
循序渐进带你学习时间复杂度和空间复杂度。
写在之前
我们都知道,对于同一个问题来说,可以有多种解决问题的算法。尽管算法不是唯一的,但是对于问题本身来说相对好的算法还是存在的,这里可能有人会问区分好坏的标准是什么?这个要从「时效」和「存储」两方面来看。
人总是贪婪的,在做一件事的时候,我们总是期望着可以付出最少的时间、精力或者金钱来获得最大的回报,这个类比到算法上也同样适用,那就是花最少的时间和最少的存储做成最棒的解决办法,所以好的算法应该具备时效高和存储低的特点。这里的「时效」是指时间效率,也就是算法的执行时间,对于同一个问题的多种不同解决算法,执行时间越短的算法效率越高,越长的效率越低;「存储」是指算法在执行的时候需要的存储空间,主要是指算法程序运行的时候所占用的内存空间。
时间复杂度
首先我们先来说时间效率的这个问题,这里的时间效率就是指的算法的执行时间,时间的快慢本来就是一个相对的概念,那么到了算法上,我们该用怎样的度量指标去度量一个算法的时间效率(执行时间)呢?
刚开始我们想出了一种事后统计方法,我称它为「马后炮式」,顾名思义,就是对于要解决的某个问题,费尽心思想了 n 种解法,提前写好算法程序,然后攒了一堆数据,让它们分别在电脑上跑,跑完了然后比较程序的运行时间,根据这个来判断算法时效的高低。这种的判断技术计算的是我们日常所用的时间,但这并不是一个对我们来说有用的度量指标,因为它还依赖于运行的机器、所用的编程语言、编译器等等等等。相反,我们需要的是一个不依赖于所用机器或者编程语言的度量指标,这种度量指标可以帮助我们判断算法的优劣,并且可以用来比较算法的具体实现。
我们的科学家前辈们发现当我们试图去用执行时间作为独立于具体程序或计算机的度量指标去描述一个算法的时候,确定这个算法所需要的步骤数目非常重要。如果我们把算法程序中的每一步看作是一个基本的计量单位,那么一个算法的执行时间就可以看作是解决一个问题所需要的总步骤数。但是由于算法的执行过程又各不相同,所以这个每一步,即这个基本的计量单位怎么去选择又是一个令人头秃的问题。
下面我们来看一个简单的求和的函数:
def get_sum(n):
sum = 0
for i in range(1,n+1):
sum += i
return sum
print(get_sum(10))
我们仔细去分析一下上述代码,其实可以发现统计执行求和的赋值语句的次数可能是一个好的基本计数单位,在上面 get_sum 函数中,赋值语句的数量是 1 (sum = 0)加上 n (执行 sum += i 的次数)。
我们一般用一个叫 T 的函数来表示赋值语句的总数量,比如上面的例子可以表示成 T(n) = n + 1。这里的 n 一般指的是「数据的规模大小」,所以前面的等式可以理解为「解决一个规模大小为 n,对应 n+1 步操作步数的问题,所需的时间为 T(n)」。
对于 n 来说,它可以取 10,100,1000 或者其它更大的数,我们都知道求解大规模的问题所需的时间比求解小规模要多一些,那么我们接下来的目标就很明确了,那就是「寻找程序的运行时间是如何随着问题规模的变化而变化」。
我们的科学家前辈们又对这种分析方法进行了更为深远的思考,他们发现有限的操作次数对于 T(n) 的影响,并不如某些占据主要地位的操作部分重要,换句话说就是「当数据的规模越来越大时,T(n) 函数中的某一部分掩盖了其它部分对函数的影响」。最终,这个起主导作用的部分用来对函数进行比较,所以接下来就是我们所熟知的大 O 闪亮登场的时间了。
大 O 表示法
「数量级」函数用来描述当规模 n 增加时,T(n) 函数中增长最快的部分,这个数量级函数我们一般用「大 O」表示,记做 O(f(n))。它提供了计算过程中实际步数的近似值,函数 f(n) 是原始函数 T(n) 中主导部分的简化表示。
在上面的求和函数的那个例子中,T(n) = n + 1,当 n 增大时,常数 1 对于最后的结果来说越来不越没存在感,如果我们需要 T(n) 的近似值的话,我们要做的就是把 1 给忽略掉,直接认为 T(n) 的运行时间就是 O(n)。这里你一定要搞明白,这里不是说 1 对 T(n) 不重要,而是当 n 增到很大时,丢掉 1 所得到的近似值同样很精确。
再举个例子,比如有一个算法的 T(n) = 2n^2+ 2n + 1000,当 n 为 10 或者 20 的时候,常数 1000 看起来对 T(n) 起着决定性的作用。但是当 n 为 1000 或者 10000 或者更大呢?n^2 起到了主要的作用。实际上,当 n 非常大时,后面两项对于最终的结果来说已经是无足轻重了。与上面求和函数的例子很相似,当 n 越来越大的时候,我们就可以忽略其它项,只关注用 2n^2 来代表 T(n) 的近似值。同样的是,系数 2 的作用也会随着 n 的增大,作用变得越来越小,从而也可以忽略。我们这时候就会说 T(n) 的数量级 f(n) = n^2,即 O(n^2)。
最好情况、最坏情况和平均情况
尽管前面的两个例子中没有体现,但是我们还是应该注意到有时候算法的运行时间还取决于「具体数据」而不仅仅是「问题的规模大小」。对于这样的算法,我们把它们的执行情况分为「最优情况」、「最坏情况」和「平均情况」。
某个特定的数据集能让算法的执行情况极好,这就是最「最好情况」,而另一个不同的数据会让算法的执行情况变得极差,这就是「最坏情况」。不过在大多数情况下,算法的执行情况都介于这两种极端情况之间,也就是「平均情况」。因此一定要理解好不同情况之间的差别,不要被极端情况给带了节奏。
对于「最优情况」,没有什么大的价值,因为它没有提供什么有用信息,反应的只是最乐观最理想的情况,没有参考价值。「平均情况」是对算法的一个全面评价,因为它完整全面的反映了这个算法的性质,但从另一方面来说,这种衡量并没有什么保证,并不是每个运算都能在这种情况内完成。而对于「最坏情况」,它提供了一种保证,这个保证运行时间将不会再坏了,**所以一般我们所算的时间复杂度是最坏情况下的时间复杂度**,这和我们平时做事要考虑到最坏的情况是一个道理。
在我们之后的算法学习过程中,会遇到各种各样的数量级函数,下面我给大家列举几种常见的数量级函数:
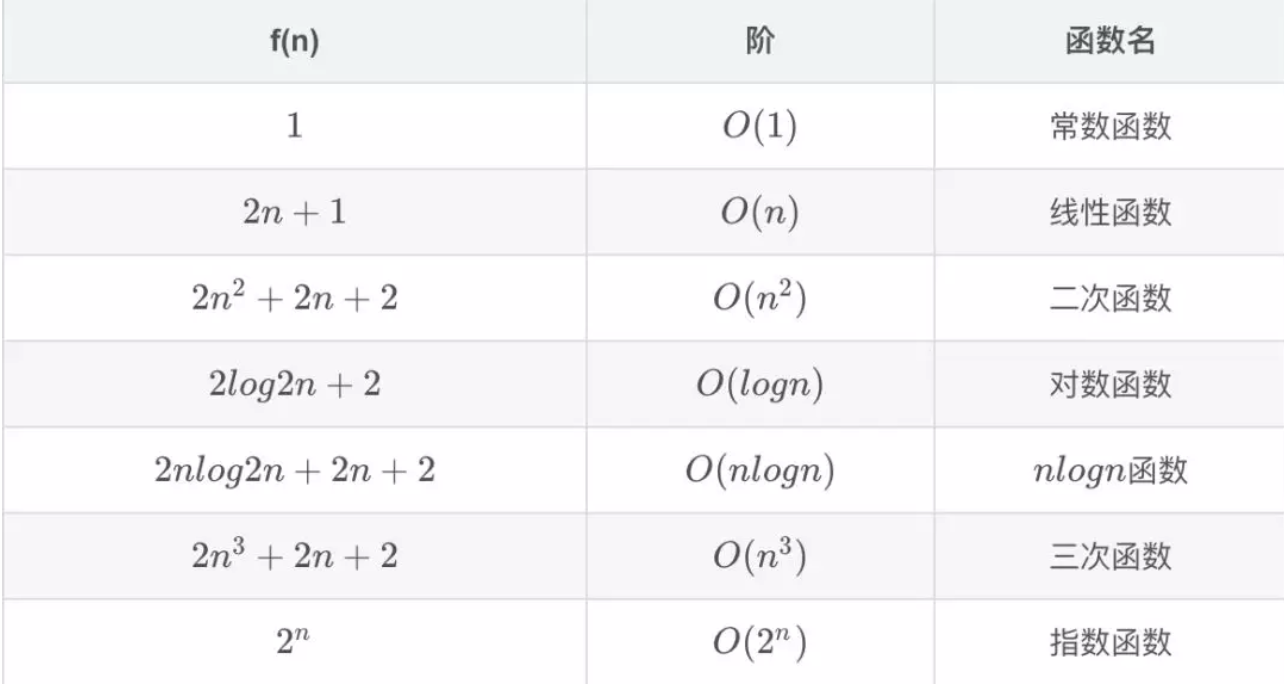
为了确定这些函数哪些在 T(n) 中占主导地位,就要在 n 增大时对它们进行比较,请看下图(图片来自于 Google 图片):
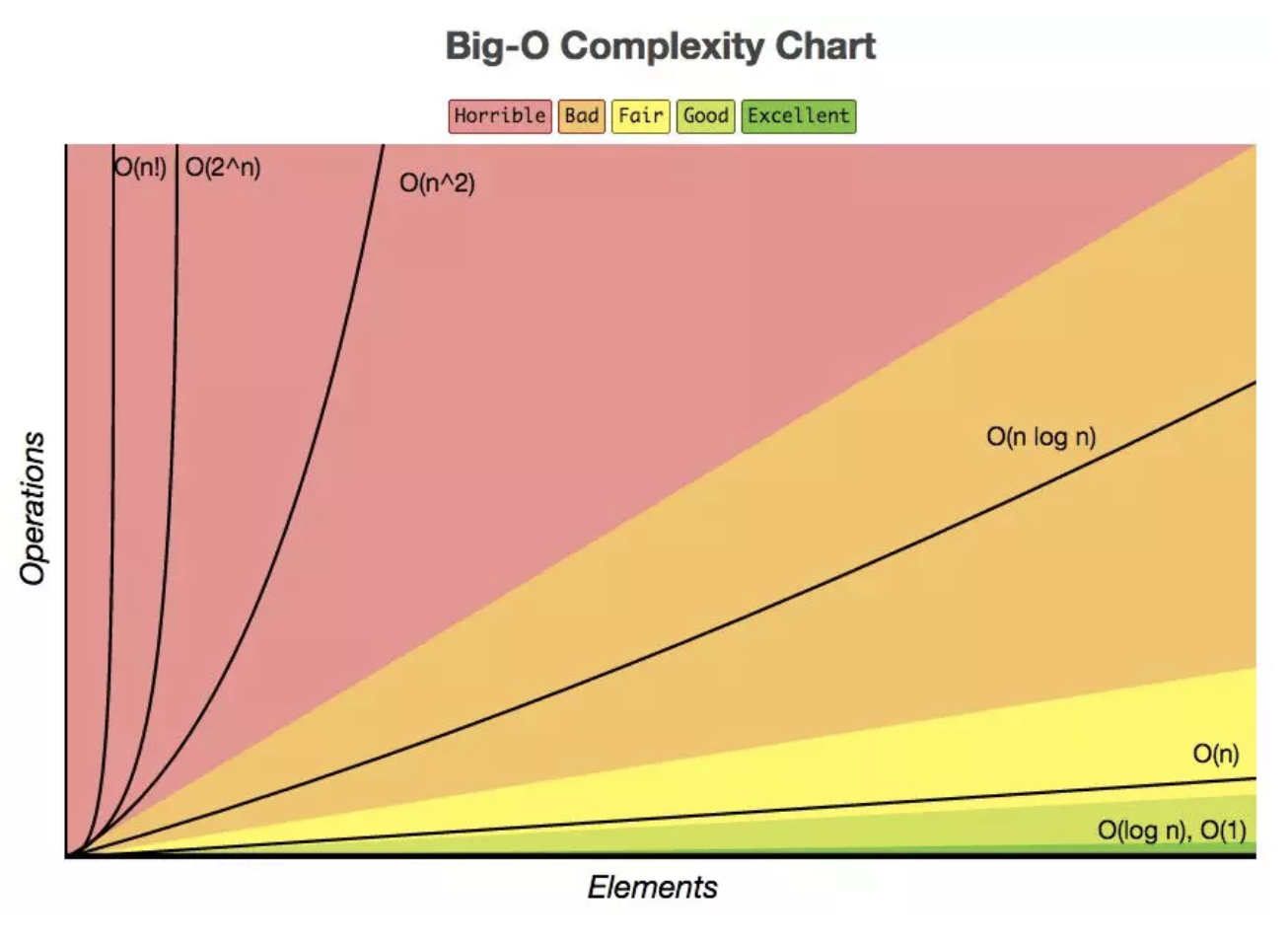
在上图中,我们可以看到当 n 很小时,函数之间不易区分,很难说谁处于主导地位,但是当 n 增大时,我们就能看到很明显的区别,谁是老大一目了然:
O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n)
我们下面就来分析几个上述所说的「数量级函数」:
1.常数函数
n = 100 # 1 次 sum = (1 + n) *n / 2 # 1 次 print(sum) # 1 次
上述算法程序的 f(n) = 3,可能有人看到这会说那么时间复杂度就是 O(f(n)) = O(3),其实这个是错的,这个函数的时间复杂度其实是 O(1)。这个对于初学者来说是很难理解的一种结果,其实你可以把 sum = (1 + n) * n / 2 多复制几次再来看:
a = 100 # 1 次 sum = (1 + n) * n / 2 # 1 次 sum = (1 + n) * n / 2 # 1 次 sum = (1 + n) * n / 2 # 1 次 sum = (1 + n) * n / 2 # 1 次 sum = (1 + n) * n / 2 # 1 次 sum = (1 + n) * n / 2 # 1 次 print(sum) # 1 次
上述算法的 f(n) = 8,事实上你可以发现无论 n 为多少,上述两段代码就是 运行 3 次和运行 8 次的区别。这种与数据的规模大小 n 无关,执行时间恒定的算法我们就叫它具有 O(1) 的时间复杂度。不管这个常数是多少,我们都记作是 O(1),而不是 O(3) 或者是 O(8)。
2.对数函数
cnt = 1
while cnt < n:
cnt *= 2 # O(1)
上面的算法程序的时间复杂度就是 O(logn),这个是怎么算出来的呢?其实很简单:上述的代码可以解释成 cnt 乘以多少个 2 以后才能大于等于 n,我们假设个数是 x,也就是求 2^x = n,即 x = log2n,所以这个循环的时间复杂度就是 O(logn)。
最后呢,我们来看看下面的这个例子,借助这段代码来详细的说一下我们如何对其时间复杂度进行详细的分析:
a = 1
b = 2
c = 3
for i in range(n):
for j in range(n):
x = i * i
y = j * j
z = i * j
for k in range(n):
u = a * k + b
v = c * c
d = 4
上面的代码没有任何意义,甚至不是一个可运行的代码,我只是用来说明你在以后如何对代码进行执行分析,关于代码本身可不可以运行,就不需要你在这关心了。
上面的代码其实我们要分的话可以分成 4 部分:第 1 部分是 a,b,c 这 3 个赋值语句,执行次数也就是 3 次;第二部分是 3n^2,因为是循环结构,里面有 x,y,z 这 3 个赋值语句,每个语句执行了 n^2 次;第 3 部分是 2n,因为里面是 2 个赋值语句,每条语句被执行了 n 次;最后第 4 部分是常数 1,只有 d 这么 1 条赋值语句。所以我们得到的 T(n) = 3+3n^2 +2n+1 = 3n^2+2n+4,看到指数项,我们自然的发现是 n^2 做主导,当 n 增大时,后面两项可以忽略掉,所以这个代码片段的数量级就是 O(n^2)。
空间复杂度
类比于时间复杂度的讨论,一个算法的空间复杂度是指该算法所耗费的存储空间,计算公式计作:S(n) = O(f(n))。其中 n 也为数据的规模,f(n) 在这里指的是 n 所占存储空间的函数。
一般情况下,我们的程序在机器上运行时,刨去需要存储程序本身的输入数据等之外,还需要存储对数据操作的「存储单元」。如果输入数据所占空间和算法无关,只取决于问题本身,那么只需要分析算法在实现过程中所占的「辅助单元」即可。如果所需的辅助单元是个常数,那么空间复杂度就是 O(1)。
空间复杂度其实在这里更多的是说一下这个概念,因为当今硬件的存储量级比较大,一般不会为了稍微减少一点儿空间复杂度而大动干戈,更多的是去想怎么优化算法的时间复杂度。所以我们在日常写代码的时候就衍生出了用「空间换时间」的做法,并且成为常态。比如我们在求解斐波那契数列数列的时候我们可以直接用公式去递归求,用哪个求哪个,同样也可以先把很多结果都算出来保存起来,然后用到哪个直接调用,这就是典型的用空间换时间的做法,但是你说这两种具体哪个好,伟大的马克思告诉我们「具体问题具体分析」。
写在之后
如果上面的文章你仔细看了的话,你会发现我不是直接上来就告诉你怎么去求时间复杂度,而是从问题的产生,到思考解决的办法,到“马后炮”,再到 T(n),最后到 O(n)一步一步来的。这样做的原因呢有两个:一是为了让你了解大 O 到底是怎么来的,有时候搞明白了由来,对于你接下来的学习和理解有很大的帮助;二是为了让这个文章看起来不是那么枯燥,我觉得很多时候上来扔给你一堆概念术语,很容易就让人在刚看到它的时候就打起了退堂鼓,循序渐进的来,慢慢引导着更容易接受一些。
很多人从大学到工作,代码写了不少依然不会估算时间复杂度,我感觉倒不是学不会,而是内心没有重视起来。你可能觉得计算机的更新换代很快,CPU 处理速度的能力越来越棒,没必要在一些小的方面斤斤计较,其实我觉得你是 too young too naive。我们随便来算一个简单的例子:有两台电脑,你的电脑的运算速度是我的电脑的 100 倍,同样一道问题,明明稍微想一想用 O(n) 可以做出来,你偏偏要懒,直接暴力 O(n^2),那么当 n 的数据稍微增大一些,比如上万上十万,到底谁的运算速度快还用我再告诉你吗?
所以今后在写算法的时候,请好好学会用时间复杂度估算一下自己的代码,然后想想有没有更有效率的方法去改进它,你只要这样做了,相信慢慢的你的代码会写的越来越好,头会越来越秃。(逃
最后说一点的是,估算算法的复杂度这件事你不要指望一下子看了一篇文章就想弄懂,这个还是要有意识的多练,比如看到一个程序的时候有意识的估算一下它的复杂度,准备动手写代码的时候也想想有没有更好的优化方法,有意识的练习慢慢就会来了感觉。这篇文章我就用了几个小例子,大概的估算方式就是这样。之后我还会继续写一些关于「数据结构与算法」相关的文章和一些具体的实战题目,都会带大家继续分析它们的时间复杂度,敬请期待。
欢迎大家关注公众号「Python空间」,一个坚持原创的技术公众号,专注Python 编程,每天坚持推送各种 Python 基础/进阶文章,数据分析,爬虫实战,数据结构与算法,不定期分享各类资源。期待和你的交流。

