网络爬虫_BeautifulSoup库入门
一、Beautiful Soup库的基本元素
1.Beautiful Soup库的理解
<p>..</p>: 标签:Tag <p> p指的是标签的名字, Name成对出现 <p class="title">...</p> 属性Attributes0个或多个(由键值对构成)
2.Beautiful Soup库的引用
引用方式
from bs4 import BeautifulSoup
使用方法
from bs4 import BeautifulSoup
1. soup = BeautifulSoup("<html>data<html>", "html.parser")
2. soup = BeautifulSoup(open("D://demo.html"), "html.parser")
BeautifulSoup对应一个HTML/XML文档的全部内容。
4.Beautiful Soup库解析器
soup = BeautifulSoup('<html>data</html>','html.parser')
分类
解析器 使用方法 条件 bs4的HTML解析器 BeautifulSoup(mk,'html.parser') 安装bs4库 lxml的HTML解析器 BeautifulSoup(mk,'lxml') pip install lxml lxml的XML解析器 BeautifulSoup(mk,'xml') pip install lxml html5lib的解析器 BeautifulSoup(mk,'html5lib') pip install html5lib
5.Beautiful Soup类基本元素
<p class=“title”> … </p>
分类
基本元素 说明 Tag 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾 Name 标签的名字,<p>…</p>的名字是'p',格式:<tag>.name Attributes 标签的属性,字典形式组织,格式:<tag>.attrs NavigableString 标签内非属性字符串,<>…</>中字符串,格式:<tag>.string Comment 标签内字符串的注释部分,一种特殊的Comment类型
6.具体使用代码
1. 回顾demo.html
import requests url2 = "http://python123.io/ws/demo.html" r = requests.get(url2) demo = r.text print(demo) 打印输出 # print(demo) <html><head><title>This is a python demo page</title></head> <body> <p class="title"><b>The demo python introduces several python courses.</b></p> <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p> </body></html>
2. Tag 标签
Tag 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾
任何存在于HTML语法中的标签都可以用soup.<tag>访问获得
当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个
from bs4 import BeautifulSoup import requests url = "http://python123.io/ws/demo.html" r = requests.get(url) demo = r.text soup = BeautifulSoup(demo, "html.parser") print(soup.title) tag = soup.a print(tag) 打印输出 # print(soup.title) <title>This is a python demo page</title> # print(tag) <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
3. Tag的name(名字)
Name 标签的名字,<p>…</p>的名字是'p',格式:<tag>.name
每个<tag>都有自己的名字,通过<tag>.name获取,字符串类型
from bs4 import BeautifulSoup import requests url2 = "http://python123.io/ws/demo.html" r = requests.get(url2) demo = r.text soup = BeautifulSoup(demo, "html.parser") print(soup.a.name) print(soup.a.parent.name) print(soup.a.parent.parent.name) 打印输出 # print(soup.a.name) 'a' # print(soup.a.parent.name) 'p' # print(soup.a.parent.parent.name) 'body'
4. Tag的attrs(属性)
Attributes 标签的属性,字典形式组织,格式:<tag>.attrs
一个<tag>可以有0或多个属性,字典类型
from bs4 import BeautifulSoup
import requests
url2 = "http://python123.io/ws/demo.html"
r = requests.get(url2)
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
tag = soup.a
print(tag.attrs)
print(tag.attrs['class'])
print(tag.attrs['href'])
print(type(tag.attrs))
print(type(tag))
打印输出
# print(tag.attrs)
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
# print(tag.attrs['class'])
['py1']
# print(tag.attrs['href'])
http://www.icourse163.org/course/BIT-268001
# print(type(tag.attrs))
<class 'dict'>
# print(type(tag))
<class 'bs4.element.Tag'>
5. Tag的NavigableString
NavigableString 标签内非属性字符串,<>…</>中字符串,格式:<tag>.string
NavigableString可以跨越多个层次
from bs4 import BeautifulSoup import requests url2 = "http://python123.io/ws/demo.html" r = requests.get(url2) demo = r.text soup = BeautifulSoup(demo, "html.parser") soup.a print(soup.a.string) print(soup.p) print(soup.p.string) print(type(soup.p.string)) 打印输出 # print(soup.a.string) Basic Python # print(soup.p) <p class="title"><b>The demo python introduces several python courses.</b></p> # print(soup.p.string) The demo python introduces several python courses. # print(type(soup.p.string)) <class 'bs4.element.NavigableString'>
6. Tag的Comment
Comment 标签内字符串的注释部分,一种特殊的Comment类型
Comment是一种特殊类型
from bs4 import BeautifulSoup import requests demo = "<b><!--This is a commet--></b><p>This is not a comment</p>" newsoup = BeautifulSoup(demo, "html.parser") print(newsoup.b.string) print(newsoup.p.string) print(type(newsoup.p.string)) 打印输出 # print(newsoup.b.string) This is a commet # print(newsoup.p.string) This is not a comment # print(type(newsoup.p.string)) <class 'bs4.element.NavigableString'>
二、基于bs4库的HTML内容遍历方法
1.回顾demo.html
import requests url = "http://python123.io/ws/demo.html" r = requests.get(url) demo = r.text print(demo)
输出的demo内容(HTML基本格式)
<html>
<head>
<title>This is a python demo page</title>
</head>
<body>
<p class="title">
<b>The demo python introduces several python courses.</b>
</p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and
<a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.
</p>
</body>
</html>
2.标签树的三种遍历方法

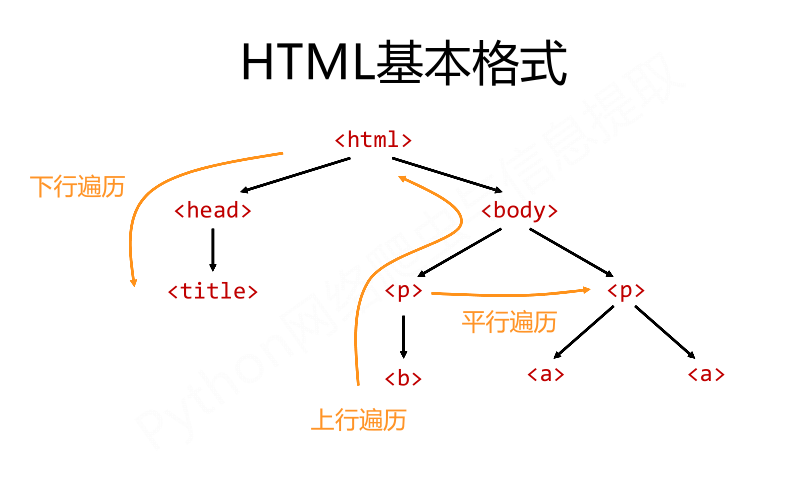
3. 标签树的下行遍历
3.1) 下行遍历的属性 BeautifulSoup类型是标签树的根节点
属性 说明 .contents 子节点的列表,将<tag>所有儿子节点存入列表 .children 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 .descendants 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
3.2)下行遍历代码
import requests from bs4 import BeautifulSoup url = "http://python123.io/ws/demo.html" r = requests.get(url) demo = r.text soup = BeautifulSoup(demo, "html.parser") print(soup.head) print(soup.head.contents) print(soup.body.contents) print(len(soup.body.contents)) # 打印孩子节点的个数 print(soup.body.contents[1]) # 打印第一个孩子节点 打印输出 # print(soup.head) <head><title>This is a python demo page</title></head> # print(soup.head.contents) [<title>This is a python demo page</title>] # print(soup.body.contents) ['\n', <p class="title"><b>The demo python introduces several python courses.</b></p>, '\n', <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>, '\n'] # print(len(soup.body.contents)) 5 # print(soup.body.contents[1]) <p class="title"><b>The demo python introduces several python courses.</b></p>
3.3) 循环遍历
# 遍历儿子节点
for child in soup.body.children:
print(child)
# 遍历子孙节点
for child in soup.body.descendants:
print(child)
4. 标签树的上行遍历
4.1) 上行遍历的属性
属性 说明 .parent 节点的父亲标签 .parents 节点先辈标签的迭代类型,用于循环遍历先辈节点
4.2)上行遍历代码
import requests from bs4 import BeautifulSoup url = "http://python123.io/ws/demo.html" r = requests.get(url) demo = r.text soup = BeautifulSoup(demo, "html.parser") print(soup.title.parent) print(soup.html.parent) # html 是HTML文本的最高级标签,所以其父亲是他自己 print(soup.parent) # soup是一种特殊的标签,soup的父亲为空 打印输出 # print(soup.title.parent) <head><title>This is a python demo page</title></head> # print(soup.html.parent) <html><head><title>This is a python demo page</title></head> <body> <p class="title"><b>The demo python introduces several python courses.</b></p> <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p> </body></html> # print(soup.parent) None
4.3) 循环遍历 遍历所有先辈节点,包括soup本身,所以要区别判断
for parent in soup.a.parents:
if parent is None:
print(parent)
else
print(parent.name)
5. 标签树的平行遍历
5.1) 平行遍历属性
属性 说明 .next_sibling 返回按照HTML文本顺序的下一个平行节点标签 .previous_sibling 返回按照HTML文本顺序的上一个平行节点标签 .next_siblings 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 .previous_sibli 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签
5.2) 平行遍历解释
平行遍历发生在同一个父节点下的各节点间
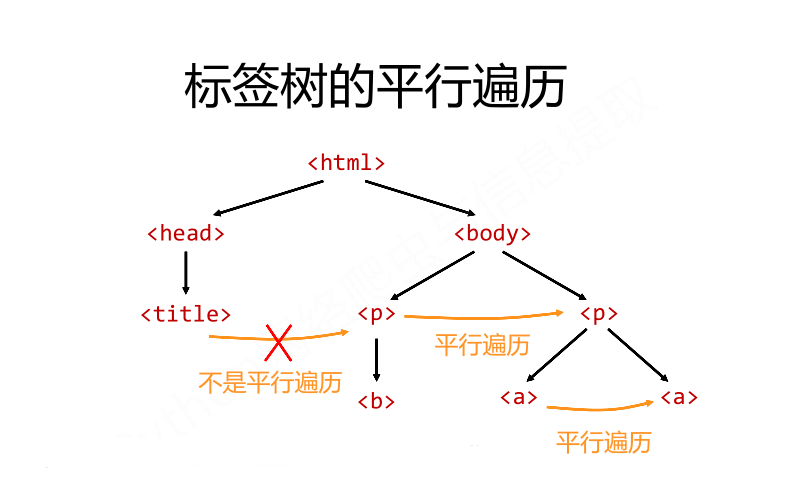
5.3) 平行遍历代码
import requests from bs4 import BeautifulSoup url = "http://python123.io/ws/demo.html" r = requests.get(url) demo = r.text soup = BeautifulSoup(demo, "html.parser") print(soup.a.next_sibling) print(soup.a.next_sibling.next_sibling) print(soup.a.previous_sibling) 打印输出 # print(soup.a.next_sibling) and # print(soup.a.next_sibling.next_sibling) <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a> # print(soup.a.previous_sibling) Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
5.4) 循环遍历
# 遍历后续节点
for sibling in soup.a.next_sibling:
print(sibling)
# 遍历前序节点
for sibling in soup.a.previous_sibling:
print(sibling)
6. 标签树的三种遍历总结
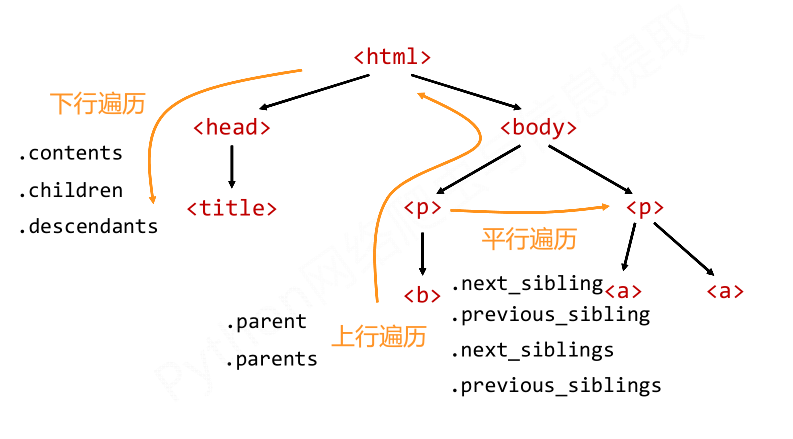
三、基于bs4库的HTML格式输出
1. bs4库的prettify()方法
.prettify()为HTML文本<>及其内容增加更加'\n'
.prettify()可用于标签,方法:<tag>.prettify()
让HTML内容更加“友好”的显示


1 import requests 2 from bs4 import BeautifulSoup 3 url = "http://python123.io/ws/demo.html" 4 r = requests.get(url) 5 demo = r.text 6 soup = BeautifulSoup(demo, "html.parser") 7 print(demo) 8 print(soup.prettify()) 9 print(soup.a.prettify()) 10 11 打印输出 12 #print(demo) 13 <html><head><title>This is a python demo page</title></head> 14 <body> 15 <p class="title"><b>The demo python introduces several python courses.</b></p> 16 <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: 17 <a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p> 18 </body></html> 19 20 #print(soup.prettify()) 21 <html> 22 <head> 23 <title> 24 This is a python demo page 25 </title> 26 </head> 27 <body> 28 <p class="title"> 29 <b> 30 The demo python introduces several python courses. 31 </b> 32 </p> 33 <p class="course"> 34 Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: 35 <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1"> 36 Basic Python 37 </a> 38 and 39 <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2"> 40 Advanced Python 41 </a> 42 . 43 </p> 44 </body> 45 </html> 46 47 #print(soup.a.prettify()) 48 <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1"> 49 Basic Python 50 </a>
2. bs4库的编码
bs4库将任何HTML输入都变成utf‐8编码,Python 3.x默认支持编码是utf‐8,解析无障碍。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>中文</p>","html.parser")
print(soup.p.string)
print(soup.p.prettify())
打印输出
# print(soup.p.string)
中文
# print(soup.p.prettify())
<p>
中文
</p>
RRR

 浙公网安备 33010602011771号
浙公网安备 33010602011771号