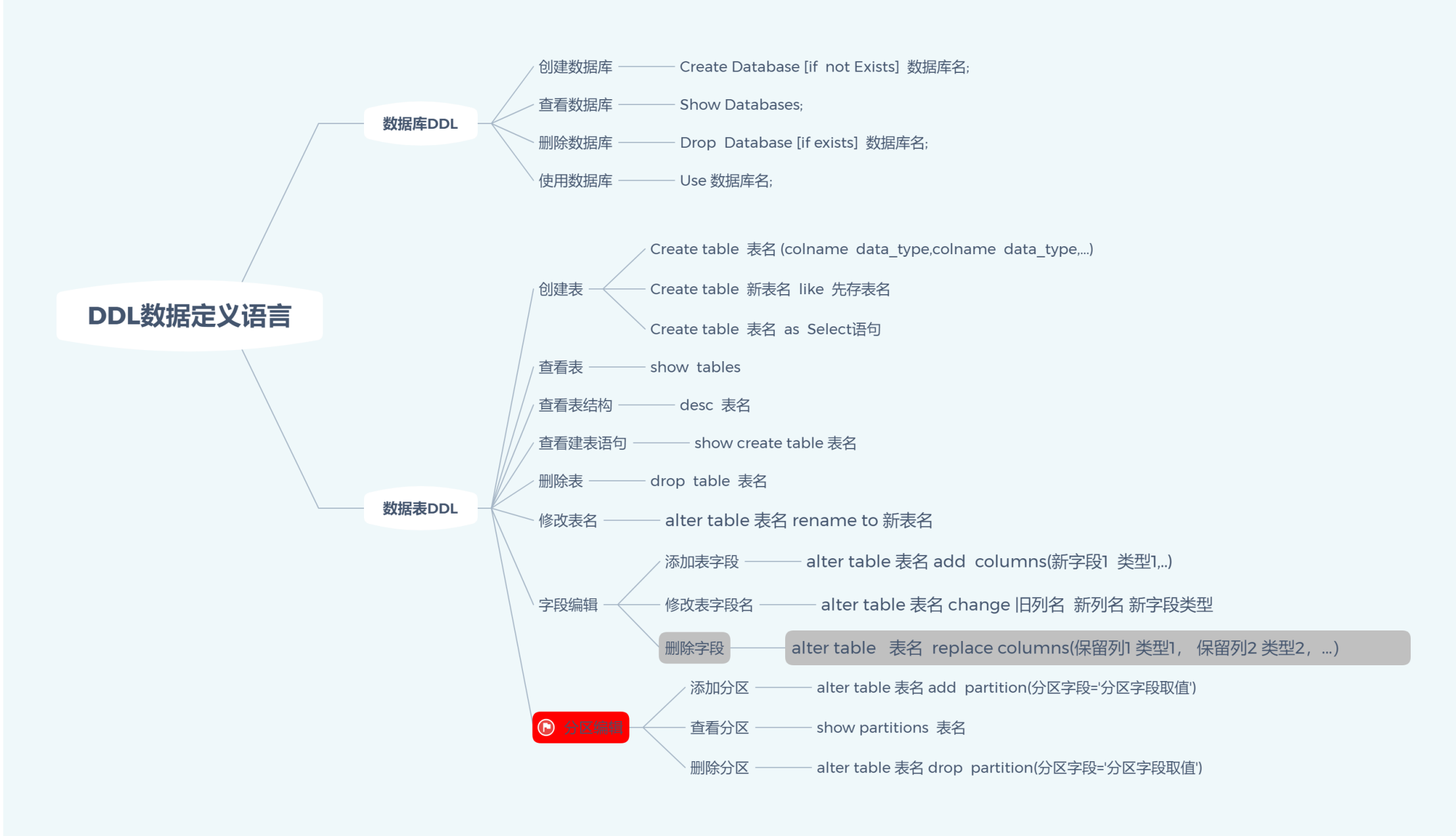
hive:数据表创建、导入、导出、删除
0.创建删除数据库
create Database if not Exists Hivetest;
use Hivetest;
1.数据类型
| 数字类 | 日期时间 | 字符串 | Misc类 | 复合类 | |
|---|---|---|---|---|---|
| 整型 | Tinyint,Smallint,Int,Bigint,长度分别1,2,4,8字节 | ||||
| 浮点型 | Float,Double,Decimal长度分别4,8,...字节 | ||||
| 日期时间 | TimeStamp-时间戳,Date日期格式yyyy-mm-dd,interval-时间间隔 | ||||
| 字符串 | string字符串,Varchar长度不固定字符串,Char长度固定字符串 | ||||
| Misc类 | Boolean布尔型,Binary字节型 | ||||
| 复合类 | ARRAY数组array<datatype>,MAP字典MAP<key_type,value_type>,Struct结构体Struct<col_name:date_type,col_name:data_type>,UnionType联合体UnionType<date_type,date_type...> |
2.数据类型转换
cast(列名 as 要转换的类型)
convert(数据类型,列名)
3.分隔符
分隔符:Row fotmat delimited
字段分隔符:fields terminated by '分隔符'
复合类型元素分隔符: collection items terminated by '分隔符'
Map类型的key和value分隔符:map keys terminated by '分隔符'
记录分隔符:lines terminated by '\\n'
4.分区表
1)分区表技术与意义
- 避免hive全表扫描,提升查询效率。
- 减少数据冗余进而提高特定(指定分区)查询分析的效率。
- 在逻辑上分区表与未分区表没有区别,在物理上分区表会将数据按照分区键的列值存储在表目录的 子目录中,目录名为“分区键=键值”。
- 查询时尽量利用分区字段。如果不使用分区字段,就会全部扫描。
2)分区表类型
静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断
- 静态分区
- 动态分区
5.分桶表
目的: 单个分区或者表中数据量越来越大,当分区不能更细粒度划分数据时,采用分桶技术将数据更细 力度的划分和管理
实质: 分桶是对分桶字段做hash 然后存到对应的文件中
作用:
- 提高join 查询效率(表A的每个桶就可以和表B对应的桶直接join,而不用全表join)
- 方便抽样
6.外部表与内部表
-- 有自动创建文件夹功能
create external table emp_external(
emp_no bigint,
first_name string,
last_name string,
gender string,
birth_date date,
from_date date,
dept_name string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
location '/user/xxxx/external_table/emp_external';
- 外部表内部表的区别
| 内部表 | 外部表 | |
|---|---|---|
| 关键字 | external | |
| 位置 | hive\metastore\warehouse | Location 指定 |
| 数据 | Hive自身管理(删除表直接删除元数据、存储数据) | HDFS管理(删除表仅会删除元数据,存储数据并不会被删除) |
7.数据导入
普通表:load data [local] inpath '数据文件路径' [overwrite] into table 表名;
分区表:load data [local] inpath '数据文件路径' [overwrite] into table 表名 [partition(分区字段='分区字段取值')];
insert into [table] 表名 [partition(分区字段[='分区字段取值'])]
insert overwrite table 表名 [partition(分区字段[='分区字段取值'])]
local: 指的是Liunx系统上的文件
overwrite: 关键字表示覆盖原有数据,没有此关键字表示添加数据
8.数据导出
INSERT OVERWRITE DIRECTORY '文件夹路径' ROW FORMAT DELIMITED FIELDS TERMINATED by '字段分隔符' 查询语句;
注意: OVERWRITE 把指定的文件夹重写了 (一定要小心覆盖掉有用的文件)
默认分隔符是用语句指定的,和本身建表语句指定的没有关系
有新建文件夹功能
导出的文件都为000000_0命名
- 导出到HDFS
INSERT OVERWRITE DIRECTORY '/user/admin/out_data'
ROW FORMAT DELIMITED FIELDS TERMINATED by '\t'
select * from emp_pt;
9.数据删除
删除所有数据
使用truncate仅可删除内部表数据,不可删除表结构
truncate table 表名
-- 删除内部数据
truncate table emp_pt;
使用shell命令删除外部表数据(hdfs dfs -rm -r 外部表路径)
-- 删除外部表数据
-- hdfs dfs -rm -r /user/admin/external_table/emp_external/*
文件列表内直接删除
删除表部分数据
- 有partition表
- 删除指定分区 :
alter table table_name drop partition(partiton_name='value'))
-- 删除指定分区
alter table emp_partition drop partition(dept_name = 'Sales');
- 删除partition内的部分信息(INSERT OVERWRITE TABLE)
INSERT OVERWRITE TABLE emp_partition partition(dept_name='Finance')
SELECT * FROM emp_partition
WHERE dept_name='Finance' and gender = "F";
重新把对应的partition信息写一遍,通过WHERE 来限定需要留下的信息,没有留下的信息就被删除了。
- 无partiton表
INSERT OVERWRITE TABLE 表名 SELECT * FROM 表名 WHERE 条件;
Insert overwrite table emp_pt select * from emp_pt where gender = "F";
10.示例
创建普通表
- 创建普通表
create table if not exists emp(
userid bigint,
emp_name array<string>,
emp_date map<string,date>,
other_info struct<deptname:string, gender:string>)
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':';
三类分隔符指令都存在时,顺序不能错。
导入数据
我这里使用hue上传,把本地文件传入到hive所在的服务器上。
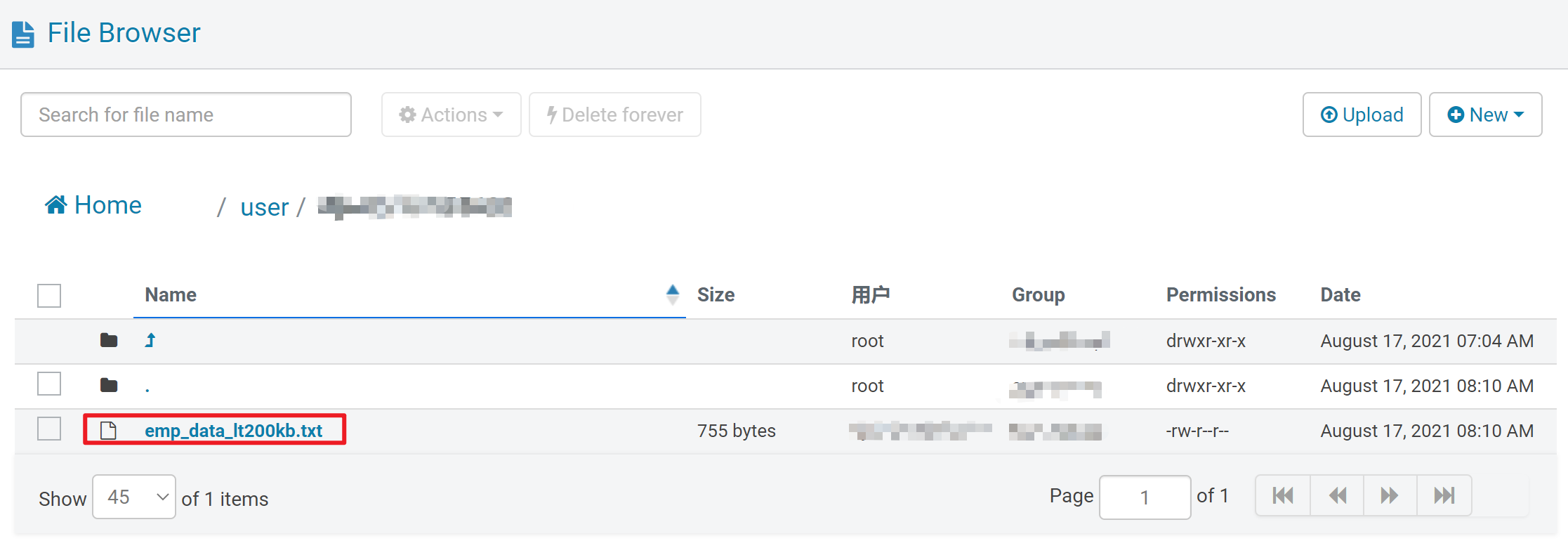
记录上传文件路径
装载
-- 装载数据,指定刚刚上传文件路径
load data inpath '/user/xxxx/emp_data_lt200kb.txt' into table emp;
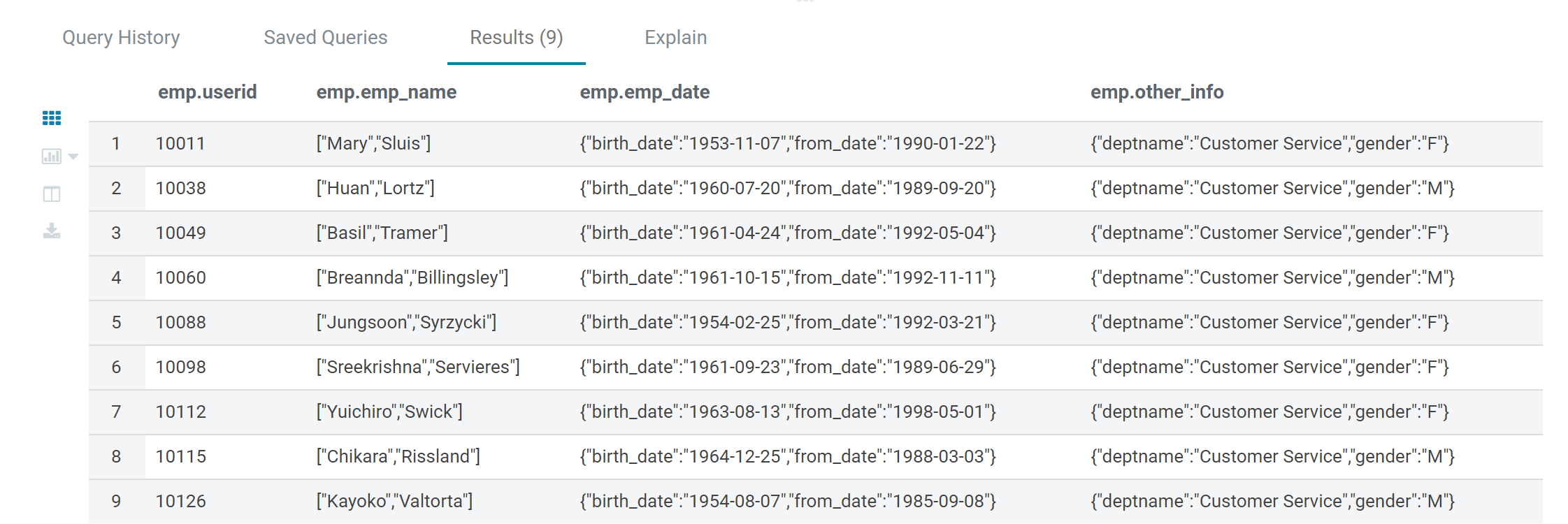
-- 查看数据
select * from emp;
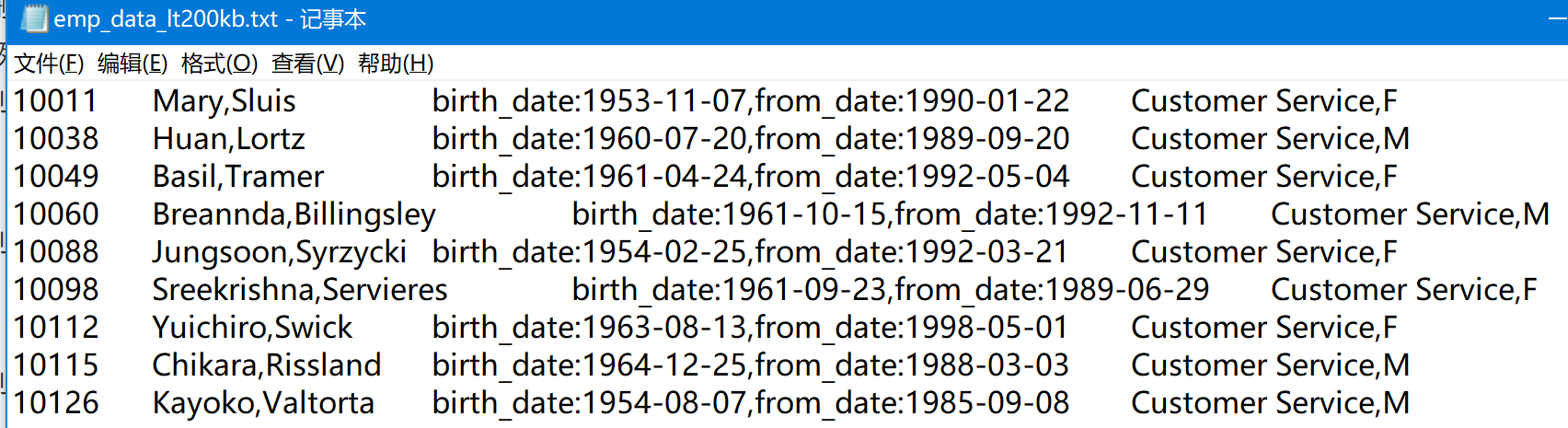
与 emp 表结构,对应的文件emp_data_lt200kb.txt 如下
创建分区表
- 创建分区表
-- 创建分区表,分区字段不能存在于字段列表中
create table if not exists emp_partition(
emp_no bigint,
first_name string,
last_name string,
gender string,
birth_date date,
from_date date)
partitioned by (dept_name string)
row format delimited
fields terminated by '\t';
- 查看分区表所在路径
show create table emp_partition;
-- localtion字段值即是路径
- 查看分区表
show partitions emp_partition;
-- 返回Done. 0 results.
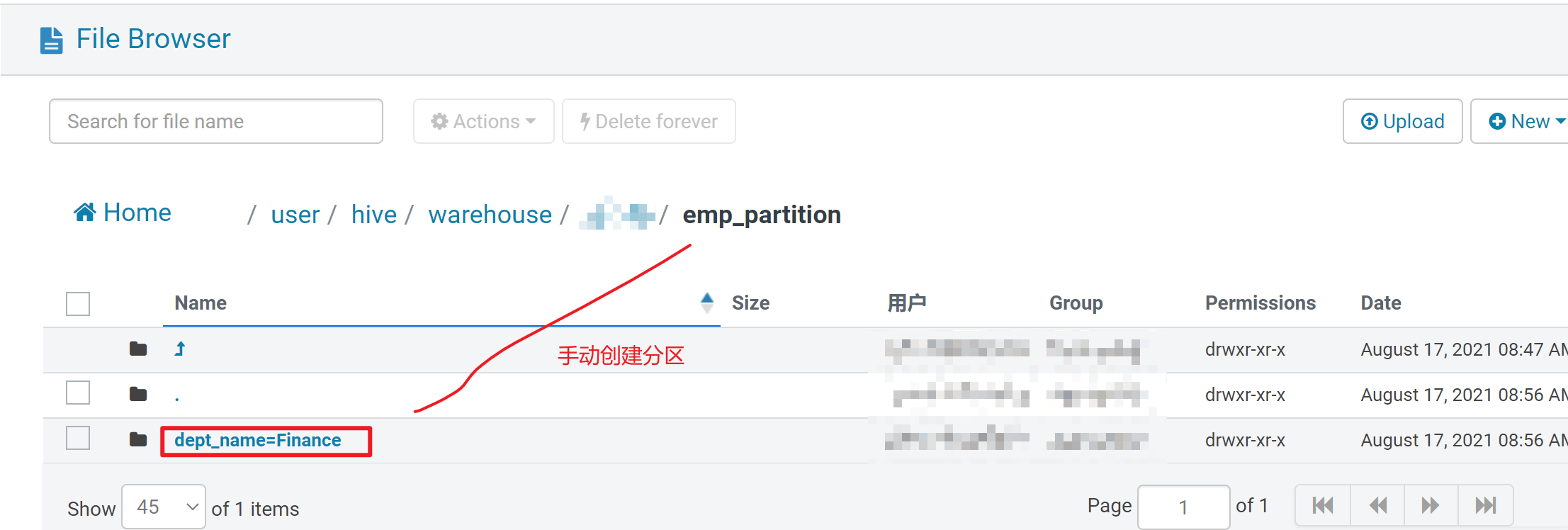
1.静态分区
手动增加一个名为'Finance'部门分区
alter table emp_partition add partition(dept_name='Finance');
2.动态分区
根据数据自动创建多个分区,这里根据公司部门分区。
步骤:
1.创建一个普通表
2.向普通表里加载全部数据
3.把普通表的数据插入到分区表中
-- 1.创建一个普通表
CREATE TABLE emp_pt(
emp_no bigint,
first_name string,
last_name string,
gender string,
birth_date date,
from_date date,
dept_name string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
-- 2.向普通表里加载全部数据
load data inpath '/user/xxxx/emp_data_PT2kb.txt' into table emp_pt;
-- 3.把普通表的数据插入到分区表中
-- 开启动态分区开关
set hive.exec.dynamic.partition.mode=nonstrict
-- 通过insert语句自动分区
insert overwrite table emp_partition partition(dept_name) select * from emp_pt;
# 这里加上overwrite覆盖之前手动增加的分区dept_name='Finance'
创建分桶表
- 创建分桶表
create table emp_bucket (
emp_no bigint,
first_name string,
last_name string,
gender string,
birth_date date,
from_date date,
dept_name string
)
clustered by(gender) into 2 buckets -- 为性别“男女”创建两个分桶
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
逻辑上分桶与否无差异,物理上每个桶为一个文件
装载数据
分桶表装载数据与普通表一致
-- 开启分桶功能
set hive.enforce.bucketing=true
-- 忽略掉安全检查
set hive.strict.checks.bucketing=false;
load data inpath '/user/xxx/emp_data_Sales.txt' into table emp_bucket;
hue 不支持像分桶表中Load data 数据
我是知识搬运工,把遇到喜欢的文章或对自己有用的知识保存下来。
如何把这些知识搬为已用呢?如何把这些知识提炼从而对自己产生价值?这是值得思考的一个问题。
