hive-schema-3.1.0.derby.sqlError: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '"APP"."NUCLEUS_ASCII" (C CHAR(1)) RETURNS INTEGER LANGUAGE JAVA PARAMETER STYLE ' at line 1 (state=42000,code=1064)
解决办法:
执行$HIVE_HOME/bin/schematool -dbType mysql -initSchema,而不是$HIVE_HOME/bin/schematool -dbType derby -initSchema -
: Call From ubuntu/127.0.1.1 to localhost:10000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
检查服务是否已启动
-
Failed to Start HiveServer2,Caused by: java.net.BindException: Permission denied (Bind failed)
访问元数据的用户无权限
-
Caused by: java.net.BindException: Address already in use (Bind failed) Caused by: org.apache.thrift.transport.TTransportException: Could not create ServerSocket on address 0.0.0.0/0.0.0.0:10000.
检查端口号是否被其它服务占用
查看进行进程正在8080端口运行的pid
lsof -i:8080
杀死监听端口的进程
taskkill -pid 431 /f
发送SIGHUP信号,可以使用一下信号
kill -HUP pid
-
浏览器打开hue显示database is locked
编辑 desktop/conf/pseudo-distributed.ini,在“[[database]]”部分添加mysql,接着./build/env/bin/hue migrate
-
Failed to access Hive warehouse: /user/hive/warehouse
回到前面的创建仓库目录,创建该目录(切换到hadoop目录所在的用户)
-
~[hadoop-common-3.3.1.jar:?]
at com.sun.proxy.$Proxy30.addBlock(Unknown Source) ~[?:?] -
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: java.io.EOFException: End of File Exception between local host is: "ubuntu/192.168.5.128"; destination host is: "localhost":10000; : java.io.EOFException; For more details see: http://wiki.apache.org/hadoop/EOFException
-
Permission denied: user=hue, access=WRITE, inode="/user/hive/warehouse":hdoop:supergroup:drwxrwxr-x
-
Concurrency mode is disabled, not creating a lock manager
-
HiveServer2-Handler-Pool: Thread-151-SendThread(ubuntu:2181)] zookeeper.ClientCnxn: Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect
-
Too many open sessions. Stop a running query before starting a new one
-
Permission denied: user=root, access=WRITE, inode="/":hdoop:supergroup:drwxr-xr-x
用户root没有权限访问hdoop用户的节点“/”,解决办法登录hdoop修改权限: hadoop fs -chmod 777 /
