Linux错误 DataNode起不来
undefinedundefined
一、问题描述
当我们多次格式化文件系统(hadoop namenode -format)时,会出现DataNode无法启动。
多次启动中发现有NameNode节点,并没有DataNode节点
如图所示:

二、查看问题
回头看启动过程
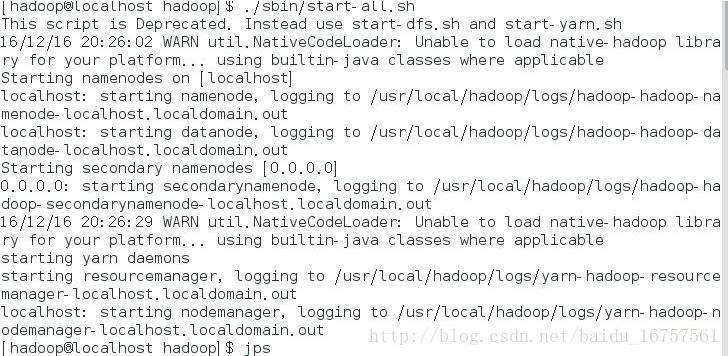
注意如下:
localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-localhost.localdomain.out
查看相关日志:
/usr/local/hadoop/logs/hadoop-hadoop-datanode-localhost.localdomain.log
注意查看.log的文件,这是相关日志,而不是看.out文件
部分日志如下:
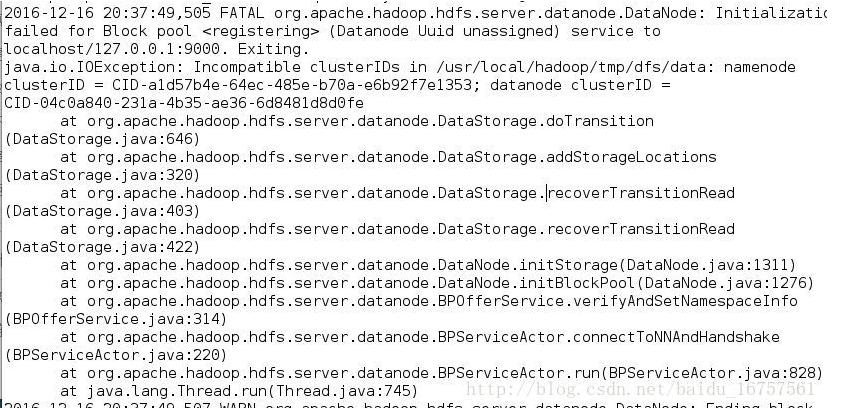
从日志上看,加粗的部分说明了问题
datanode的clusterID 和 namenode的clusterID 不匹配。
三、问题产生
当我们执行文件系统格式化时,会在namenode数据文件夹(即配置文件中dfs.name.dir在本地系统的路径)中保存一个current/VERSION文件,记录namespaceID,标志了所有格式化的namenode版本。如果我们频繁的格式化namenode,那么datanode中保存(即dfs.data.dir在本地系统的路径)的current/VERSION文件只是你地第一次格式化时保存的namenode的ID,因此就会造成namenode和datanode之间的ID不一致。
四、解决办法
根据日志中的路径,cd /home/hadoop/tmp/dfs(一般设置的dfs.name.dir在本地系统的路径),能看到 data和name两个文件夹。
解决方法一:(推荐)
删除DataNode的所有资料及将集群中每个datanode节点的/dfs/data/current中的VERSION删除,然后重新执行hadoop namenode -format进行格式化,重启集群,错误消失。
解决方法二:
将name/current下的VERSION中的clusterID复制到data/current下的VERSION中,覆盖掉原来的clusterID

让两个保持一致
然后重启,启动后执行jps,查看进程

出现该问题的原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。
—————————————分割线——————————
遇到了DataNode起不来的问题,删除了VERSION 也解决不了还导致系统坏掉了,改正方法
把hadoop的安装目录下、usr/local/hadoop/tmp文件夹删掉,之后使用hadoop namenode -format命令重新启动
之后再用start-dfs.sh完美解决


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步