
作业04
1. 应用K-means算法进行图片压缩
(1)读取一张图片
代码:
1 import cv2 2 original_img = cv2.imread('./original.jpg')
读取的原图:

(2)观察图片文件大小,占内存大小,图片数据结构,线性化
代码:
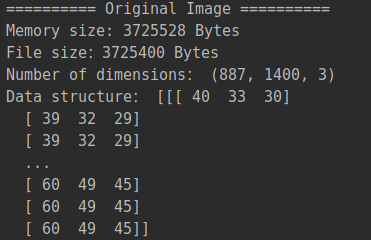
1 import sys 2 print('========== Original Image ==========') 3 print("Memory size: {} Bytes".format(sys.getsizeof(original_img))) 4 print('File size:{} Bytes'.format(original_img.size)) 5 print("Number of dimensions:", original_img.shape) 6 print("Data structure:", original_img) # 2 dimensions & 3 channels
图片占内存大小、文件大小、维度、数据结构:
(3)用kmeans对图片像素颜色进行聚类
代码:
1 from sklearn.cluster import KMeans 2 import numpy as np 3 # Compress the image 4 compressed = original_img[::3, ::3] 5 x = compressed.reshape(-1, 3) 6 # Create Kmeans center 7 n_colors = 64 8 model = KMeans(n_colors)
(4)获取每个像素的颜色类别,每个类别的颜色
代码:
1 # Predict 2 label = model.fit_predict(x) 3 colors = model.cluster_centers_
(5)压缩图片生成:以聚类中收替代原像素颜色,还原为二维
代码:
1 # Replace the original color with Kmeans prediction 2 Kmeans_compressed = colors[label].reshape(compressed.shape) 3 # Convert to uint8 and save 4 Kmeans_compressed = Kmeans_compressed.astype(np.uint8) 5 cv2.imwrite('Kmeans_compressed.jpg', Kmeans_compressed)
Kmeans压缩后的图片:

(6)观察压缩图片的文件大小,占内存大小
代码:
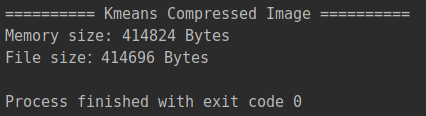
1 print('========== Original Image ==========') 2 print("Memory size: {} Bytes".format(sys.getsizeof(Kmeans_compressed))) 3 print('File size:{} Bytes'.format(Kmeans_compressed.size))
压缩图片占内存大小、文件大小:
完整代码:
1 #(1)读取一张图片 2 import cv2 3 original_img = cv2.imread('./original.jpg') 4 5 #(2)观察图片文件大小,占内存大小,图片数据结构,线性化 6 import sys 7 print('========== Original Image ==========') 8 print("Memory size: {} Bytes".format(sys.getsizeof(original_img))) 9 print('File size:{} Bytes'.format(original_img.size)) 10 print("Number of dimensions:", original_img.shape) 11 print("Data structure:", original_img) # 2 dimensions & 3 channels 12 13 #(3)用kmeans对图片像素颜色进行聚类 14 from sklearn.cluster import KMeans 15 import numpy as np 16 # Compress the image 17 compressed = original_img[::3, ::3] 18 x = compressed.reshape(-1, 3) 19 # Create Kmeans center 20 n_colors = 64 21 model = KMeans(n_colors) 22 23 #(4)获取每个像素的颜色类别,每个类别的颜色 24 # Predict 25 label = model.fit_predict(x) 26 colors = model.cluster_centers_ 27 28 #(5)压缩图片生成:以聚类中收替代原像素颜色,还原为二维 29 # Replace the original color with Kmeans prediction 30 Kmeans_compressed = colors[label].reshape(compressed.shape) 31 # Convert to uint8 and save 32 Kmeans_compressed = Kmeans_compressed.astype(np.uint8) 33 cv2.imwrite('Kmeans_compressed.jpg', Kmeans_compressed) 34 35 #(6)观察压缩图片的文件大小,占内存大小 36 print('========== Kmeans Compressed Image ==========') 37 print("Memory size: {} Bytes".format(sys.getsizeof(Kmeans_compressed))) 38 print('File size:{} Bytes'.format(Kmeans_compressed.size))
2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
使用sklearn的Kmeans模型与load_digits数据集对手写数字进行归类,完整代码如下:
1 # (1) Load dataset and set 10 classes 2 from sklearn.datasets import load_digits 3 from sklearn.cluster import KMeans 4 import matplotlib.pyplot as plt 5 digits = load_digits() 6 my_model = KMeans(n_clusters=10, random_state=0) 7 clusters = my_model.fit_predict(digits.data) # Train the model 8 my_model.cluster_centers_.shape 9 10 # Shows the features as images 11 fig, ax = plt.subplots(2, 5, figsize=(8, 3)) 12 centers = my_model.cluster_centers_.reshape(10, 8, 8) 13 for axi, center in zip(ax.flat, centers): 14 axi.set(xticks=[], yticks=[]) 15 axi.imshow(center, interpolation='nearest', cmap=plt.cm.binary) 16 17 # (3) Predict and calculate the accuracy 18 from scipy.stats import mode 19 import numpy as np 20 labels = np.zeros_like(clusters) 21 for i in range(10): 22 mask = (clusters == i) 23 labels[mask] = mode(digits.target[mask])[0] 24 from sklearn.metrics import accuracy_score 25 print(accuracy_score(digits.target, labels))
分类准确率:


