线程与进程
一.计算机组成原理
1.1了解线程与进程你先要了解一些操作系统的知识
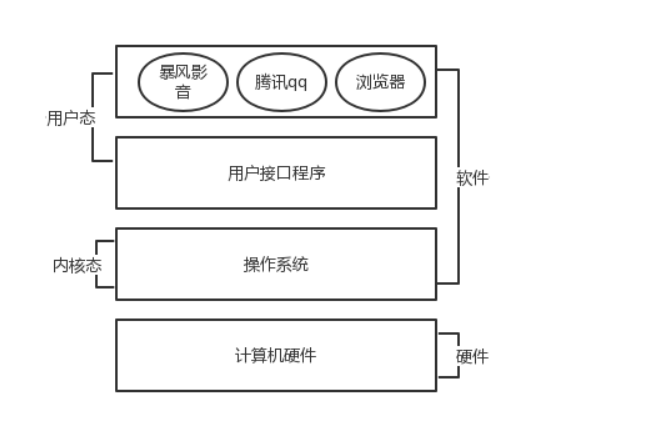
1.2计算机操作系统是由硬件还有软件组成的
硬件包括:硬盘,CPU,主板 ,显卡,内存,电源等等
软件主要是系统软件:系统就是一个由程序员写出来的软件,,该软件用于控制计算机的硬件,让他们之
间进行相互配合,还有一些软件就是我们安装的应用软件
精简的说的话,操作系统就是一个协调、管理和控制计算机硬件资源和软件资源的控制程序。操作系统所处的位置如图
2.并发和并行
并发,
并发: 伪装 多个线程切换用一个CPU 由于执行速度非常快人感觉不到
并行: 真正 每个线程分别用一个CPU同时进行 创建10个人同时操作
3线程与进程
a.单进程,单线程的应用程序
b.到底什么是线程?什么是进程
Python自己没有这东西Python中调用的操作系统的线程和进程
一个应用程序(软件),可以有多个进程(默认只有一个),一个进程中可以创建多个线程(默认一个).
简单总结:
1.操作系统帮助开发者操作硬件.
2程序员写好代码在系统上运行(依赖解释器).
二.在不同情况下的Python效率
Python多线程情况下:
计算密集型操作:效率低.(GIL锁)
IO操作:效率高
Python多线程的情况下:
计算密集型操作:效率高(浪费资源),不得已而为之
IO操作:效率好(浪费资源)
以后在写Python时:
IO密集型用多线程:文件\输入输出\socket网络通信
计算密集型用多进程
thread 方法说明:
t.start(): 激活线程
t.getName(): 获取线程名称
t.setName:() 设置线程名称
t.name(): 获取或设置线程名称
t.is_alive(): 判断线程是否激活状态
t.isAlive(): 判断线程是否为激活状态
t.setDeamon(): 主线程执行完,等待子线程执行完成后,程序停止
t.isDeamon(): 判断是否为守护线程
t.ident(): 获取线程的标识符是一个非零整数,只有在调用了start方法后该属性才有效否则返回None
t.join(): 逐个执行每一个线程,执行完毕后继续往下执行,该方法使得多个多线程变得无意义
t.run(): 线程被CPU调度后自动执行线程对象的run方法
线程的基本使用:
def func(arg):
print(arg)
t = threading.Thread(target=func,args=(11,))
t.start()
print('end')
结果:
end
线程的基本使用
主线程默认等到子线程执行完毕
import threading
import time
def func(arg):
time.sleep(arg)
print(arg)
t1 = threading.Thread(target=func,args=(3,))
t1.start()
t2 = threading.Thread(target=func,args=(9,))
t2.start()
print('end')
结果:
end
9
主线程默认等到子线程执行完毕
主线程不等待,主线程终止则所有的子线程终止
import threading
import time
def func(arg):
time.sleep(2)
print(arg)
t1 = threading.Thread(target=func,args=(3,))
t1.setDaemon(True) #主线程不等待,主线程终止则子线程终止
t1.start()
t2 = threading.Thread(target=func,args=(9,))
t2.setDaemon(True)
t2.start()
print('end')
结果:
end
主线程不等待,主线程终止则所有子线程终止
开发者控制主线程等待子线程最大时间
import threading
import time
def func(arg):
time.sleep(0.01)
print(arg)
print('创建子线程t1')
t1 = threading.Thread(target=func,args=(3,))
t1.start()
# 无参数,让主线程在这里等着,等到子线程t1执行完毕,才可以继续往下走。
# 有参数,让主线程在这里最多等待n秒,无论是否执行完毕,会继续往下走。
t1.join(2)
print('创建子线程t2')
t2 = threading.Thread(target=func,args=(9,))
t2.start()
t2.join(2) # 让主线程在这里等着,等到子线程t2执行完毕,才可以继续往下走。
print('end')
结果:
创建子线程t1
创建子线程t2
end开发者控制主线程等待子线程最大时间
设置与获取线程名称
def func(arg):
# 获取当前执行该函数的线程的对象
t = threading.current_thread()
# 根据当前线程对象获取当前线程名称
name = t.getName()
print(name,arg)
t1 = threading.Thread(target=func,args=(11,))
t1.setName('admin')
t1.start()
t2 = threading.Thread(target=func,args=(22,))
t2.setName('root')
t2.start()
print('end')
结果:
admin 11
rootend
设置与获取线程名称
线程的本质


def func(arg): print(arg) t1 = threading.Thread(target=func,args=(11,)) t1.start() # start 是开始运行线程吗?不是 # start 告诉cpu,我已经准备就绪,你可以调度我了。 print(123) 结果: 123
面向对象的多线程
#常见方式
def func(arg):
print(arg)
t1 = threading.Thread(target=func,args=(11,))
t1.start()
#继承方式
class MyThread(threading.Thread):
def run(self):
print(11111,self._args,self._kwargs)
t1 = MyThread(args=(11,))
t1.start()
t2 = MyThread(args=(22,))
t2.start()
print('end')
面向对象的多线程
扩展:
Java多线程情况下:
计算密集型操作:效率高
IO操作:效率高
Python多进程的情况下:
计算密集型操作:效率高(浪费资源)
IO操作: 效率高 但是浪费资源
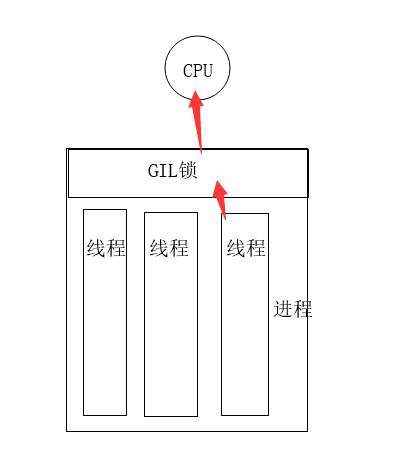
Python中线程和进程(GIL锁)
GIL锁,全局解释锁,用于限制一个进程中同一时刻只有一个线程被CPU调度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号