
作业07
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
逻辑回归通过正则化来防止过拟合;正则化可以防止过拟合是因为过拟合的时候,拟合函数的系数往往非常大,而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况,以L2正则化为例,正则项会使权重趋于0,就意味着大量权重就和0没什么差别了,此时网络就变得很简单,拟合能力变弱,从高方差往高偏差的方向移动。
2.用logiftic回归来进行实践操作,数据不限。
使用sklearn自带的数据集,导入数据并且分为训练集与测试集:
1 cancer = load_breast_cancer() 2 x = cancer.data 3 y = cancer.target 4 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=6)
创建逻辑回归模型并训练:
1 LR_model = LogisticRegression() 2 LR_model.fit(x_train, y_train)
使用训练好的模型进行预测,并输出准确率报告:
1 pre = LR_model.predict(x_test) 2 print('Accuracy:', LR_model.score(x_test, y_test)) 3 print('Classification Report:\n', classification_report(y_test, pre))
运行结果: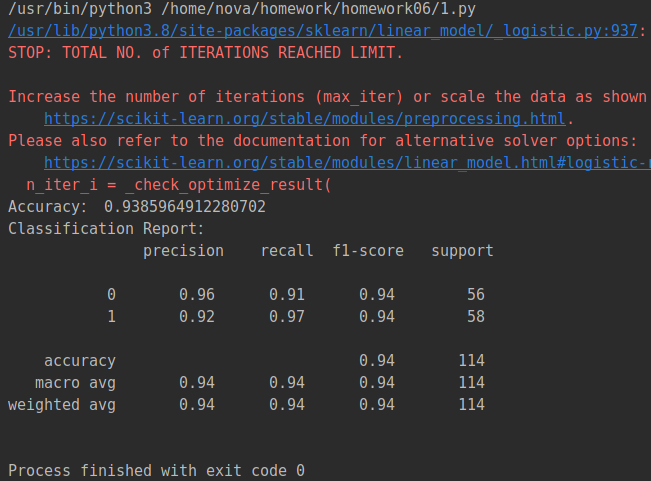
完整代码:
1 from sklearn.datasets import load_breast_cancer 2 from sklearn.linear_model import LogisticRegression 3 from sklearn.model_selection import train_test_split 4 from sklearn.metrics import classification_report 5 6 # Create the data 7 cancer = load_breast_cancer() 8 x = cancer.data 9 y = cancer.target 10 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=6) 11 12 # Create a model 13 LR_model = LogisticRegression() 14 15 # Train it 16 LR_model.fit(x_train, y_train) 17 18 # Predict 19 pre = LR_model.predict(x_test) 20 print('Accuracy:', LR_model.score(x_test, y_test)) 21 22 # Report 23 print('Classification Report:\n', classification_report(y_test, pre))
