K-Means - 对亚洲足球球队做聚类
1.K-Means工作原理
Kmeans算法是,以空间中指定的k个点为中心进行聚类,对最靠近它们的对象进行归类。
具体过程总结如下:
- 随机选择K个质点。(K是一个超参数,需要我们认为输入确定)
- 计算每个数据点到质心的距离,并将数据点归类到距离其最近的簇。(簇中所有数据的均值通常被称为这个簇的“质心”)
- 对每个簇重新计算其质心。(计算簇中所有点的均值并将均值作为新的质心)
- 直到簇不再发生变化或达到最大迭代次数,则结束,否则返回第二步。(max_iter最大迭代次数是一个参数)
2.优缺点
优点:
- 处理大量数据的效率高,速度快;
- 正态分布下的数据聚类效果很好;
缺点:
- 确定了K值后,需要多次随机选取初始点迭代,(否则容易陷入局部最优);
- 对异常点十分敏感
改进:
- 多设置不同的k值,比较最后数据的结果,选择最符合现实的模型参数。
3.应用场景
在实际工作中,K-Means可以应用于客户分类(营销定位);识别金融保险欺诈数据等场景中。
举例:对亚洲足球球队做聚类
- 举例:通过2015-2019 年亚洲球队的排名,对亚洲球队做聚类。在此之前,思考一下,你依靠经验来划分或者有自己的判断,你可能想到亚洲一流的球队有日本、韩国等,二流有中国队,三流有越南等,如果按照它们为分类的中心点,那么一二三流球队具体有哪些呢?
#!/usr/bin/env python
# coding: utf-8
# - 从聚类库(有9种)sklearn.cluster导入K-Means
# - 数据转换,MinMaxScaler是将特征缩放到一个范围,通常0~1之间
from sklearn.cluster import KMeans
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
import numpy as np
# 输入数据
data = [['中国', 73, 40, 7],
['日本', 60, 15, 5],
['韩国', 61, 19, 2],
['伊朗', 34, 18, 6],
['沙特', 67, 26, 10],
['伊拉克', 91, 40, 4],
['卡塔尔', 101, 40, 13],
['阿联酋', 81, 40, 6],
['乌兹别克斯坦', 88, 40, 8],
['泰国', 122, 40, 17],
['越南', 102, 50, 17],
['阿曼', 87, 50, 12],
['巴林', 116, 50, 11],
['朝鲜', 110, 50, 14],
['印尼', 164, 50, 17],
['澳洲', 40, 30, 1],
['叙利亚', 76, 40, 17],
['约旦', 118, 50, 9],
['科威特', 160, 50, 15],
['巴勒斯坦', 96, 50, 16]]
columns = ["球队", "2019年国际排名","2018世界杯","2015亚洲杯"]
data = pd.DataFrame(np.array(data), columns=columns)
X_train = data.iloc[:,1:]
kmeans = KMeans(n_clusters = 3)
# 数据规范
min_max_scaler = MinMaxScaler()
X_train_minmax = min_max_scaler.fit_transform(X_train)
# kmeans算法
kmeans.fit(X_train_minmax)
predict_y = kmeans.predict(X_train_minmax)
# 合并据类结果,插入到原数据中
predict_y = pd.DataFrame(data=predict_y,columns=['聚类'])
result = pd.concat([data, predict_y], axis=1)
sort_result = result.sort_values(by='聚类',ascending=True)
print(sort_result)
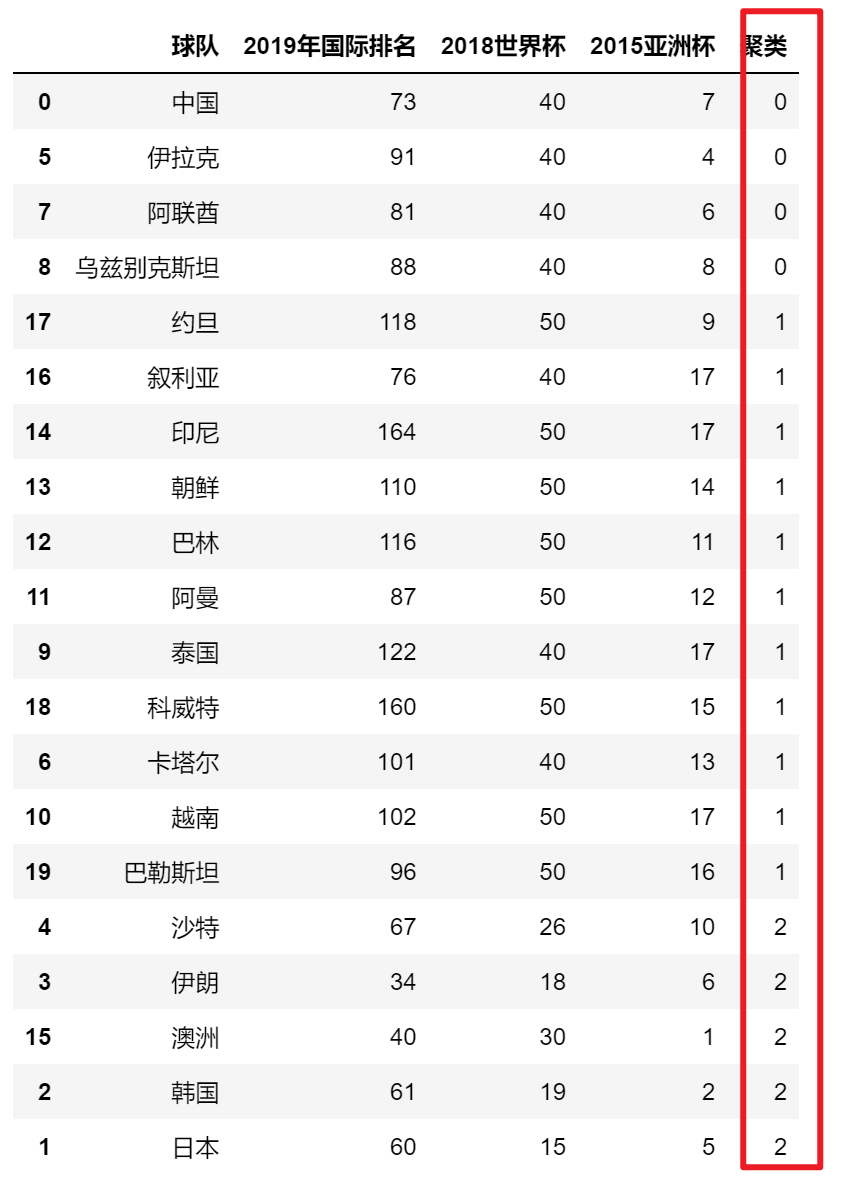
从结果看出来聚类后,日本、韩国、伊朗、沙特、澳洲分成一个类;中国、伊拉克、阿联酋、乌兹别克斯坦分成一个类;
卡塔尔、泰国、越南、阿曼、巴林、朝鲜、印尼、叙利亚、约旦、科威特和巴勒斯坦分成一个类;由此划分出亚洲几流战队都有哪些。
4.延伸提问
1. 如何选择初始点?
在K-Means算法中,初始点的选择对于最终的聚类效果有较大的影响。在选择初始点的时候,应该遵循:
-
k个初始点的距离尽可能远;
-
可以先对数据进行层次聚类,得到k个簇之后,从每个类簇中选择一个点,作为中心点。
2. 如何避免K-Means算法陷入选择质心的循环停不下来?
- 一方面,可以通过设置迭代次数加以限制;
- 另一方面,可以通过设定收敛判断距离进行限制。
3.如何确定 K 类的中心点?
- 其中包括了初始的设置,以及中间迭代过程中中心点的计算。在初始设置中,会进行 n_init 次的选择,然后选择初始中心点效果最好的为初始值。在每次分类更新后,你都需要重新确认每一类的中心点,一般采用均值的方式进行确认。
4.如何将其他点划分到 K 类中?
- 这里实际是关于距离的定义,在 K-Means 和 KNN 中,采用欧氏距离、曼哈顿距离、余弦距离等。对于点的划分,就看它离哪个类的中心点的距离最近,就属于哪一类。
5.如何区分 K-Means 和 KNN 这两种算法呢?
- K-Means是聚类算法,KNN是分类算法;
- K-Means是非监督学习,KNN是监督学习;
- K值的含义:K-Means中的代表K类,KNN中代表K个最接近的邻居
6.如何衡量聚类算法的效果?
- 轮廓系数是最常用的聚类算法的评价指标,轮廓系数范围是(-1,1):
- 轮廓系数越接近 1:样本与自己所在的簇中的样本很相似,并且与其他簇中的样本不相似。
- 轮廓系数为 0 时:两个簇中的样本相似度一致,两个簇本应该是一个簇。
- 轮廓系数为负时:样本点与簇外的样本更相似。
- 如果许多样本点具有低轮廓系数甚至负值,则聚类是不合适的,聚类的超参数 K 可能设定得太大或者太小。
相关参考:
https://time.geekbang.org/column/article/81390
https://www.nowcoder.com/tutorial/10080/ea364e74dc694595a8cfc714e80f57aa
