Linux实验 Hadoop安装与使用
Hadoop 安装与使用
实验目的
掌握 Hadoop 的伪分布式安装方法。由于并不具备集群环境,需要在一台 机器上模拟一个小的集群。
实验准备
1.Windows电脑一台
2.VMware 15虚拟机
3.CentOS 7或者Ubuntu操作系统
4.FileZilla-3.7.3(用于主机与虚机之前传文件)
5.putty(用于主机登陆虚机)
6.puttygen(用于ssh无密码登陆,生成公钥私钥)
一、Hadoop部署安装
0.在Ubuntu中查看IP地址时出现"ifconfig命令未找到",解决方法sudo apt install net-tools即可解决
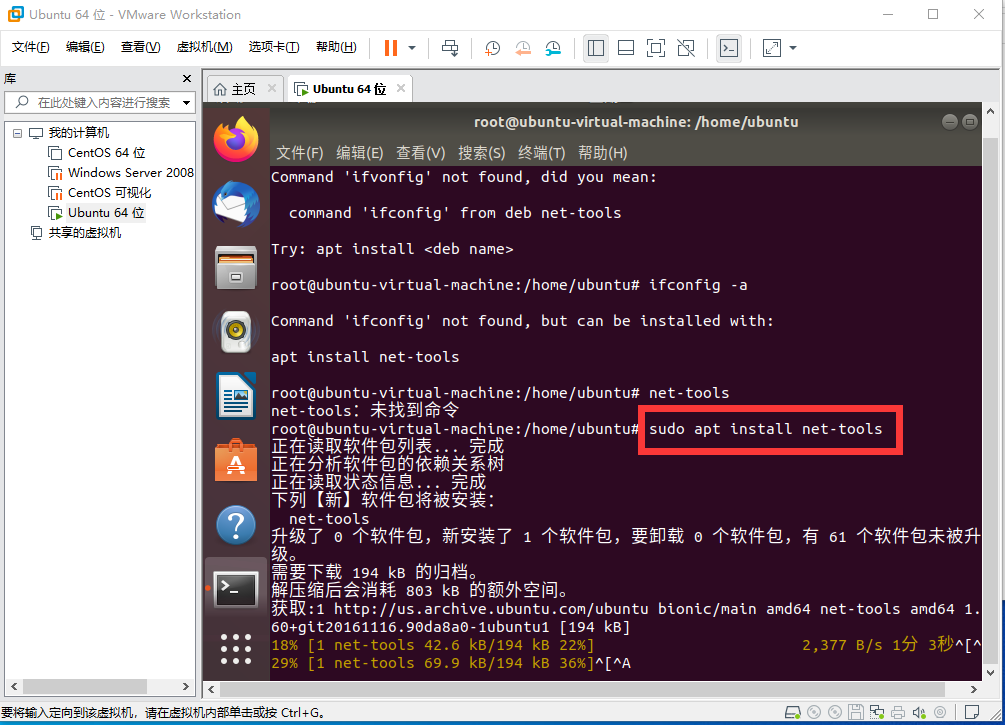
1.打开FileZilla软件,主机输入CentOS的IP地址,用户名输入登录名,密码输入登陆密码,端口输入22(STP连接),点击快速连接如图所示
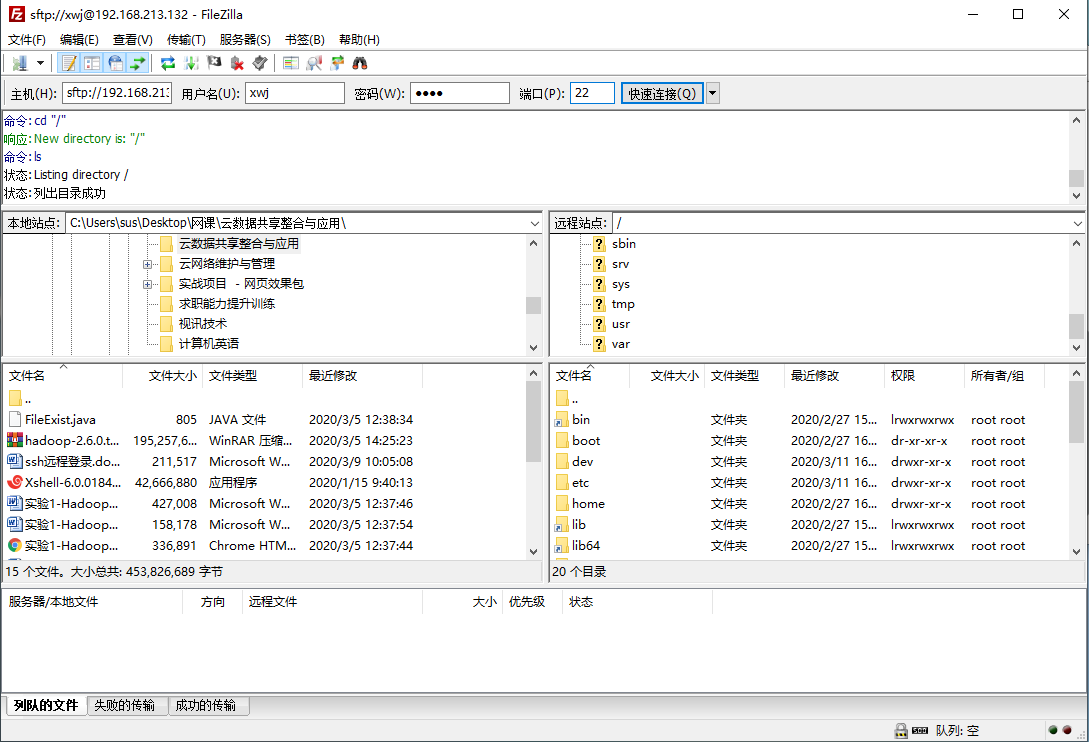
2.将hadoop-2.6.0拖入到/usr/lcoal文件夹中,用来做
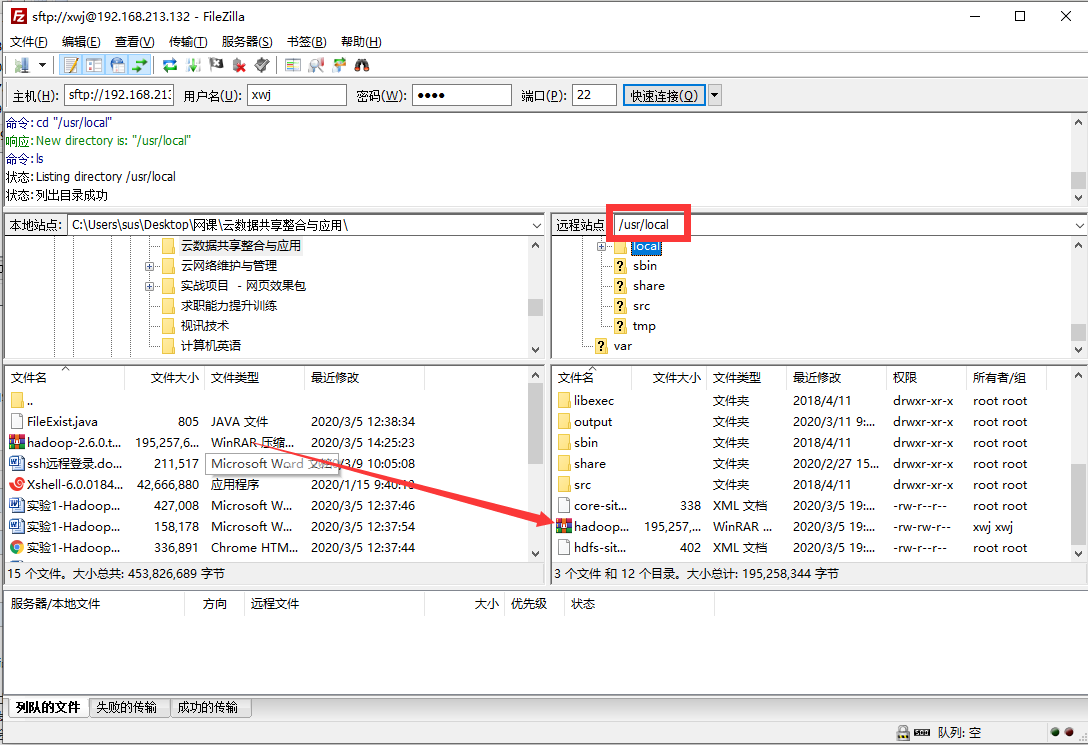
3.使用解压命令,解压hadoop-2.6.0.tar.gz,如果已经在/usr/local里面了可以用命令tar -zxvf hadoop-2.6.0.tar.gz -C /usr/local,如果现在在根目录或者不在/usr/local目录下,则必须用绝对路径
tar -zxvf /usr/local/hadoop-2.6.0.tar.gz -C /usr/local 解压到的文件名为hadoop-2.6.0
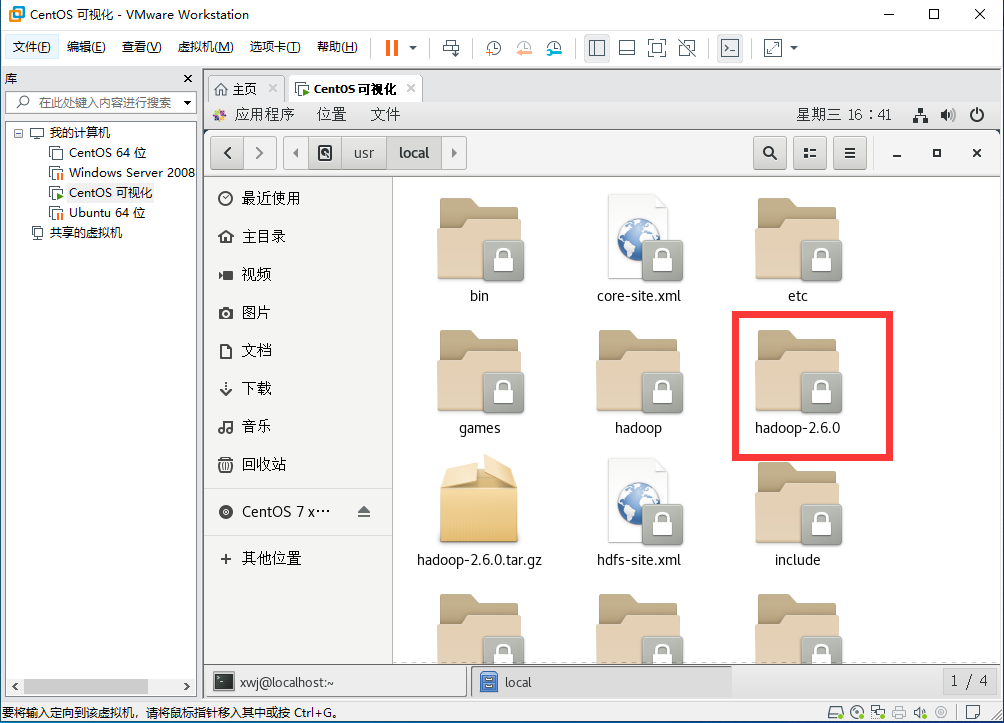
4.进入/usr/local 目录下,将hadoop-2.6.0改名为1-hadoop,mv /usr/local/hadoop-2.6.0 /usr/local/1-hadoop
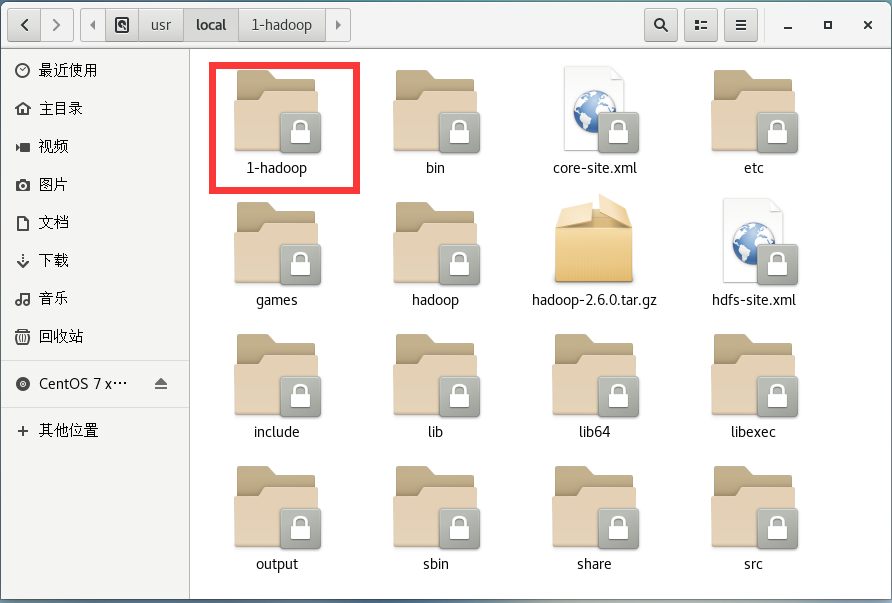
二、hadoop配置
1.openjdk开发包安装
由于hadoop采用Java语言开发,所以要安装Java开发包
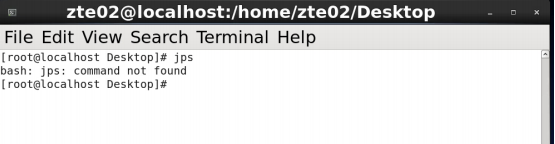
(1)使用jps命令查看是否已经安装jps
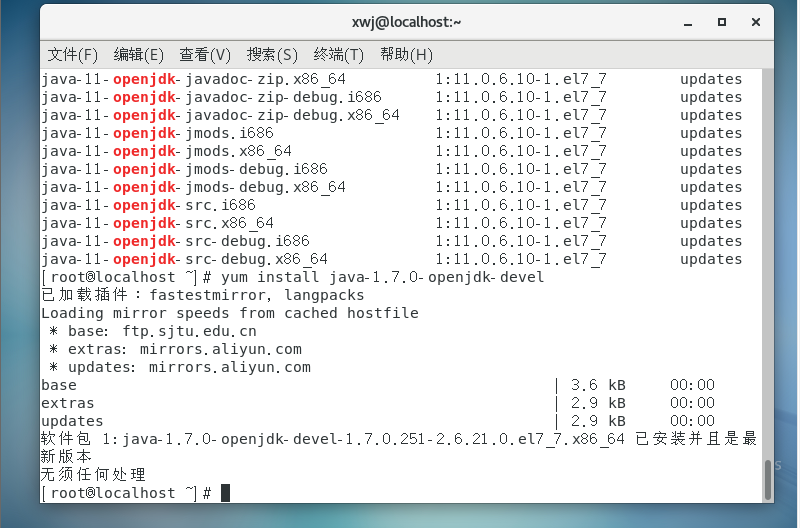
(2)安装Java开发包
命令yum list|grep openjdk
yum install java-1.7.0-openjdk-devel
2.环境变量配置
(1)编辑环境变量
vi ~/.bashrc
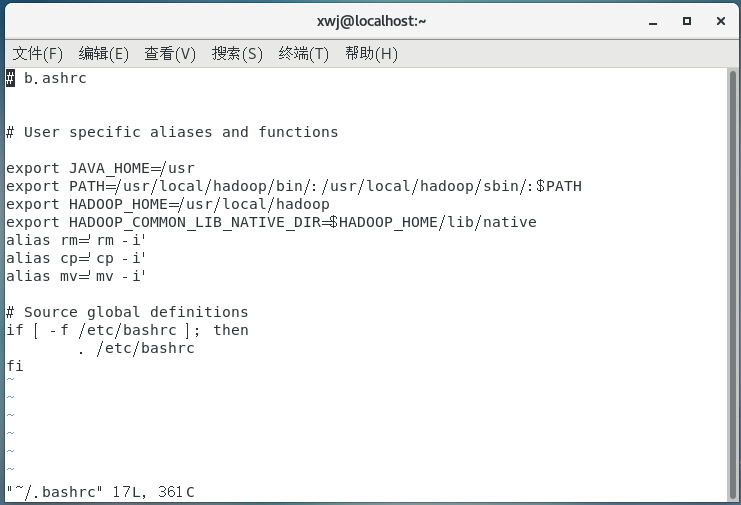
(2)环境变量生效
source ~/.bashrc
(3)查看验证
echo $JAVA_HOME # 检验变量值
java -version(注意小写和空格)

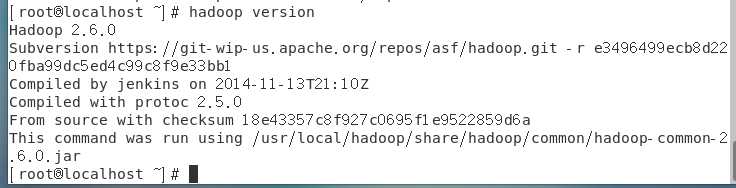
(4)检查hadoop是否可用
hadoop version
3.hadoop配置
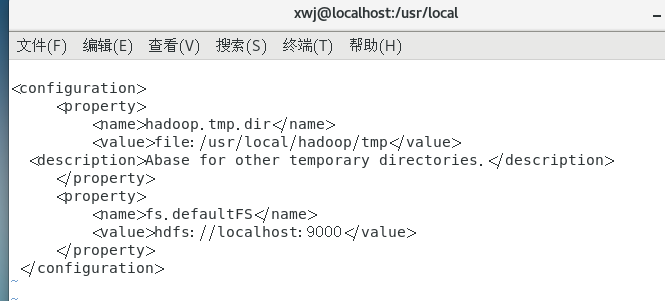
Hadoop 的配置文件位于 /usr/local/1-hadoop/etc/hadoop/ 中,伪分布式需 要修改 2 个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop 的配置文件 是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
a)修改配置文件 修改配置文件 core-site.xml (vi core-site.xml),修改为下面配置:
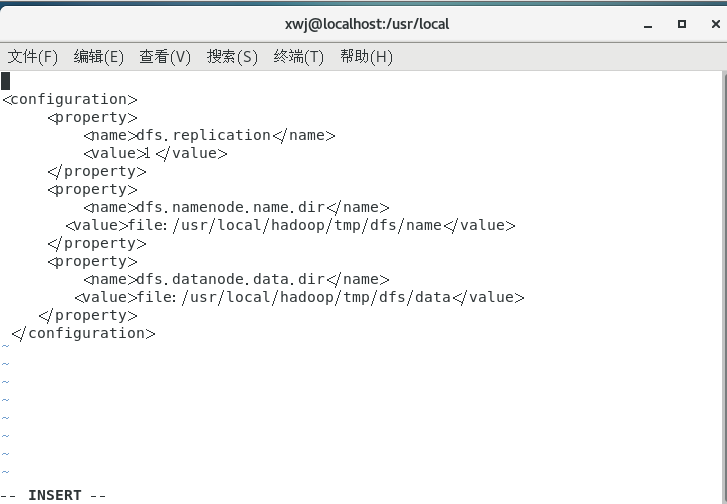
同样的,修改配置文件 hdfs-site.xml:
三、Hadoop的使用
1.启动Hadoop
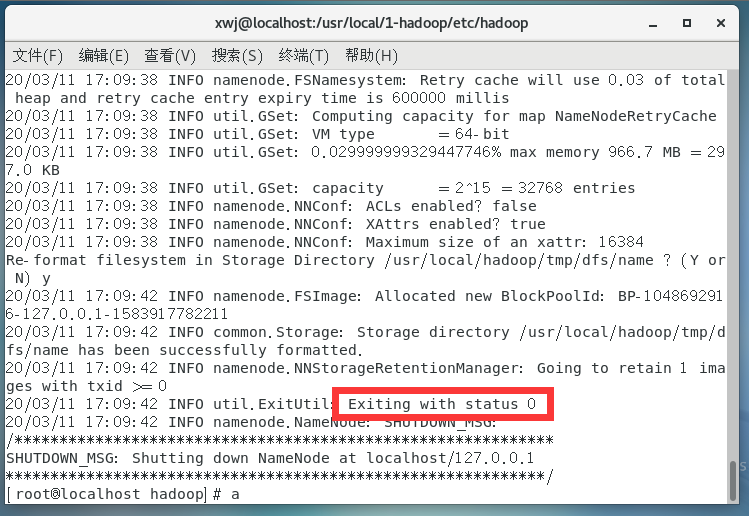
1)配置完成后,执行 NameNode 的格式化:
hdfs namenode -format,看到Exiting with status 0即为成功了
2)接着开启 NameNode 和 DataNode 守护进程。
输入命令 start-dfs.sh

出现的warning级别提示不用管,就是提示能运行但是完成不完美的意思
此时需要输入三次密码,分别用来开启NameNode,DataNode,SecondNameNode

此时DataNode和NameNode以及SecondNameNode全都启动
再使用jps命令查看试试
3)成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
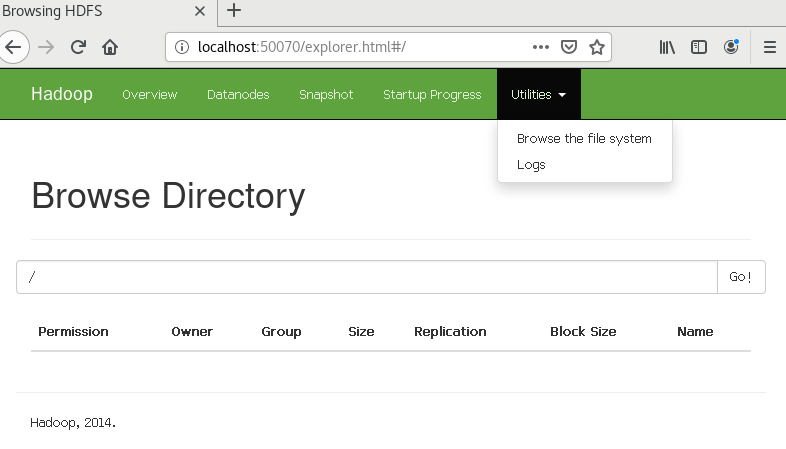
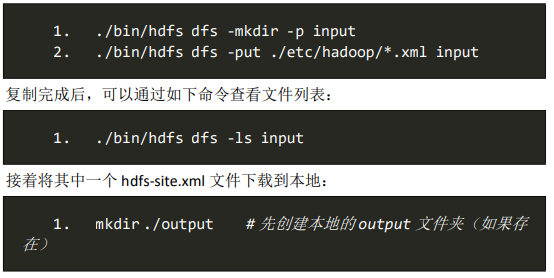
2、使用 HDFS,创建目录,上传文件和下载文件。
首先需要在 HDFS 中创建用户目录:

接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统 中,即将 /usr/local/1-hadoop/etc/hadoop 复制到分布式文件系统中的 /xwj/root/input 中。
我们使用的是 root 用户,并且已创建相应的用户目录 /xwj/root ,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就 是 /xwj/root/input:

至此,安装并使用hadoop大功告成!
