字符串碎碎念
Suffix Array 后缀数组
基本定义:
- \(su_i\) 表示起始位置为 \(i\) 的后缀
- \(sa_i\) 表示排名为 \(i\) 的后缀的起始位置
- \(rk_i\) 表示起始位置为 \(i\) 的后缀的排名,\(rk_{i,j}\) 表示从 \(i\) 到 \(j\) 的子串排名
- \(lcp(i,j)\) 表示 \(su_{sa_i}\) 与 \(su_{sa_{i-1}}\) 的最大公共前缀
- \(ht_i\) 表示排名为 \(i\) 的后缀与排名为 \(i-1\) 的后缀的最大公共前缀长度
注意到 \(rk\) 与 \(sa\) 为互逆的,即 \(sa_{rk_i}=rk_{sa_i}=i\)
所以应用此性质来求这两个数组
求 \(sa\) 与 \(rk\) 的倍增法
比较两个字符串的字典序,可以将这两个字符串每个都拆成一半,比较一半的字典序大小,即:\(rk_{i,j}\) 与 \(rk_{p,q}\) 的比较,可以变为两个二元组 \((rk_{i,i+k},rk_{i+k+1,j})\),\((rk_{p,p+k},rk_{p+k+1,q})\) 之间的比较,以第一个为第一关键字,第二个为第二关键字,其中 \(k\) 为介于 0 与这两个字符串长度之间的量
于是我们考虑倍增求它的排名,如果每次对 \(rk\) 都排序一遍的话,复杂度是 \(\Theta(n\log^2 n)\) 的,然后发现值域上界是 \(n\) 的,于是基数排序,总复杂度为 \(\Theta(n\log n)\)
其实还可以进行常数优化,考虑第二关键字的排序即为将 \(sa\) 往前移 \(w\),移不动的放在最前面,还有当值域为 \(n\) 时就可以停止排序
有一个细节就是对于一个排名来说可能对应着多个串,所以 \(sa\) 求时依次向后顺延即可
Code:
struct SA{
int s[N],buc[N],id[N],key[N],maxn,p;
int sa[N],rk[N<<1],oldrk[N<<1];
void getsa(){
maxn=30;p=0;
for(int i=2;i<=n;i++) lg[i]=lg[i>>1]+1;
for(int i=1;i<=n;i++) buc[rk[i]=s[i]]++;
for(int i=1;i<=maxn;i++) buc[i]+=buc[i-1];
for(int i=n;i>=1;i--) sa[buc[rk[i]]--]=i;
for(int w=1;;w<<=1,maxn=p,p=0){
for(int i=n-w+1;i<=n;i++) id[++p]=i;
for(int i=1;i<=n;i++) if(sa[i]>w) id[++p]=sa[i]-w;
for(int i=1;i<=maxn;i++) buc[i]=0;
for(int i=1;i<=n;i++) buc[key[i]=rk[id[i]]]++;
for(int i=1;i<=maxn;i++) buc[i]+=buc[i-1];
for(int i=n;i>=1;i--) sa[buc[key[i]]--]=id[i];
for(int i=1;i<=n;i++) oldrk[i]=rk[i]; p=0;
for(int i=1;i<=n;i++){
if(oldrk[sa[i]]!=oldrk[sa[i-1]]||oldrk[sa[i-1]+w]!=oldrk[sa[i]+w]) p++;
rk[sa[i]]=p;
}
if(p==n) break;
}
}
};
求 \(ht\) 数组
求 \(rk\) 数组的主要目的是为了求得 \(ht\) 数组,因为有以下性质:
考虑证明:我们设 \(p=sa_{rk_{i-1}-1}\) 则 \(ht_{rk_{i-1}}=\left| lcp(p,i-1)\right|\),那么 \(\left|lcp(i,p+1)\right| =ht_{rk_{i-1}}-1\)
容易得出, \(i-1\) 的排名大于 \(p\) 的排名,那么 \(i\) 的排名也大于 \(p+1\) 的排名,又因为处于 \(i\) 的排名和 \(p+1\) 的排名之间的后缀与这两个串的 \(lcp\) 不会小于这两个串之间的 \(lcp\),又因为 \(sa_{rk_{i}-1}\) 在这之间,所以这个命题成立
求出 \(ht_i\) 的代码为 \(O(n)\) 的,因为这个值的移动不超过 \(2n\) 次:
int k=0;
for(int i=1;i<=n;i++){
while(s[i+k]==s[sa[rk[i]-1]+k]) k++;
ht[rk[i]]=k;if(k) k--;
}
应用及例题
求两个后缀的最大公共前缀
有关后缀数组的应用基本上都是根据 \(ht\) 数组展开的,因为有这样一个东西:
以下这张图能给出一个感性的理解:
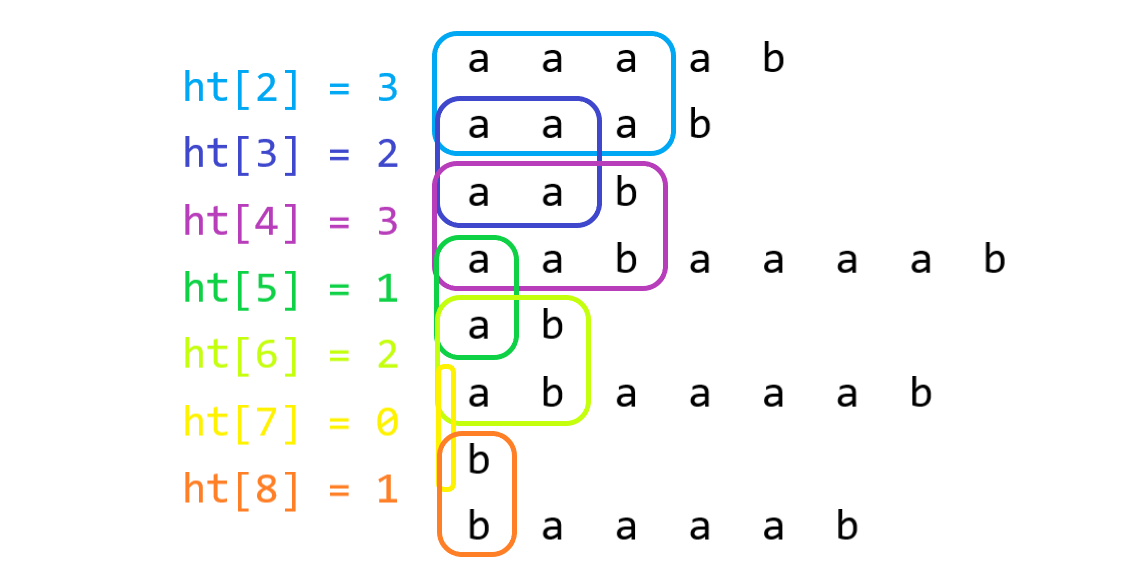
这也揭示了一个很显然的结论:两个串在字典序上距离越远,其最大公共前缀越短
对于上述式子,我们可以通过st表实现 \(O(n\log n)\sim O(1)\) 的复杂度
结合单调栈
P4248 [AHOI2013]差异
不难发现,\(lcp\) 是与 \(ht\) 的极值相关的,所以能维护最值的数据结构多少都能应用在后缀数组上
如果要是求所有后缀之间的 \(lcp\) 的和的话,也就是求 \(\sum\limits^n_{i=2}\sum\limits^n_{j=2}\min\limits^{max(rk_i,rk_j)}_{k=\min(rk_i,rk_j)+1}ht_k\)
所以单调栈求出每个 \(ht\) 作为最小值存在的左右区间,累加即可
求本质不同子串个数
不难发现,后缀的前缀即为子串,所以考虑以 \(sa_1,sa_2...sa_n\) 的顺序增加后缀,对于每个后缀来说,其子串与前边的子串重复的个数为 \(ht_i\)
那么答案即为 \(\frac{n*(n+1)}{2}-\sum\limits^n_{i=2}ht_i\)
查询排名为 \(k\) 的本质不同子串
思路与上一个相同,考虑 \(sa_i\) 与 \(sa_{i-1}\) 之间的子串个数即为 \(n-sa_i-ht_i\),求出排名前缀和后二分即可求出排名为 \(k\) 的子串的左右端点
求 \(n\) 个串的最长公共子串
P2463 [SDOI2008] Sandy 的卡片
首先把 \(n\) 个串连接起来并用分隔符分开,求整个串的后缀数组,然后需要找到一段 \(sa\) 上连续的区间,使得这段区间里包含每个串,则答案为这段区间每个串之间 \(lcp\) 的最小值,即这段区间 \(ht\) 的最小值,单调队列即可
P2178 [NOI2015] 品酒大会
好题
不难发现,对于 \(i\) 相似的酒可以组成多个连通块,每个连通块内同时也是 \(0,1...i-1\) 相似的,于是我们用并查集维护连通块大小,最大/小值,次大/小值,然后把 \(ht\) 数组排序后倒序连边即可
P2336 [SCOI2012]喵星球上的点名
\(sa\) +莫队
第一个询问:
对于一个后缀来说,我们在 \(sa\) 数组上可以找出与其公共前缀为k的若干串
由于 \(height\) 数组的性质,这些串在 \(sa\) 上是连续的,所以我们可以对于每个串进行二分,求出与查询串后缀公共前缀长度为查询串长度在 \(sa\) 上的左右端点
然后对于每个区间而言,求 \(id\) 种类数,发现这变成了一个裸的莫队,直接搞
第二个询问:
对于每个猫的出现次数,我们可以如此搞:
莫队每次新增种类时给这只猫加上剩余的操作数
每次清零一个种类时给这只猫减去剩余的操作数
于是发现这是一个差分,对于一个加和一个减的左闭右开区间里都满足情况
P4094 [HEOI2016/TJOI2016]字符串
这个问题是单调的,故可以二分答案求解
然后发现如果对于公共子串长度 \(mid\) 而言,其在 \(a\) 到 \(b\) 区间的左端点一定在 \(a\) 到 \(b-mid+1\) 之间
那对于这个区间建关于 \(rk\)的权值线段树,发现与 \(rk_c\) 离得最近的即为最长的公共前缀,再用st表判断一下即可
发现这是有双重限制的查询,果断主席树解决


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?