操作系统学习笔记11 | 生磁盘的使用与管理
 这部分是设备驱动的最后一部分——磁盘管理,相较于上一篇的键盘和显示器要更复杂,但大致过程基本相同。磁盘管理共有4层抽象,我们将从此学习、掌握设备驱动的一般研究理念和设计方法。这部分先介绍前2层生磁盘的抽象。
这部分是设备驱动的最后一部分——磁盘管理,相较于上一篇的键盘和显示器要更复杂,但大致过程基本相同。磁盘管理共有4层抽象,我们将从此学习、掌握设备驱动的一般研究理念和设计方法。这部分先介绍前2层生磁盘的抽象。
这部分是设备驱动的最后一部分——磁盘管理,相较于上一篇的键盘和显示器要更复杂,但大致过程基本相同。磁盘管理共有4层抽象,我们将从此学习、掌握设备驱动的一般研究理念和设计方法。这部分先介绍前2层抽象。
参考资料:
-
课程:哈工大操作系统(本部分对应 L28)
因为太多了,所以磁盘管理4层抽象准备分成2~3篇来讲。
-
课本:《操作系统原理、实现与实践》-李治军、刘宏伟
2022-09-13,上了汇编与接口课,发现我校的外设驱动是在这个课上讲。
1. 磁盘工作原理
我们先让磁盘使用起来,后面再引入 “管理” 来让磁盘更好的被使用。
生磁盘就是指直接被驱动的磁盘,与之相应的,熟磁盘就是引入了文件系统抽象的磁盘。
1.1 生磁盘驱动原理的主干理解
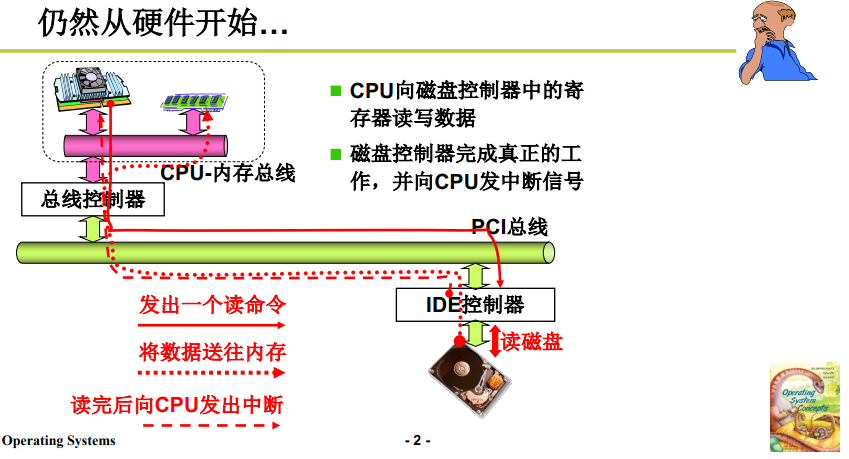
如下图所示,像上篇笔记所讲的外设一样,磁盘工作依然基于冯·诺依曼架构:
- CPU 通过 PCI 总线 发出 out 指令读写磁盘;
- 磁盘工作完后向 CPU 发出中断请求;
- 后续会将磁盘抽象为文件视图。
1.2 磁盘结构、容量和分类
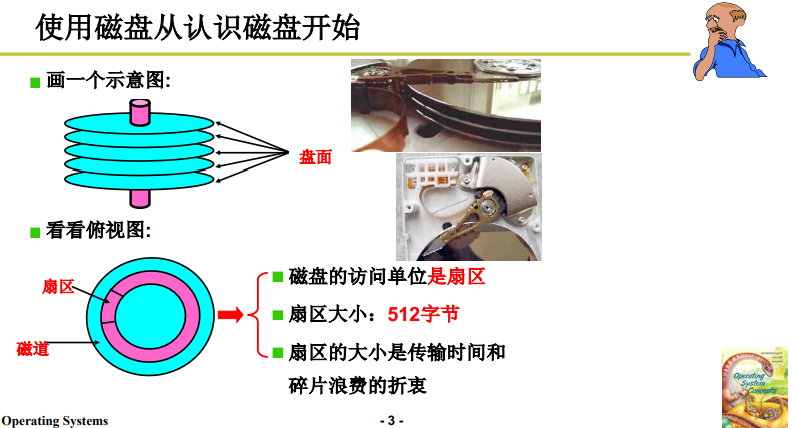
使用磁盘,当然要先理解磁盘的结构,如下图所示:
-
磁盘是由一个柱子串起很多盘片而组成的立体结构,像一个糖葫芦串;每个盘面都由许多磁道组成,盘片上下两面都是可读写的;
硬盘又划分为磁头(Heads)、柱面(Cylinder)、扇区(Sector);
-
磁盘的访问单位是扇区,即每次读写的最小磁盘单元;
-
扇区大小是 512 字节;
-
硬盘容量=磁头数(同一柱面上的磁片数)×柱面数×扇区数×512 字节
-
设计磁盘时,扇区大小是访问时间和碎片浪费的折衷考虑
这个后续会提。
-
-
学到后面的补充:柱面是什么?
- 所有盘面中相对位置相同的磁道组成柱面,即同一圈空心圆柱体。
- 我们后面所说的寻道,与寻找柱面等价。
-
旋转时,利用电流的磁效应,对一些电信号进行磁化,保存在磁盘中,用来存储一些信息;同样的,将磁信号转化为电信号,就可以读出磁盘信息。
磁盘的物理原理,详见:磁盘原理:从电磁感应说起
现行磁盘可以作如下分类:
-
固态硬盘盘
-
SSD,Solid State Disk 或 Solid State Drive;
-
SSD 不算是磁盘,实际上是一种闪存固态硬盘,其工作原理应当参见 Flash;固态硬盘能够实现随机存储,控制逻辑与机械磁盘完全不一样;
-
下面讨论的磁盘工作原理也是机械硬盘的。
参考资料:机械硬盘和ssd固态硬盘的原理对比分析,这篇笔记很详细。
-
-
机械磁盘
- 根据磁头是否可以移动
- 固定头磁盘(每个磁道有一个磁头)
- 移动头磁盘(每个盘面有一个磁头)
- 这里我们介绍的是移动头磁盘;
- 根据盘面是否可更换
- 固定盘磁盘;
- 可换盘磁盘;
- 根据磁头是否可以移动
1.3 磁盘的 I/O 过程
1.3.1 读写磁盘
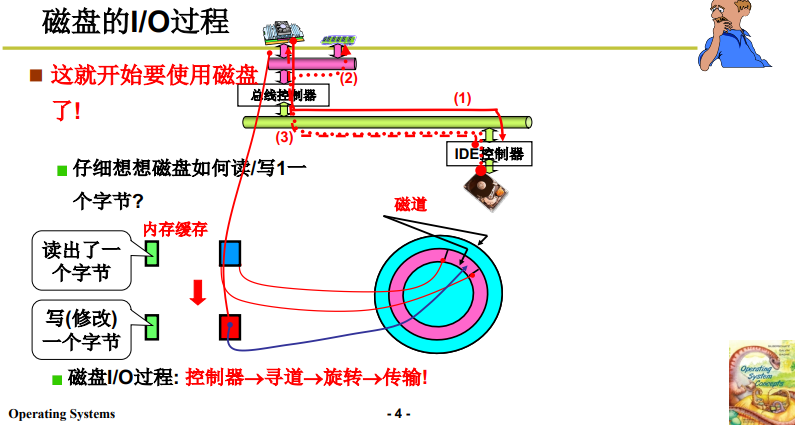
读取磁盘信息时,比如读取磁盘中的一个字节:
- 首先是将磁头移动到指定的磁道上,此时磁头不通电(磁片一直有磁);
- 磁道开始旋转,转到目标位置 / 目标扇区时,磁生电,磁信号变为电信号,就通过磁头导回内存缓冲区;
- =👆读,写👇===
- 读入内存后,我们就可以结合前面的内存管理,程序修改其中的值,比如修改此时读入的 1 字节数据;
- 修改后的数据再导回磁盘,仍然是转动,但此时是电生磁,就将电信号/数据写入磁盘。
小总结:
- 移动磁头到磁道->旋转磁盘到扇区->电磁读写;
- 控制器、寻道、读写、数据传输;
1.3.2 物理过程
注意这里的讲的磁盘工作方式都是 机械磁盘,基本原理就是电磁感应,能用到这一点真的是很厉害的设计。
-
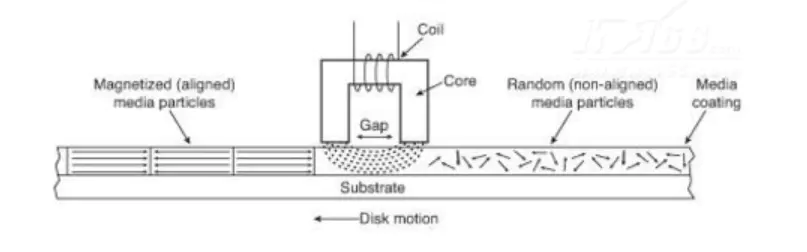
磁头:如下图所示,磁头是一个外面被线圈缠绕着的U型磁芯,可以看出当磁头通电时便会产生磁场,磁场的方向随电流方向的变化而变化。
-
磁盘:磁盘的表面涂有一层磁性物质,在未没有外部磁场影响的情况下,磁盘表面的磁性粒子的磁极方向是不会改变的。
一般从未受到外部干扰的磁性粒子磁极方向是随机的,于是出现互相抵消的情况,这时磁盘的表现出无磁极显现。
-
数据在磁盘上就是一些磁极方向不同的微小局部区域;
-
读取:
- 不通电的磁头在写入数据的位置上移动,数据在磁盘上就是一些磁极方向不同的微小局部区域;
- 由于各个域的磁极方向不完全相同,所以磁头在通过这些不同方向的区域时会产生不同方向的感应电流;
- 这些微弱正负脉冲电流,经过 驱动/控制器 的 去噪、扩大 成为内存中的二进制数据。
-
写入:
- 写数据时磁头移到到磁盘要写入的位置,输入 电流 / 电信号 产生感应磁场,电生磁;
- 受磁场的影响,磁头下磁性粒子的磁极方向变为与磁场同向。通过给磁头不同的电流方向,使得磁盘局部产生不同的磁极;而这种局部磁极的特性,就是磁盘存储数据的方式;
- 产生的磁极在未受到外部磁场干扰下是不会改变的。通过这种方式就将 电信号 / 数据 持久化到磁盘上。
当然也并不是一个磁极方向代表1另一个代表0
在硬盘读写时,读操作远快于写操作,并且磁盘的 读/写操作 具有完全不同的特性,所以目前的硬盘一般都设计 读和写 两个磁头,但是原理还是上面的原理。
1.3.3 简单总结
由上述相关内容可知,上层只需要向下传递几个参数即可控制整个过程:
-
第几柱面;
因为磁盘那么大,不一定只有一个糖葫芦串;
-
第几磁头;
决定是第几个盘面 / 糖葫芦串上的第几个糖葫芦;
-
第几磁道;
寻道,需要知道是盘面上的哪一个圆环;
-
第几扇区;
旋转寻找扇区,需要知道是圆环的哪一个弧形区域;
-
读出 还是 写入;
决定执行的操作
-
读到哪个缓存位置 / 从哪个缓存位置写入;
可以使用 DMA 总线盗用技术,完成磁盘和内存之间的数据交流。
根据这些参数(柱面号、盘面号、扇区号),磁盘控制器 就可以 自动驱动相关机构 去执行。生磁盘的驱动也不过就是将这些参数写到磁盘控制器上,也就是 OUT 指令。

2. 0层抽象:使用磁盘的直观方法
直观方法就是如上面1.3.3 的总结中所想的思路,拿到这些参数,就可以让磁盘控制器如我们预期的工作。
2.1 读写请求
代码图片在 1.3.3 中,首先是磁盘读写的请求函数 do_hd_request(),将参数传递给磁盘控制器。
void do_hd_request(void)
{
.....
//得到dev,nsect,sec,head,cyl,WIN_WRITE,&write_intr 参数
// dev 控制器,nsect 读写几个扇区,cyl 柱面,head 磁头,sec 扇区,WIN_WRITE 写,&write_intr 缓存位置
//传递给磁盘控制器
if (CURRENT->cmd == WRITE) {
hd_out(dev,nsect,sec,head,cyl,WIN_WRITE,&write_intr);
for(i=0 ; i<3000 && !(r=inb_p(HD_STATUS)&DRQ_STAT) ; i++)
/* nothing */ ;
if (!r) {
bad_rw_intr();
goto repeat;
}
port_write(HD_DATA,CURRENT->buffer,256);
} else if (CURRENT->cmd == READ) {
hd_out(dev,nsect,sec,head,cyl,WIN_READ,&read_intr);
} else
panic("unknown hd-command");
}
2.2 磁盘驱动
接着是 磁盘驱动的核心代码 hd_out(),将上述参数放到端口上,并将相关信息按照要求拼接起来,所以有一些移位,并且得到读写的内存缓冲区:
static void hd_out(unsigned int drive,unsigned int nsect,unsigned int sect,
unsigned int head,unsigned int cyl,unsigned int cmd,
void (*intr_addr)(void))
{
register int port asm("dx");
if (drive>1 || head>15)
panic("Trying to write bad sector");
if (!controller_ready())
panic("HD controller not ready");
// 计算缓存地址
do_hd = intr_addr;
outb_p(hd_info[drive].ctl,HD_CMD);
port=HD_DATA; //数据寄存器端口(0x1f0)
//outb_p 接口就是向外设传送数据的
//这就是cpu中磁盘驱动的核心代码
outb_p(hd_info[drive].wpcom>>2,++port);
outb_p(nsect,++port);
outb_p(sect,++port);
outb_p(cyl,++port);
outb_p(cyl>>8,++port);
outb_p(0xA0|(drive<<4)|head,++port);
outb(cmd,++port);
}
2.3 简单总结
这样使用很简单直接,但是需要传递的参数太多了,如果使用这种直接使用的方案,这些参数都是需要上层传递给磁盘控制器的,太麻烦了。如果我们只给出要访问的磁盘位置(一个数 / 也就是磁盘块),由操作系统自动解算柱面、磁头、磁道、扇区、扇区个数,这样就会方便很多。
既然 0 层抽象不便使用,这就引出了第 1 层抽象。
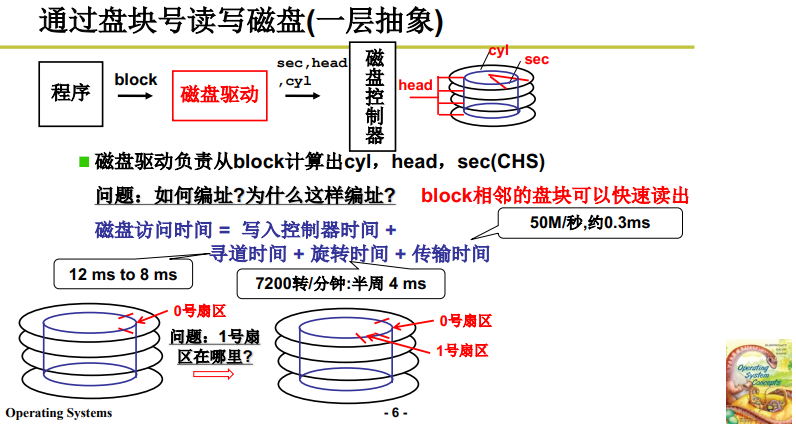
3. 第1层抽象:盘块号读写磁盘
用上文知,第 1 层抽象 将柱面、磁头、扇区包装成一个磁盘块,上层用户只需向下传递磁盘块,磁盘驱动从 磁盘块 / block 解算出 CHS。
这涉及一维地址编址三维空间,下面看看如何编址。
- CHS: cyl 柱面,head 磁头,sec 扇区。
- 注意:CHS可以定位一个柱体里的任意位置,这里就是大学物理、高数提到过的柱面坐标系;
- 这样封装,也是设计模式的 adapter 模式。可以让用户使用磁盘更加简单、高效。
3.1 盘块号编址三维空间
基于一个常见事实,即对于 磁盘块的访问/读写 通常是连续的,我们会希望一个 block块 的相邻盘块可以快速读出。
为了达到这一效果,我们首先需要分析一下0层抽象时的磁盘访问时间,看看哪部分浪费时间最多。如下图中间所示:
- 磁盘访问时间 = 写入控制器时间 + 寻道时间 + 旋转时间 + 传输时间;
- 可见,大多数时间被用来 寻道。也即磁头在半径方向上的移动很慢,而旋转和信号传递的过程更快。
所以,我们连续访问相邻的磁盘块,应当减少相邻的磁盘块访问的寻道时间,即,将相邻磁盘块放在同一磁道上。
- 磁盘块是一个操作系统层次的抽象概念,操作系统与磁盘之间交流的最小单位就是磁盘块,而磁盘上的物理最小单位是扇区。
- 操作系统可以设置磁盘块对应多少个扇区。
- 相邻磁盘块放在同一磁道上不准确,应当是相邻磁盘块应当尽量对应同一磁道上的扇区,如若不然,那也尽量方便访问。
磁盘层面 具体扇区放置方式 如下图的下半部分所示:
-
1号扇区 在 0号扇区 旋转方向的下一扇区;
-
假设一个盘面有 7 个扇区,则 0-6 扇区在第一个盘面,7 号扇区就在 0 号扇区 **竖直方向的下个盘面/第2个盘面 **的对应扇区;
也即 0号扇区的正下方,这是因为不同盘面的磁头是一同旋转的(同一磁臂),第一个盘面的磁头旋转到6号扇区的末尾时,第二个盘面的磁头也正好到达7号扇区。
按照上面的扇区安排顺序(也就是编址方式),扇区号 LBA 用公式表示为:
-
\[LBA = C × (Heads × Sectors) + H × Sectors + S \]
LBA 是扇区的编号, 按照柱面、磁头和磁道从小到大的顺序对扇区编号。这里理解每个磁道上的扇区数量是一样的(实际上会有所差别)。
-
C 是 柱面, H 是盘面,S是扇区;
-
意思就是已经走过了多少柱面个扇区,多少磁面个扇区,以及同一磁面上已经过的多少扇区。
-
可见磁盘寻址是基于扇区的。上式得到的就是从0柱面开始编址的扇区号,也就得到了 LBA。
而反过来由 扇区号LBA 反推 CHS,也很好做:
- S = LBA % Sectors;(取余)
- H = (LBA / Sectors) % Heads;
- C = LBA / Sectors / Heads;
到这里,通过编址建立了从 CHS 扇区地址到扇区号的一个映射,也建立了从 扇区号LBA 到 CHS 的反向计算方法;这就是第1层抽象的核心任务。
而我们反复提到过,扇区号连续的多个扇区就是一个磁盘块。到了这一步,操作系统就能通过用户请求的磁盘块来自动解算访问磁盘对应扇区。
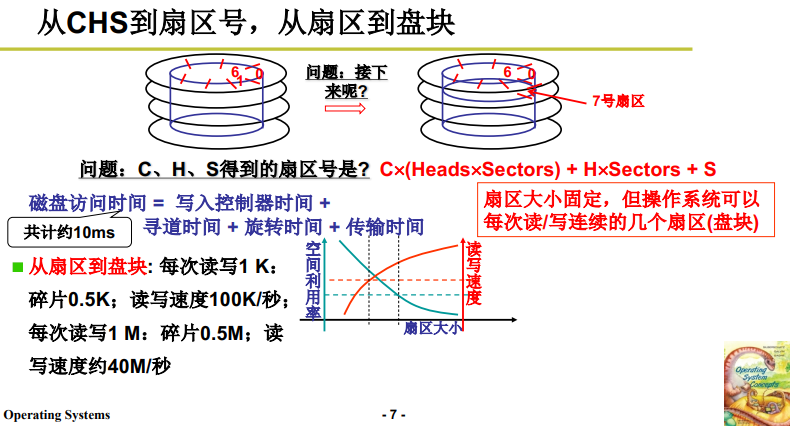
下面分析一下 第1层抽象 对于磁盘访问时间上的节省情况,如上图下半部分所示:
- 磁盘的访问时间 = 写入控制器时间 + 寻道时间 + 旋转时间 + 传输时间;
- 操作系统可以每次读写一个盘块:
- 每次读写1 K: 碎片0.5K;读写速度100K/秒;
- 每次读写1 M:碎片0.5M;读写速度约40M/秒
这里的数字意义不大,只是理解:
-
如果盘块/扇区的大小变大,读写速度变大
因为节省了寻道时间。
-
但是大小变大不是没有上限的,读写的单位空间越大,浪费空间也越大(碎片),空间利用率低;
因为可能所需要的只有0.5M,但是读取单位是1M,读进来 1M 就会有 0.5M 浪费。
-
这里体现了 空间和时间 的折衷。
但是现代存储技术不断发展,大磁盘已经广泛应用,但是磁盘的寻道、旋转时间方面没有很大的提升。因此浪费的空间可以稍微多一些,以此减少寻道时间 来换取 更快的磁盘读写速度。
3.2 代码实现
简单总结一下上述的第1层抽象:
- 上层用户在程序中请求磁盘块;
- 操作系统根据自身设置(一个磁盘块对应多少扇区),换算为需要读取的连续扇区;根据LBA和CHS的换算,解算出磁盘中扇区地址;
- 操作系统将发送给磁盘控制器,访问/读写 对应扇区;
可见抽象在于,通过操作系统将磁盘扇区地址封装为磁盘块,用户只需要通过请求盘块号 blocknr 即可访问磁盘。这层抽象做到了既简单又高效。
下面就可以通过磁盘号读写磁盘:
static void make_request()
{
struct requset *req;
req=request+NR_REQUEST;
//用 盘块号block 计算 扇区号sector
req->sector=bh->b_blocknr<<1;
//根据 扇区号sector 计算扇区地址
add_request(major+blk_dev,req);
}
void do_hd_request(void)
{
unsigned int block=CURRENT->sector;
//下面就是除法跟取余,计算 chs
__asm__(“divl %4”:”=a”(block),”=d”(sec):”0”(block),
“1”(0),”r”(hd_info[dev].sect));
__asm__(“divl %4”:”=a”(cyl),”=d”(head):”0”(block),
“1”(0),”r”(hd_info[dev].head));
//输出对应位置的扇区,这是第0层抽象的内容
hd_out(dev,nsect,sec,head,cyl,WIN_WRITE,...);
...
}
据上面代码也可以推知:Linux 0.11设置的盘块的大小是1K(左移了一位,代表盘块和扇区换算单位是2),也就是两个扇区。
3.3 参考资料
-
如果不理解磁盘块和扇区,参考资料:
- 计算机存储术语: 扇区,磁盘块,页
- 磁盘块与扇区的区别和联系_
- 这一点我已经在 3.1 中给了比较精要的理解。
-
如果不了解 编址方式,参考资料:
-
机械硬盘LBA和CHS,课程没有讲,1层抽象就是 LBA( LBA就是扇区的编号,物理扇区号)。
课程中讲解LBA与CHS的解算时(3.1部分),用的直接是block/盘块,我觉得不合适,应当是LBA扇区号,然后扇区号和磁盘块有对应关系。
-
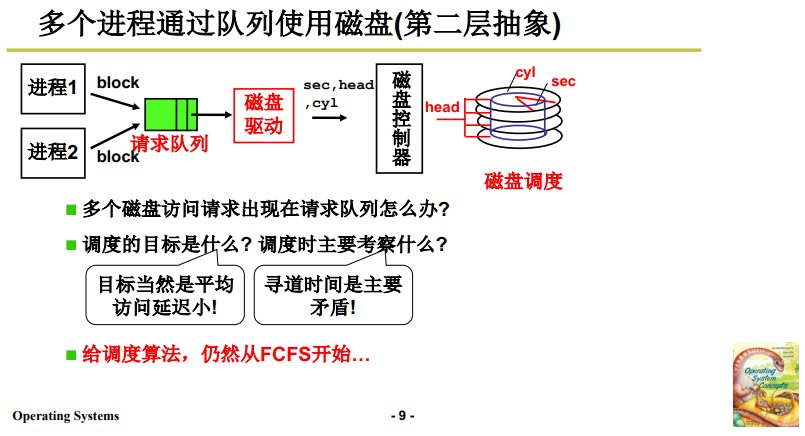
4. 第2层抽象:多进程通过队列使用磁盘
第 1 层抽象中,我们屏蔽了底层磁盘的参数,上层用户程序只需要发出盘块号给操作系统处理就可以了。
但是实际操作系统中,一般有多个进程,每个进程都会提出磁盘块访问请求,这时需要用队列来管理多进程的磁盘访问请求,这就是操作系统对磁盘管理的第2层抽象。
4.1 第2抽象层描述
第2层抽象的核心是:当多个磁盘访问请求出现在请求队列,需要对磁盘进行适当的调度。
当磁盘中断时,再从请求队列中调度下一个磁盘访问请求。如下图所示。此时仍使用盘块号,还是生磁盘,还没有引入文件的抽象。
在这层抽象中,由于涉及选择、调度的问题,所以又需要相关调度算法的支撑。调度算法目标:平均延迟小。由于调度主要考虑时间,所以寻道时间还是主要优化的方面。
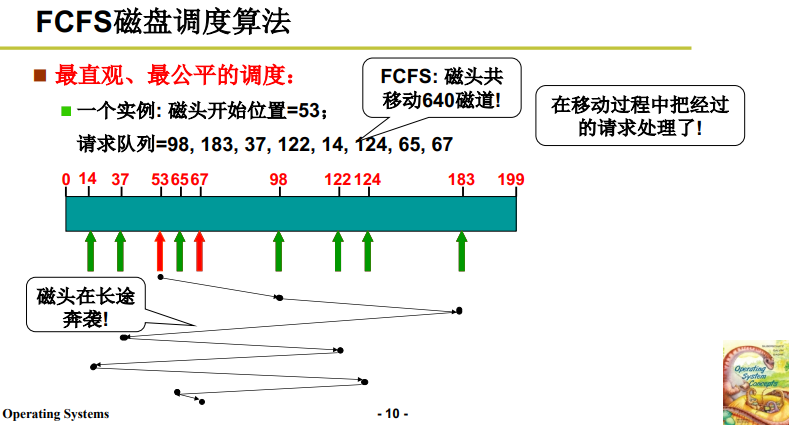
4.2 调度算法1:FCFS
还是从最简单的 算法/想法 开始,First Come First Serve。这也最公平、最直观。
- 如下图例子:磁头的起始位置为 53,而请求队列的磁盘请求起始位置也如下图所示;
- 可以料想磁头长途奔袭,而磁头移动恰恰就是寻道时间,移动的多了时间就变长了。此算法磁头移动了640个磁道。
4.3 调度算法2:SSTF
短寻道优先 Shortest-seek-time First。基于上面的一种强烈感受:再遇到65请求时,直接顺便把67请求也给执行了,这样就不必来回跑了。
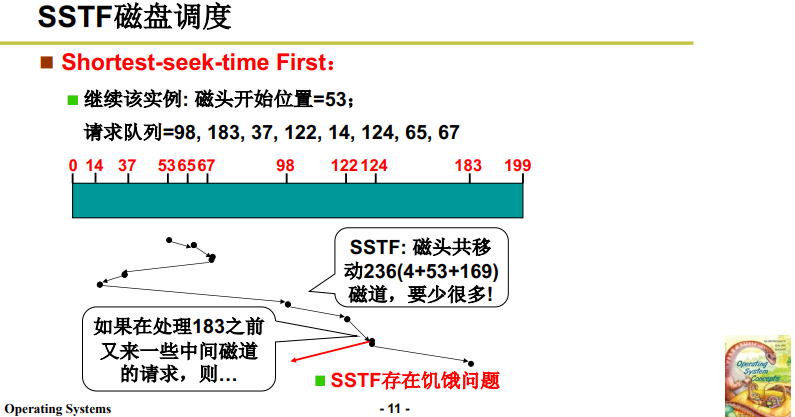
可见经过这样的优化,磁头移动236个磁道,较于调度算法1FCFS要好很多。
但是这种算法也有问题:
- 磁盘请求总是不断地到来,由于这种算法的局部性,存在插队可能性;
- 位置偏远的磁盘请求可能早都到达了,但是一直没有响应;
- 这就造成了 饥饿问题。
4.4 调度算法3:SCAN磁盘调度
SCAN磁盘调度 = SSTF+中途不回折,也叫电梯算法。既然SSTF存在局部震荡性,那么约束其先沿一个方向访问完所有的磁盘请求再掉头,就不会漏下一些偏远的磁盘请求。(这也很像一个电梯。)
可见磁头移动 236 次,与 SSTF 齐平;既保证了公平,也保证了效率。
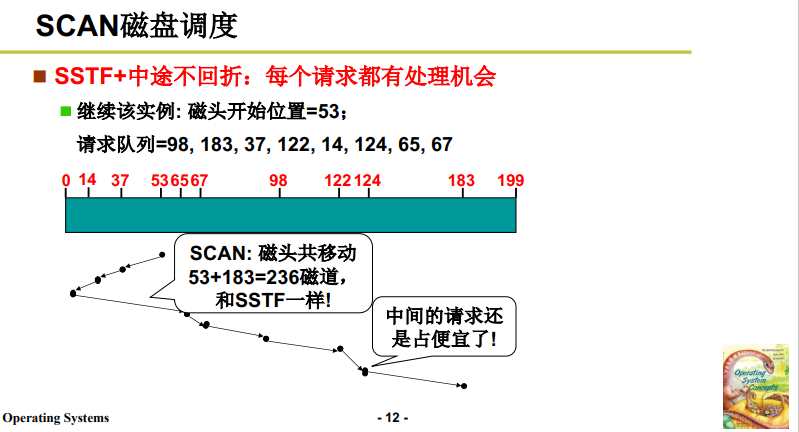
但是还是有一点点问题:由于折返跑的形式,中间的磁盘请求还是比较沾光。所以考虑磁头到头之后直接复位再滑动,见下一种调度算法:
4.5 调度算法4:C-SCAN磁盘调度
这是操作系统中真实使用的算法,也是电梯算法(可戏称为跳楼机)。
其思路就是只单向寻道,到头后直接复位再次沿同方向寻道,这样对于所有磁盘位置的请求都是公平的。

4.6 C-SCAN 代码实现
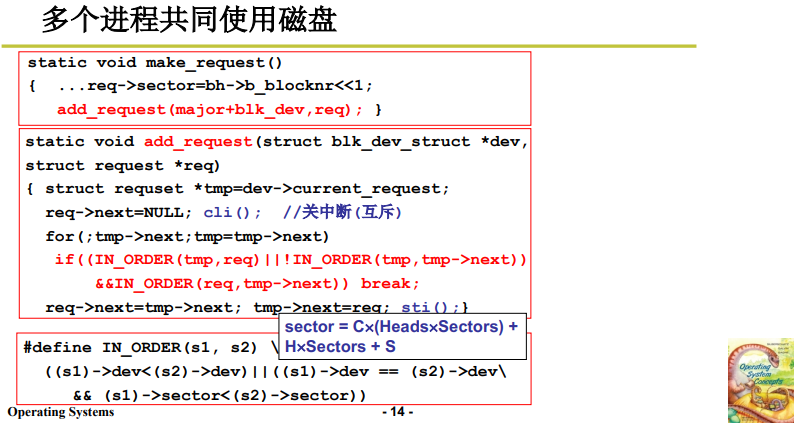
首先是 make_request 多进程产生磁盘访问请求:
static void make_request(){
...
//根据用户发来的盘块号换算为扇区号
req->sector = bh -> b_blocknr << 1;
//将请求放入请求队列
add_request(major+blk_dev,req);
}
将磁盘访问请求按照电梯算法放入请求队列,使用的是 add_request 函数,由于是多进程都在访问这个请求队列,所以需要加上锁 / 临界区进行保护:
锁和临界区的概念参见:操作系统学习笔记7 | 进程同步与合作 - climerecho - 博客园 (cnblogs.com)
// linux-0.11/kernel/blk_drv/ll_rw_blk.c
static void add_request(struct blk_dev_struct * dev, struct request * req){
struct request * tmp = dev->current_request;
//请求队列
req->next = NULL;
// 开启临界区保护
cli();
if (req->bh)
req->bh->b_dirt = 0;
if (!(tmp = dev->current_request)) {
dev->current_request = req;
sti();
(dev->request_fn)();
return;
}
/*
当符合以下两种情况时就跳出循环,并将req 插入tmp和next之间
(1)当tmp的扇区号小于req的扇区号,且req小于next的扇区号
这种是正常定向扫描
(2)当tmp的扇区号小于next的扇区号,且req小于next的扇区号
这种是折回从头处理
符合上述条件其一,下一步磁盘读写(目前在tmp上)都会进入req这个对象上;
否则就按照原有的,队列进行磁盘读写,这样就实现了电梯队列
*/
for ( ; tmp->next ; tmp=tmp->next)
//这几句是核心代码:磁盘请求按跳楼机算法放入队列
if ((IN_ORDER(tmp,req) ||
!IN_ORDER(tmp,tmp->next)) &&
IN_ORDER(req,tmp->next))
break;
req->next=tmp->next;
tmp->next=req;
sti();
}
接着是按照跳楼机算法 C-SCAN 将磁盘请求放入请求队列,这里需要先比较两个磁盘请求的柱面号大小(换算后):
/*
核心思想是比较s1与s2中的sector扇区号大小,也就是比较s1与s2中的柱面号的大小
因为柱面的寻找是耗时最长的,所以要保证
寻找柱面也即寻道的时间不能太长,就要在
寻道上面做优化处理
*/
#define IN_ORDER(s1,s2) \
((s1)->cmd<(s2)->cmd || ((s1)->cmd==(s2)->cmd && \
((s1)->dev < (s2)->dev || ((s1)->dev == (s2)->dev && \
(s1)->sector < (s2)->sector))))
5. 生磁盘层次抽象管理的梳理
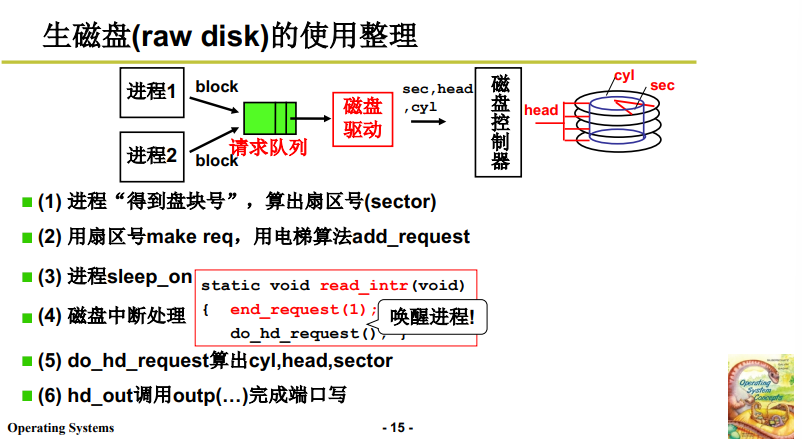
至此,生磁盘层面的两层抽象就讲完了,连起来就是:
-
多进程“得到盘块号”,计算出扇区号。
- 至于这里的盘块号怎么得到,就是下面 文件系统的工作!
- 生磁盘假定盘块号已知 / 由用户给出。
-
得到起始扇区号,访问磁盘产生请求(make_request),将其按照电梯算法放到请求队列中(add_request);
注意,此处 make_request 也涉及了内存缓冲区的申请,此处代码使用了很多优化技巧,但此处不细讲这段代码了。
-
放入请求队列后,请求访问磁盘的进程睡眠 / 切到睡眠队列,因为接下来也是外设的工作了。这也是多进程同步合作的一个例子。
-
磁盘中断,处理磁盘请求,调用 do_hd_request;
具体代码见2.1.
-
do_hd_request 将 磁盘请求 / 扇区号 换算为CHS;
-
用 hd_out 将CHS发给相应的磁盘控制器,启用总线进行磁盘读写。
-
完成读写工作后,进行中断处理,结束请求,唤醒相应进程,此时内存中就有该进程需要的数据了,进程继续工作。
接上后面的文件系统、目录,使用磁盘的完整图像就完成了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号