hive:查询语句
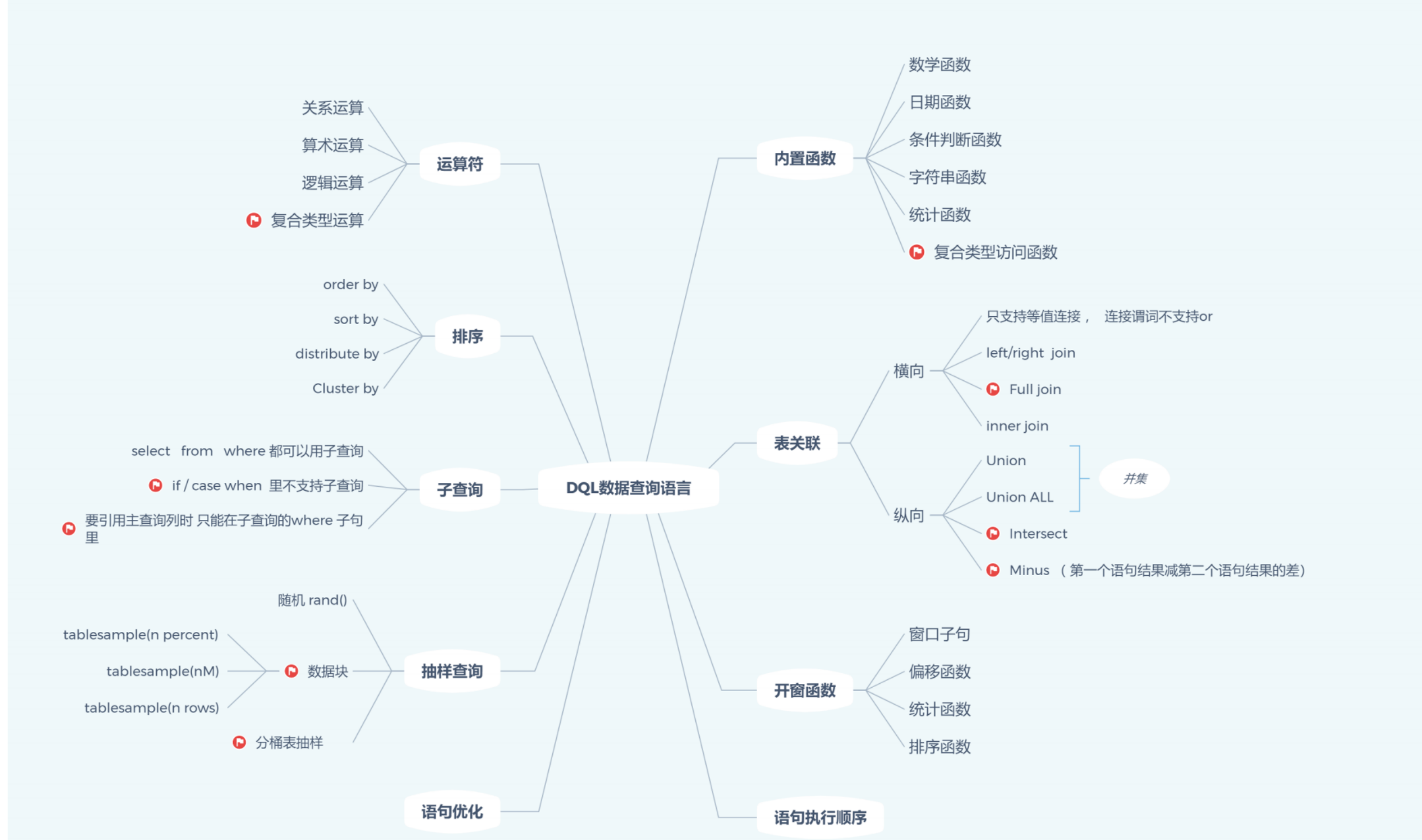
语句执行顺序
HQL语句执行顺序
from + join --> where --> select --> group by --> having --> order by --> limit
MySQL语句执行顺序
from + join --> where --> group by --> having --> select (窗口函数) --> order by --> limit
复合类型的数据查询
- 数组(array)
访问方式:列名[元素索引_以0开始]
-- 匹配最后一个名字以W开头的
select * from emp
where emp_name[1] rlike "^W"
- 字典(Map)
访问方式:列名['key']
-- 匹配出生日期是在五几年
select * from emp
where emp_date["birth_date"] between to_date("1950-1-1")
and to_date("1959-12-31")
- 结构体(Struct)
访问方式:列名.子列名
-- 性别为男的员工
select * from emp
where other_info.gender="M
正则查询

排序
| order by | sort by | distribute by | cluster by | |
|---|---|---|---|---|
| 作用 | order by会对输入做全局 排序 | 有一个Reduce,当输 入规模较大时,消耗较长 的计算时间 | 不能保证全局有 序 | 不能保证全局有 序 |
| 缺点 | 只有一个Reduce,当输 入规模较大时,消耗较长 的计算时间 | 不能保证全局有 序 | 不能保证全局有 序 | 只能做升序 |
sort by结合distribute by使用时,distribute by要放到sort by前面
表关联
- Hive join的限制
- 只支持等值连接
- 连接谓词(on)后不支持or
- Full join
Full join会将连接的两个表中的记录都保留下来
视图
- 视图是一个虚表,一个逻辑概念,可以跨越多张表。
- 表是物理概念,数据放在表中,视图是虚表, 操作视图和操作表是一样的,所谓虚,是指视图下不存数据。
- 视图是建立在已有表的基础上,视图赖以建立的这些表称为基表
- 视图也可以建立再已有的视图上
- 视图可以简化复杂的查询
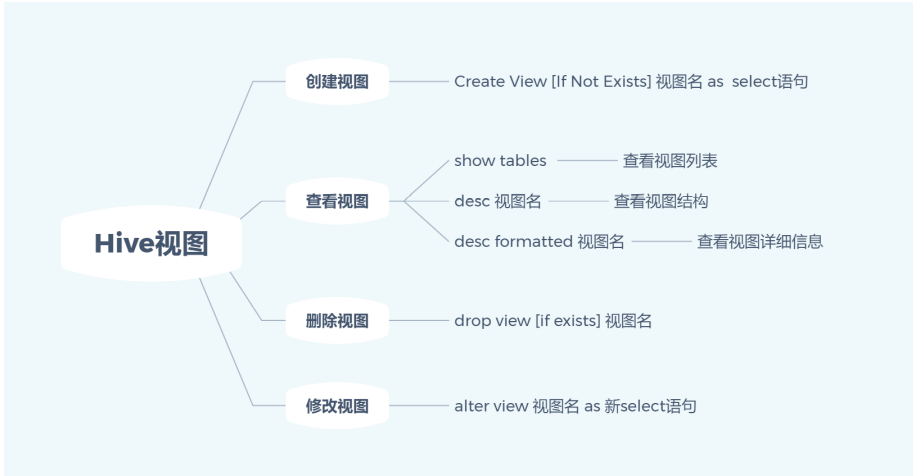
注意事项
- 视图是只读的,不能用作 LOAD / INSERT / ALTER 的目标;
- 在创建视图时候视图就已经固定,对基表的增加列操作将不会反映在视图,删除视图引用的列,视 图会失效;
- 删除基表并不会删除视图,视图失效,需要手动删除视图;
- 视图可能包含 ORDER BY 和 LIMIT 子句。如果引用视图的查询语句也包含这类子句,其执行优先 级低于视图对应子句
- 创建视图时,如果未提供列名,则将从 SELECT 语句中自动派生列名(如 SELECT 语句中包含其他 表达式,例如 x + y,则列名称将以C0,C1 等形式生成)
子查询
-
hive 3.1 支持select,from,where 子句中的子查询
-
select 子查询限制
-
不支持 if / case when 里的子查询
-
where 子查询限制 IN/NOT IN 子查询只能选择一列。
-
对父查询的引用仅在子查询的WHERE子句中支持。
-
-
集合中如果含null数据,不可使用not in, 可以使用in
开窗函数
Group by 普通聚合函数每组只有一条记录,而开窗函数则可以为窗口中的每行都返回一个值。 普通聚合函数聚合的行集是组,开窗函数聚合的行集是窗口。
语法:
分析函数(如:sum(), max(), row_number()...) + 窗口子句(over函数)
over函数(指定分析函数工作的数据窗口大小)
over([partition by [column_n] order by [column_m]])
over() 内部参数:
1. PARTITION BY col_name
2. ORDER BY col_name asc|desc
3. ROWS between 窗口子句 and 窗口子句
窗口子句
| 窗口子句 | 备注 |
|---|---|
| PRECEDING | 往前 n preceding 从当前行向前n行 |
| FOLLOWING | 往后 n following 从当前行向后n行 |
| CURRENT ROW | 当前行 |
| UNBOUNDED | 起点 |
| UNBOUNDED PRECEDING | 表示该窗口最前面的行(起点) |
| UNBOUNDED FOLLOWING | 表示该窗口最后面的行(终点) |
偏移函数
| 偏移函数 | 备注 |
|---|---|
| LAG(col,n,DEFAULT) | 用于统计窗口内往下第n行值 从当前行下移几行的值 (向前) |
| LEAD(col,n,DEFAULT) | 用于统计窗口内往上第n行值 从当前行上移几行的值 (向后) |
| first_value(col, DEFAULT) | 取分组内排序后,截止到当前行,第一个值 |
| last_value(col, DEFAULT) | 取分组内排序后,截止到当前行,最后一个值 |
统计函数
| 统计函数 | 备注 |
|---|---|
| COUNT(col) | 统计各分组内个数 |
| SUM(col) | 统计各分组内合计 |
| MIN(col) | 统计各分组内最小值 |
| MAX(col) | 统计各分组内最大值 |
| AVG(col) | 统计各分组内平均值 |
排序函数
| 排序函数 | 备注 |
|---|---|
| ROW_NUMBER() | 从1开始,按照顺序,生成分组内记录的序列 |
| RANK() | 生成数据项在分组中的排名,排名相等会在名次中留下空位 1 2 2 4 |
| DENSE_RANK() | 生成数据项在分组中的排名,排名相等在名次中不会留下空位。1223 |
| NTILE(n) | 用于将分组数据按照顺序切分成n片,返回当前切片值, 等频切片 |
抽样查询
-
目的
在大规模数据量的数据分析及建模任务中,往往针对全量数据进行挖掘分析时会十分耗时和占用集群资 源,因此一般情况下只需要抽取一小部分数据进行分析及建模操作。
- 随机抽样(rand()函数)
- 数据块抽样(tablesample()函数)
- 分桶抽样
【待学习...】
Hive调优
HQL语句调优
除去多余操作
- 减少Join操作,提示系统性能
- 尽量使用窗口函数
Distinct聚合优化
-
只有一个reduce处理全量数据,并发度不够,存在单点瓶颈
SELECT COUNT( DISTINCT userid ) FROM emp ; -
reduce就会有多个,性能提升很多
SELECT COUNT(userid ) FROM (select distinct userid from emp) as sub; -
reduce就会有多个,性能提升很多
select count(*) from ( SELECT userid FROM emp group by userid ) as sub
使用with as 代替子查询
with sub as (SELECT userid FROM emp group by userid) select count(*) from sub;
Join连接优化
-
⼩表在前,⼤表在后
Hive假定查询中最后的⼀个表是大表,它会将其它表缓存起来,然后扫描最后那个表。
-
使⽤相同的连接键
当对3个或者更多个表进⾏join连接时,如果每个on⼦句都使⽤相同的连接键的话,那么只会产⽣ ⼀个 MapReduce job。
-
尽早的过滤数据
减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使⽤到的字段。 逻辑过于复杂时,引⼊中间表
聚合技巧——利⽤窗⼝函数grouping sets、cub
【待学习...】
解决数据倾斜
【待学习...】
我是知识搬运工,把遇到喜欢的文章或对自己有用的知识保存下来。
如何把这些知识搬为已用呢?如何把这些知识提炼从而对自己产生价值?这是值得思考的一个问题。
