记录一次Oracle很卡事件
临近下班时间点,突然被同事告知数据库很卡,连查询都无法使用,登陆也是各种慢。
远程登陆到服务器(远程过程中也是费劲九牛二虎之力才上来),检查了服务器的各种资源,发现除了磁盘IO其他的资源一切正常,初步怀疑是IO问题导致的。
话不多说本地通过sqlplus命令连接到数据库,手动生成一次快照,命令如下:
C:\Users\Administrator>sqlplus zjsjgxt/jgzdwffz SQL*Plus: Release 11.2.0.1.0 Production on 星期三 9月 5 10:03:40 2018 Copyright (c) 1982, 2010, Oracle. All rights reserved. 连接到: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production With the Partitioning, OLAP, Data Mining and Real Application Testing options SQL> exec dbms_workload_repository.create_snapshot(); #手动生成一次快照 PL/SQL 过程已成功完成。 SQL> @?\rdbms\admin\awrrpt.sql #生成awr报告
生成报告花了近三分钟,也是没谁了。难道服务器性能到瓶颈了?
初步看了下awr报告,贴上部分图片
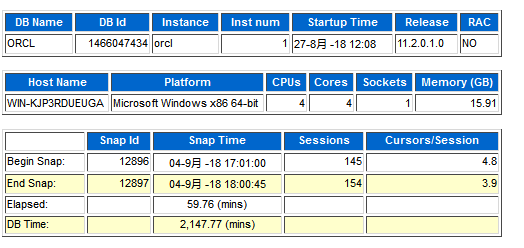
BD TIME 2000多分钟,这么繁忙!!!
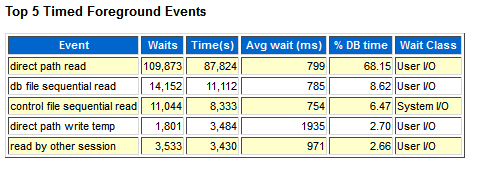
等待事件中显示,数据库之所以这么繁忙,是由于数据库做大量的全表扫描导致;看来问题应该出在sql语句上;
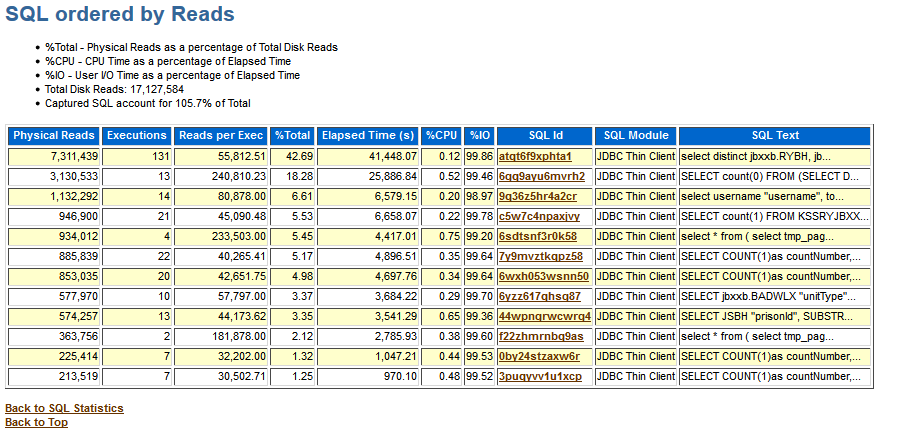
上图可以看出消耗IO最多的两条SQL语句。既然找出来了sql语句,那就好说。提出sql语句扔个程序猿。
附加部分动态视图的sql语句:
高资源消耗sql定位:
select sql_text,disk_reads,buffer_gets,parsing_scheme_name,executions From v$sqlarea Order by disk_reads desc;
排序较多的sql:
select sql_text,sorts,parsing_schema_nameFrom v$sqlarea Order by sorts desc;
消耗CPU较多的sql:
select * from (select v.sql_id,v.child_number,v.sql_text,v.elapsed_time,v.cpu_time,v.disk_reads,rank() over(order by v.cpu_time desc) elapsed_rank from v$sql v) a where elapsed_rank <= 10;
消耗磁盘较多的sql:
select * from (select v.sql_id,v.child_number,v.sql_text,v.elapsed_time,v.cpu_time,v.disk_reads, rank() over(order by v.disk_reads desc) elapsed_rank from v$sql v) a where elapsed_rank <= 10;
查询当前等待事件,主要是direct path read
select event, count(1) from v$session_wait WHERE EVENT NOT IN (select E.NAME from V$EVENT_NAME E WHERE E.WAIT_CLASS = 'Idle') group by event order by 2 desc;
查找产生direct path read的SQL
select * from v$sql where sql_id in (select distinct sql_id from v$session where event = 'direct path read');
注:SQL语句来源于网络资料,本人都已测试过,还是挺好用的!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号