
RocketMQ 在同程旅行的落地实践
 Rocket MQ 在同程旅行的使用场景有削峰、解耦、异步处理以及数据同步等。目前已经在公司各大业务线的核心系统里得到广泛使用,承受了来自微信入口的巨大流量,每天有1000+ 亿条消息周转,快来了解具体是如何实现的吧!
Rocket MQ 在同程旅行的使用场景有削峰、解耦、异步处理以及数据同步等。目前已经在公司各大业务线的核心系统里得到广泛使用,承受了来自微信入口的巨大流量,每天有1000+ 亿条消息周转,快来了解具体是如何实现的吧!
本文作者:刘树东 - 同程艺龙技术专家
01/使用概况

同程旅行选择RocketMQ主要基于以下几个方面的考虑:
技术栈:公司主要以 Java 开发为主,因此我们倾向于选择一款用 Java 实现的MQ,且没有任何第三方依赖为最佳;
久经考验:Rocket MQ 经历了阿里双11考验,性能、稳定性得到了充分验证;
功能实用:RocketMQ 的发送端提供改了同步、异步、单边、延时发送的功能;消费端有重试队列、死信队列以及消息重置功能,非常方便实用。
综合以上三点,我们选择了 Rocket MQ。

Rocket MQ 在同程旅行的使用场景有削峰、解耦、异步处理以及数据同步等。目前已经在公司各大业务线的核心系统里得到广泛使用,承受了来自微信入口的巨大流量,每天有1000+ 亿条消息周转。

同程旅行RocketMQ 框架图如上。机票、交通和酒店三大业务线通过 Java SDK 以及Http Proxy 的方式接入到 MQ 集群。其中Http Proxy 主要为了方便其他语言客户端使用;同时为了更好地实现资源隔离,我们将后端服务端节点按照业务线做了物理隔离,能够最大程度地确保业务线之间不会互相影响。整个 MQ 集群通过 MQ 服务平台进行治理。
02/同城双中心

同城双中心主要为实现以下三个目标:
-
单机放故障时保证业务可用
-
保证数据可靠
-
横向扩容
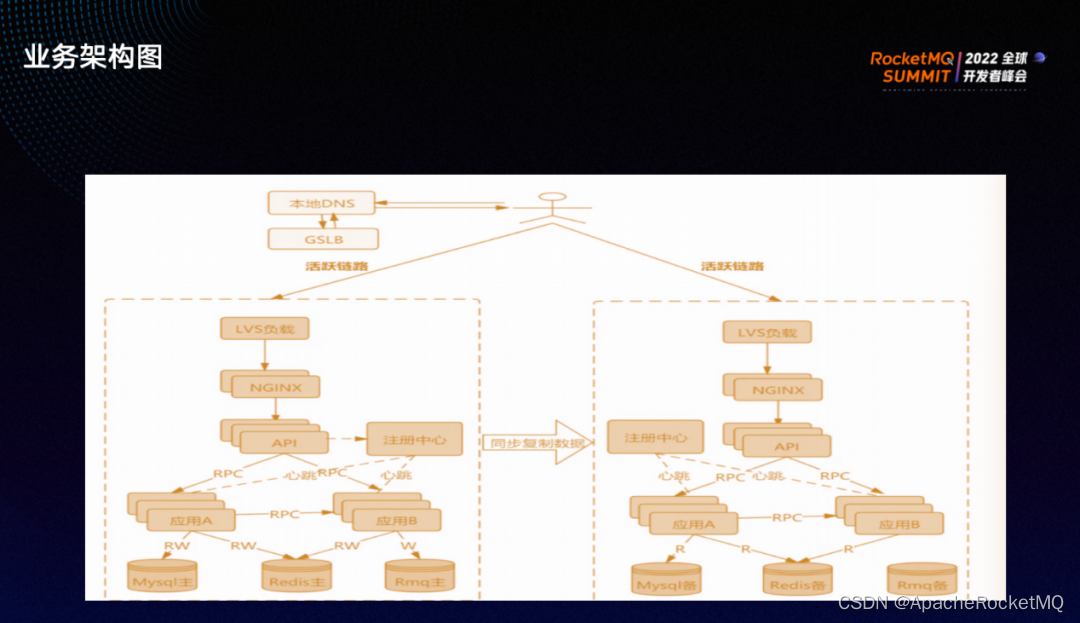
外部用户请求经过 LVS 以及 Nginx 调用服务与应用,应用底层主要调用了 MySQL、Redis 以及 MQ,双中心可分为同城冷备和同城双活两个方案。
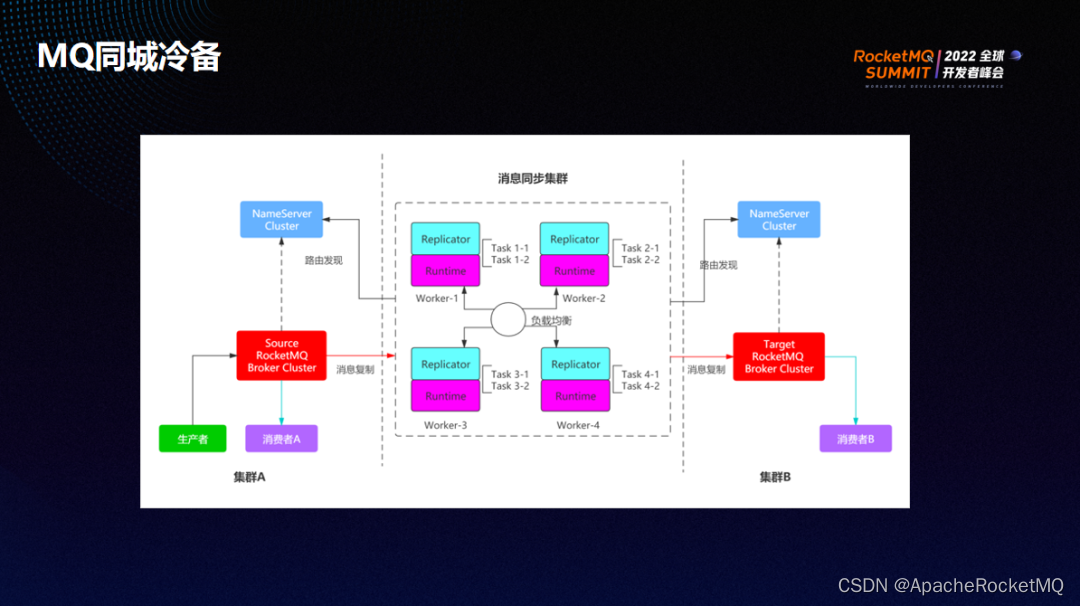
同城冷备有两个 MQ 集群,分别是 source 集群和target 集群。生产者会将消息生产到 source 集群,之后经过消息同步集群将 source 集群里的元数据比如 topic、消费组、消息等同步给 target 集群。source 集群和 target 集群中的消费者都可以进行消费。
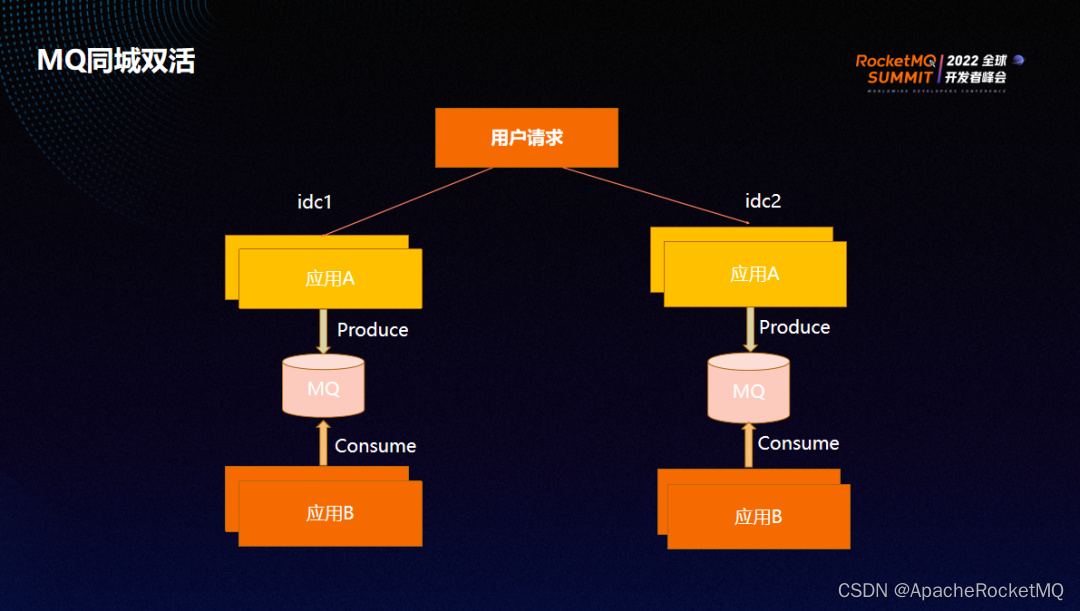
同城双活我们建立了跨中心的全局 MQ 集群。用户流量分散到两个中心,每个业务会将生产的消息往自己中心的 MQ 写。同时,其他服务与应用会从本中心消费所需消息。

当出现单机房 broker 节点故障时,每组 broker 的两 slave 位于不同机房,至少有一台 slave 拥有近乎全量的数据;消息生产会跨机房到另一个机房,另一个机房的消费者继续消费。

简单对比下,同城冷备方案需要 source 和target 两个集群,因此资源使用率不高,还需要同步 topic 、消费组、消费进度等元数据;同城双活方案资源使用比较合理,业务流量在何处,就在该处进行生产与消费消息。

同城双活有以下三点诉求:
①就近生产:生产端在A机房,则生产的消息也存于A机房的 broker。
②就近消费者:消费者在A机房,则消费者消息也来自A机房的 broker。
③broker 主节点故障,能够实现自动的选主。
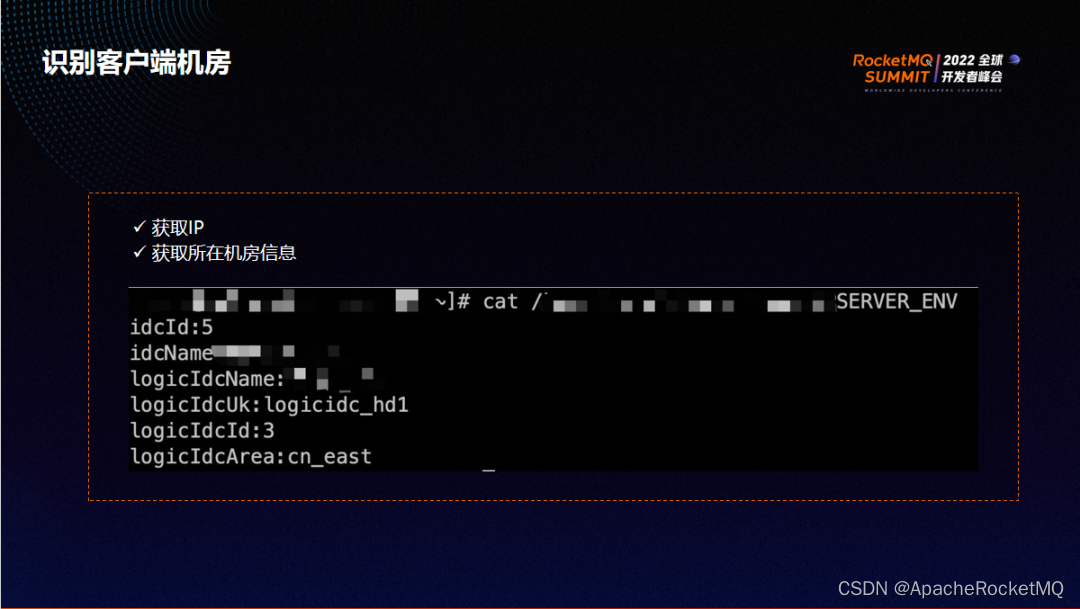
就近生产与就近消费的核心问题是如何识别客户端与服务端是否在同一机房。识别客户端所在机房可以通过两个途径:
第一,获取客户端所在IP,然后通过第三方组件解析出 IP 所属机房;
第二,与运维人员配合,在每一台容器或物理机里设置环境变量,通过读取环境变量来感知客户端所在机房。比如从环境变量里读取到逻辑机房的 ID或逻辑机房的名称。

识别服务端机房有三种途径:
第一,通过 IP 查询,解析IP 段属于哪个机房;
第二,服务端节点向元数据节点注册时,在协议层增加机房标识;
第三,在 broker 名字上增加机房标识。
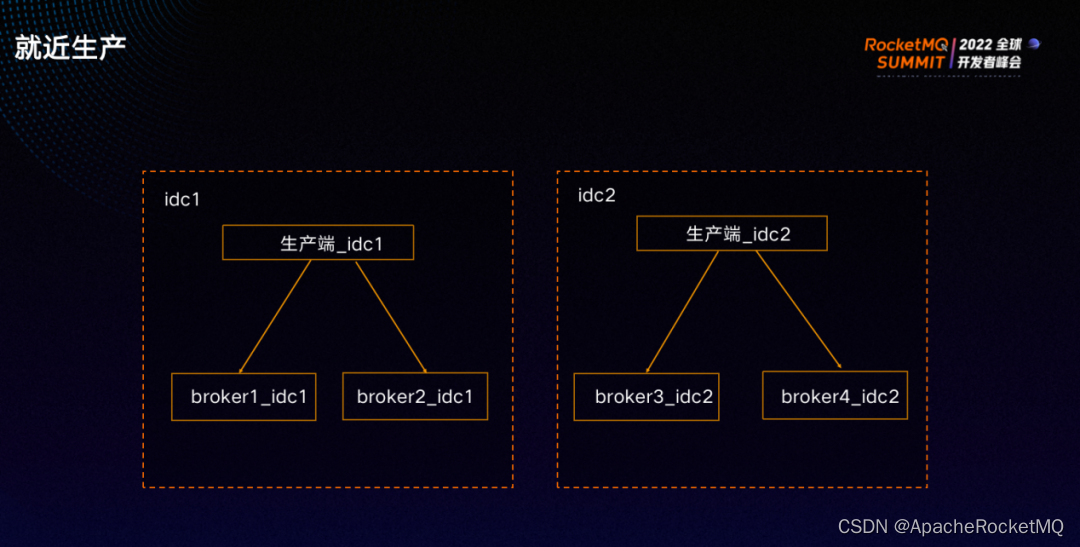
就近生产的原则:优先就近生产,就近生产无法满足时则跨机房生产。
如果机房后端的服务节点可用,则生产端会将消息生产到各自的机房里。如果机房的所有 broker节点都不可用,则生产端会将消息投递到另一个中心的 broker。
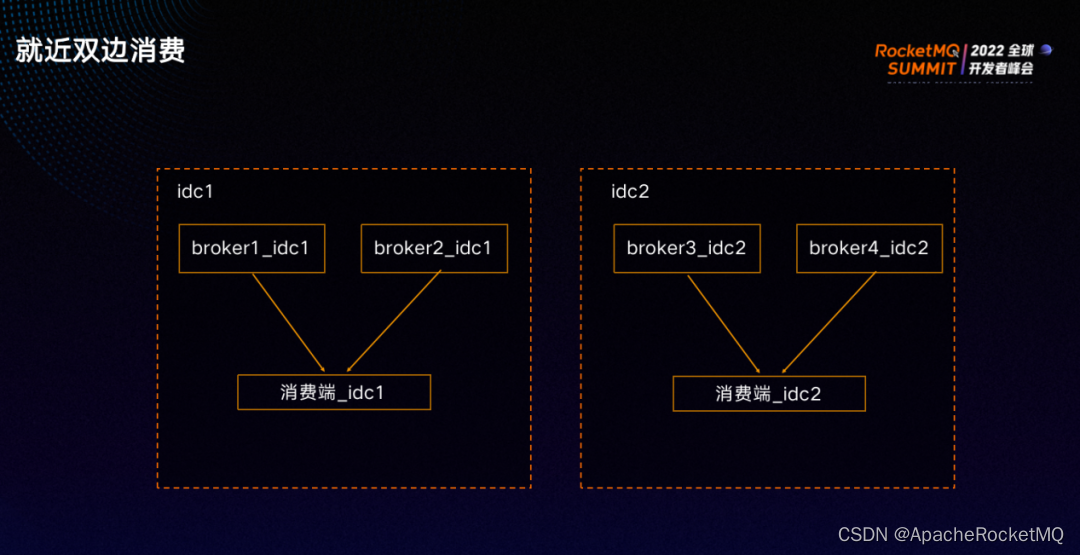
两个机房消费端都正常的情况下,每个机房的消费端只会消费本机房的消息。
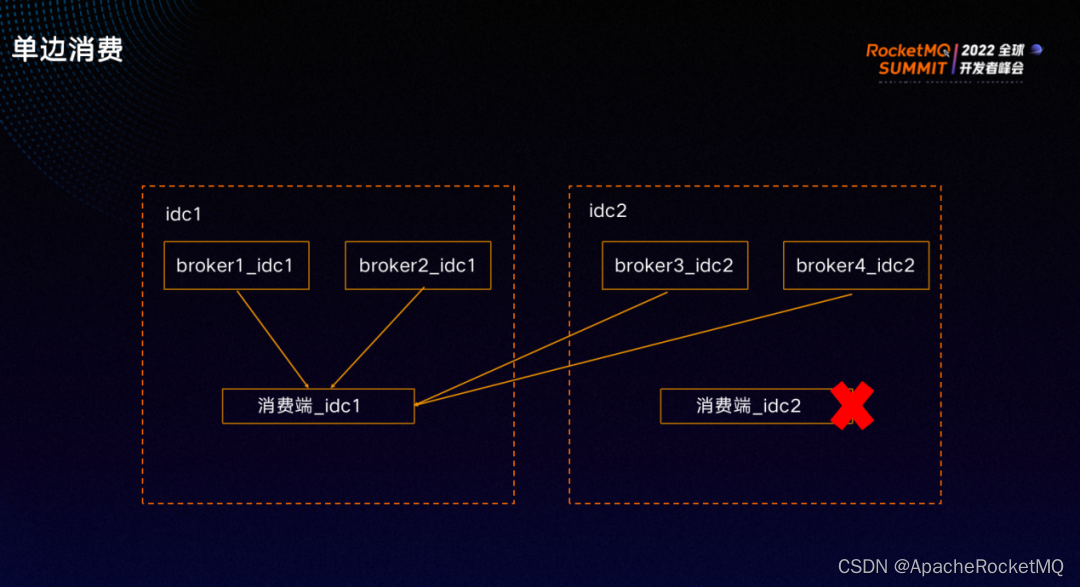
如上图,如果idc 2 的消费端全部故障,则所有消息会被另一个机房idc1的消费端消费。

为了实现就近消费,我们实现了按机房分配队列算法:
每个机房的消息会平均分给此机房的消费端;
如果机房没有消费端,则消息会平均分配给其他机房的消费端。
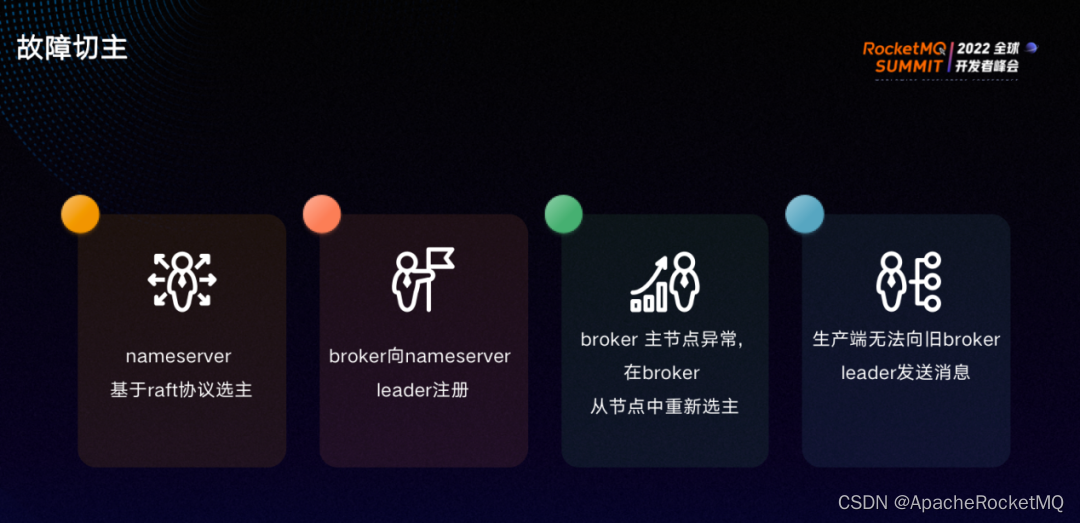
故障切主的实现步骤如下:
第一步:Nameserver 基于 raft 协议选主;
第二步:所有 broker 向 Nameserver leader 节点注册,leader 节点将 broker 的注册信息同步给其他 Nameserver 节点;
第三步:broker主节点出现异常时,由Nameserver 负责从剩下的 broker节点里重新选主节点;
第四步:此时生产端无法向旧broker leader发送消息。如果旧 broker的主节点复活,则会自动切换成从节点。

Nameserver 元数据系统有一主多从,broker 有一台 master 与两台 slave。如果 master 故障,则 Nameserver 元数据系统会从 slave1 与 slave2 中根据一定的条件,比如根据同步进度或版本号选出新主,上图为将 slave2 选为主。之后新主会向 nameserver 元数据系统注册,并将版本号+1。如果旧主复活,因会其版本号小于新主版本号被切为 slave。
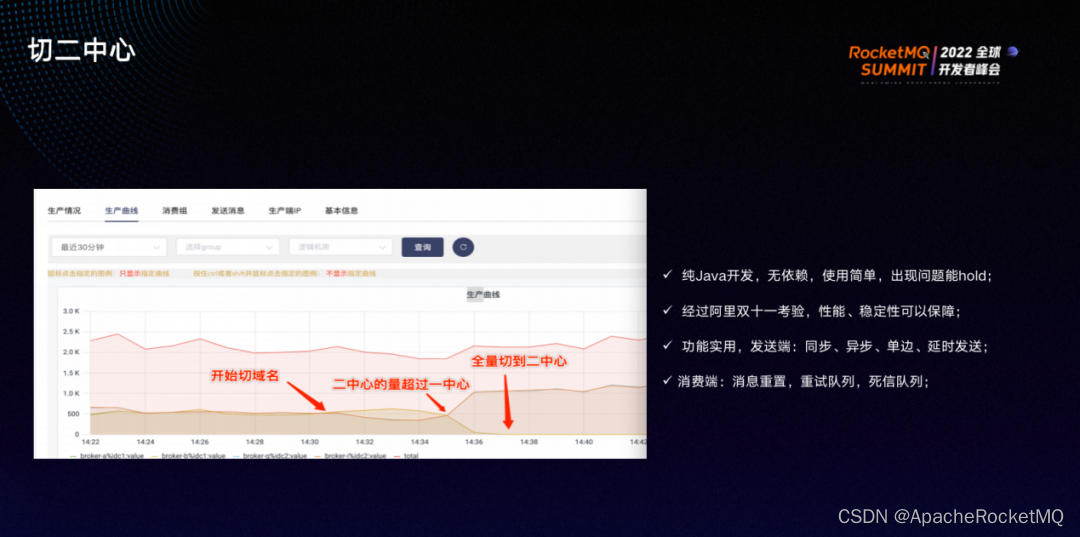
在生产环境中实际操作了双中心演练,具体流程如下:
1)14:30开始切域名,将流量切到一个机房(二中心)。三四分钟后,二中心的流量已超过一中心,一中心的流量趋近于零;
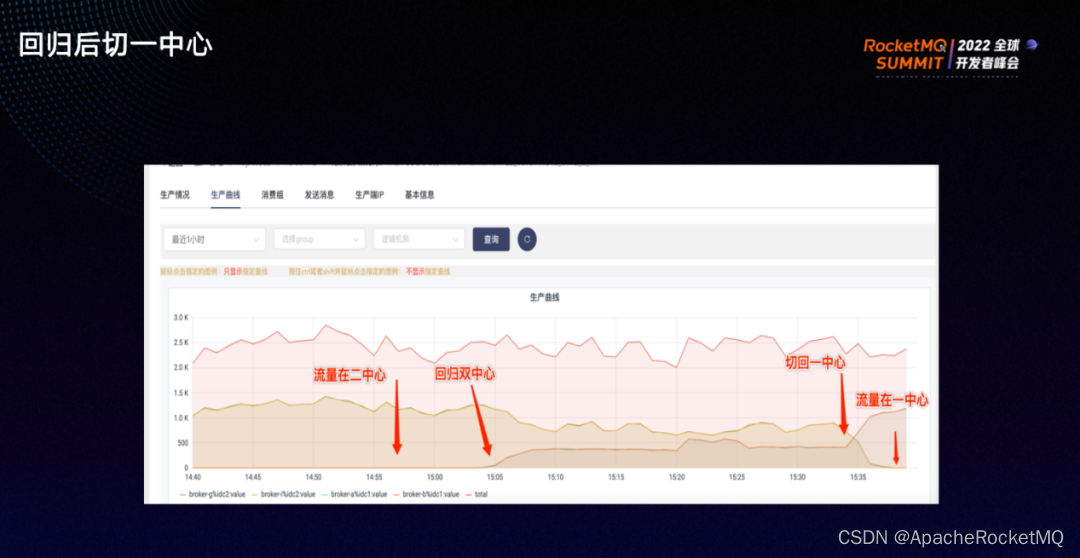
2)15:00左右,将流量回归双中心;
3)15:30左右,又将流量切回一中心。可以清晰地看到,在流量切到一中心时,二中心的消息生产趋近于0。
整体来看,双中心的演练较成功,实现了消息的生产跟着流量走。
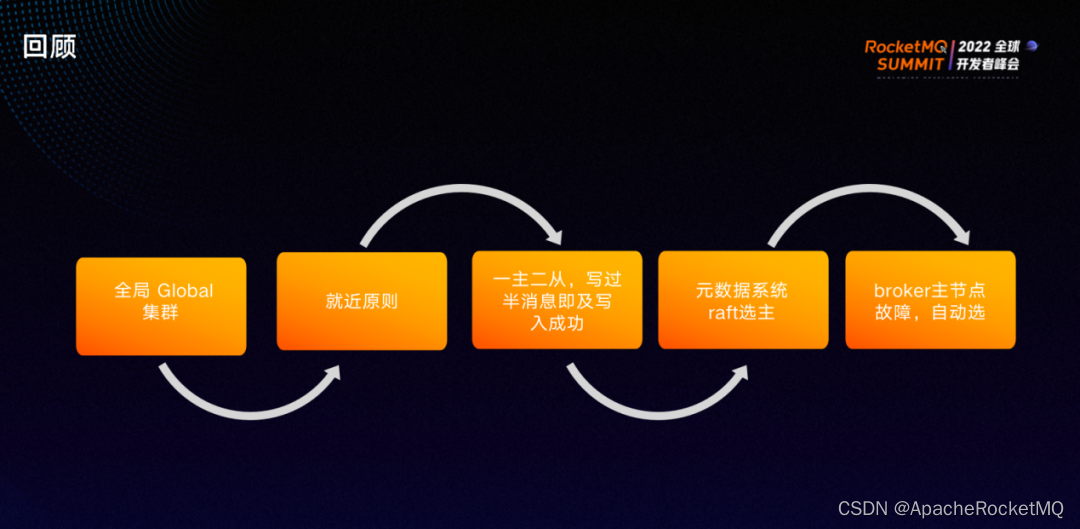
简单总结下,双中心方案为跨机房建立了全局MQ集群,生产与消费都遵守优先就近原则,配置一主二从,一主一从消息写成功即认为消息写入成功。Nameserver 通过 Raft 协议选主,选完主后会监控每一组里 broker 的 leader 节点。如果 broker 的 leader 节点出现故障,则会从这一组剩下的 slave 里选新的主节点。
03/平台治理
平台治理至关重要,可以让环境变得更加稳定可靠,出现异常时可以及时向使用方发出告警,出现故障时可以快速定位。MQ 的平台治理分为主题消费组治理、客户端治理以及服务端治理。

主题消费组的使用按照先申请后使用的原则,出现问题时可以根据主题与消费组的申请人找到该主题。MQ 环境分为很多种,可以一键申请所有环境或只限制生产环境的申请,将其他环境的申请放开。对于主题而言,我们给每一个主题限制了最大生产速度,防止单一主题生产过快从而影响其他主题的生产。
消息堆积到一定阈值时,可以向业务方发出告警,通知其处理;长时间不处理可以取消消费组的消费权限或重置消费进度,防止因消息大量堆积而影响生产与消费。若消费端节点掉线一定时间之后没有重新上线,可向业务方快速发布告警,通知其及时处理。

客户端治理主要执行一些统计与检测工作,会统计每一条消息的生产消费耗时、消息大小、重复消费的次数。如果生产/消费端版本过低或当前版本存在 bug ,也可以向业务端发出通知。
这一系列的统计和检测最终需要为消息的全链路追踪服务。统计和检测会记录消息相关信息,包括每一条消息在哪个时间点、从哪个业务IP与端口号发送到服务端的哪个节点、于什么时间被哪些服务的消费端在什么时间点消费,以及消费耗时、消费的重复次数等信息,可以很方便地排查所需信息。

服务端治理负责集群的自我保护、集群健康巡检、集群性能巡检和集群高可用。集群的自我保护主要针对生产与消费,尤其是生产的消息过快或有大量消息积压时;性能巡检可通过实时发送一批不同大小的消息来检测生产和消费的情况;集群的高可用指出现故障时,服务平台能及时发出通知。
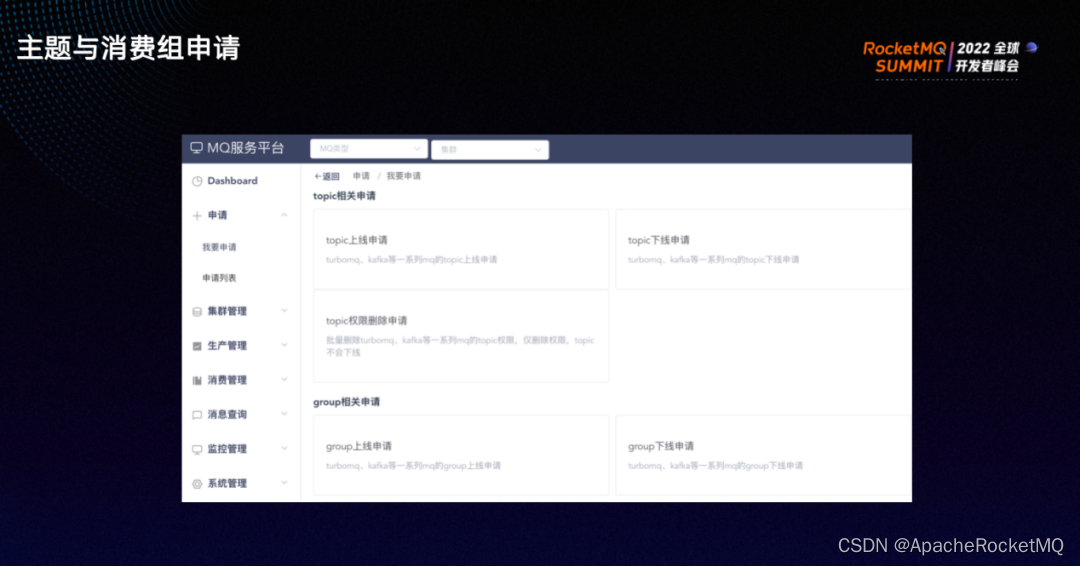
通过几张图展示下实际的治理,在 MQ 服务平台上,可以申请 topic 和消费组的上线、下线以及权限。
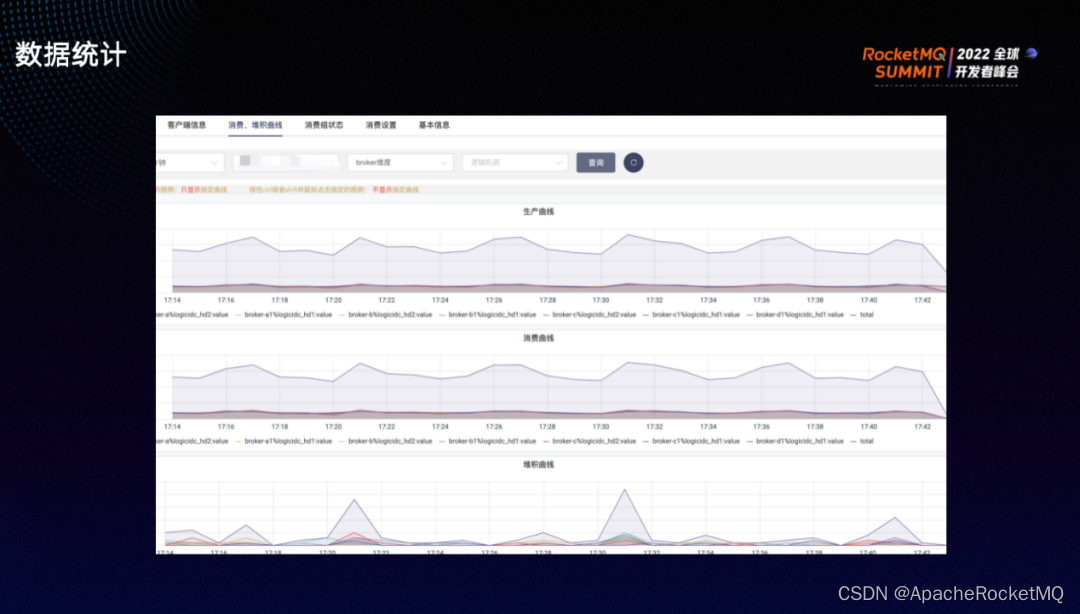
上图展示了每个集群每分钟的消息生产消费以及堆积曲线。
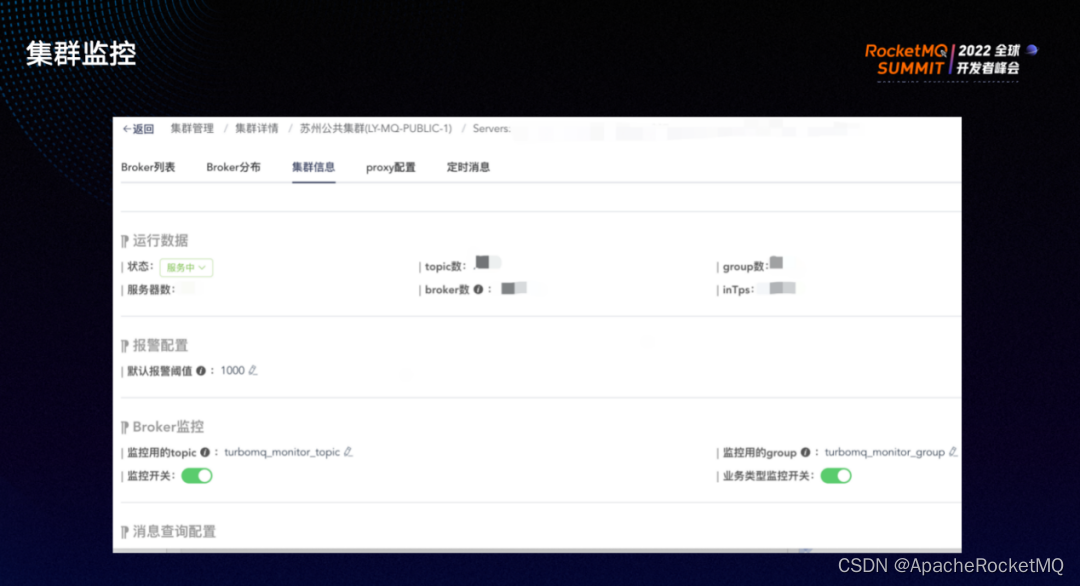
MQ 平台还提供了集群监控的功能,可以查看当前集群 topic 、消费组织数量、消息的intps、outtps 以及 broker 的数量。同时,可以查看每一台 broker 消息生产排名以及消息积压排名,方便故障时的问题排查。

使用 Rocket MQ 的过程中,我们也踩了不少坑。
1)做双中心版本升级时,没有考虑到版本的向下兼容,队列的分配算法有问题,导致部分消息被重复消费多次,部分消息没有被消费;
2)某一台 broker上主题消费组数量过多时,会导致 Nameserver 注册耗时过长。如果很多 broker 上的主题消费组都很多,就会导致broker的内存 OOM;
3)由于 topic 长度判断不一致导致服务端重启时会丢失少量消息;
4)broker 进程会假死,后证实为os版本问题,升级os版本即可解决。
04/未来展望

同程旅行针对 RocketMQ 的未来规划分为以下三个方面:
第一,历史数据归档。很多业务方对数据的反查要求周期较长,而线上生产环境的消息实际的存储时间可能只有2-3天,我们将考虑从历史归档数据里查询;
第二,底层存储剥离,计算与存储分离。目前社区新版本已经支持该能力;
第三,期望利用沉淀的历史数据帮助业务完成更多数据预测,比如订单量、退改量等数据的预测可以更好地帮助业务解决问题,同时也可以为业务机器做扩缩容提供支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号