
软件工程复习捏
第一章 软件工程
软件危机
软件危机是指落后的软件生产方式无法满足迅速增长的计算机软件需求,从而导致软件开发与维护过程中出现一系列严重问题的现象。
原因:
1 软件规模越来越大,结构越来越复杂。
2 软件开发管理困难而复杂。
3 软件开发费用不断增加。
4 软件开发技术落后。
5 生产方式落后,仍采用手工方式。
6 开发工具落后,生产率提高缓慢。
软件工程
软件工程是指导计算机软件开发和维护的一门工程学科。(软件工程是一个工程学科,涵盖了软件生产的各个方面,从初始的构思到运行和维护。)
原理:
- 用分阶段的生命周期计划严格管理;
- 坚持进行阶段评审;
- 实行严格的产品控制;
- 采用现代程序设计技术;
- 结果应能清楚地审查;
- 开发小组的人员应该少而精;
- 承认不断改进软件工程实践的必要性;
三要素:方法、工具、过程
传统方法学采用结构化技术(结构化分析,结构化设计,结构化实现)来完成软件开发的各项任务
面向对象方法学是一种以数据为主线,把数据和对数据的操作紧密地结合起来的方法
阶段
问题定义:确定要解决的问题是什么(通过客户的访问调查,系统分析员写出问题的性质,工程目标和工程规模的书面报告,并得到客户的确认);
可行性研究:不是具体解决问题,而是研究问题的范围,探索问题是否值得去解,是否有可行的解决方法;
需求分析:准确确定“为了解决这个问题,目标系统必须做什么”,主要是确定目标系统必须具备哪些功能;
总体设计:设计出目标系统的多种方案;设计程序的体系结构;
详细设计:详细的设计每个模块,确定要实现模块功能所需要的算法和数据结构;
编码和单元测试:写出正确的容易理解,容易维护的程序模块;
综合测试:通过各种类型的测试(及相应的的调试)使软件达到预定的要求;
软件维护:通过各种必要的维护活动使系统持久地满足用户的需要;
模型
瀑布模型
瀑布模型的优点:
可强迫开发人员采用规范的方法;
严格规定了每个阶段必须提交的文档;
要求每个阶段交出的所有产品都必须经过质量保证小组的仔细验证。
瀑布模型缺点:
瀑布模型是由文档驱动;
可能最终产品不能真正满足客户的需求。
增量模型
增量模型优点:
人员分配灵活,刚开始不用投入大量人力资源;
可先发布部分功能给客户,对客户起到镇静剂的作用;
增量能够有计划地管理技术风险。
增量模型缺点:
需要软件具备开放式的体系结构;
容易退化为边做边改模型,从而使软件过程的控制失去整体性;
增加系统内部的耦合复杂性。
螺旋模型
螺旋模型的优点:
对可选方案和约束条件的强调有利于已有软件的重用,也有助于把软件质量作为软件开发的一个总要目标;
减少了过多测试(浪费资金)或测试不足(产品故障多)所带来的风险;
在螺旋模型中维护只是模型的另一个周期,在维护和开发之间并没有本质区别。
螺旋模型的缺点:
它是风险驱动的。
第二章 可行性研究
可行性研究的目的不是为了解决问题,而是确定问题是否值得去解决。
可行性:
- 技术可行性
- 经济可行性
- 操作可行性
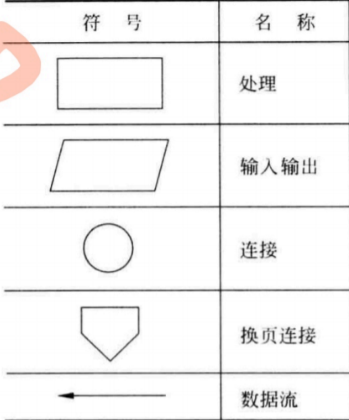
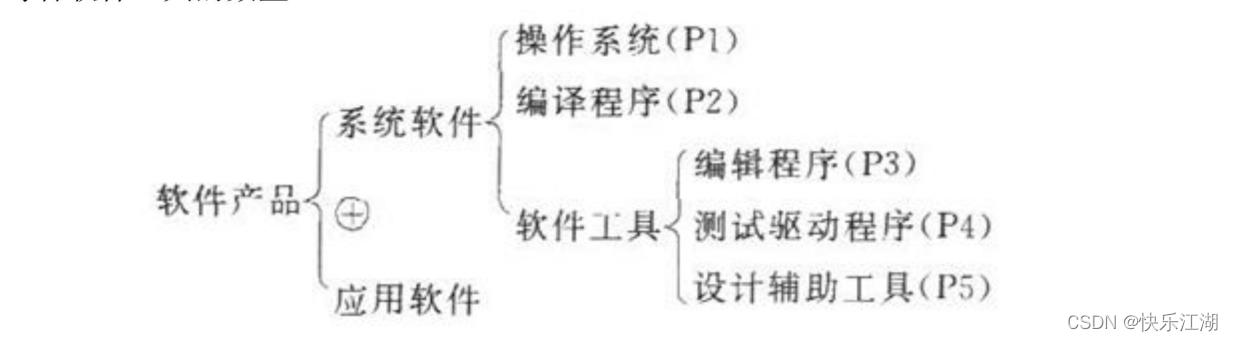
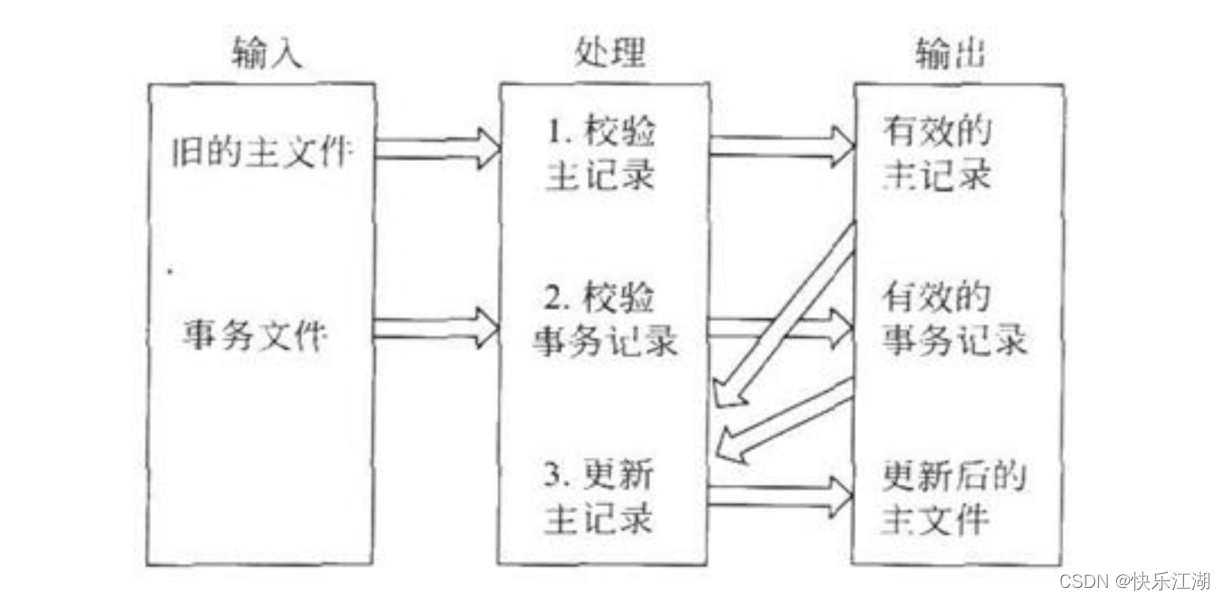
系统流程图
系统流程图是概括的描绘系统物理模型的传统工具。
数据流图
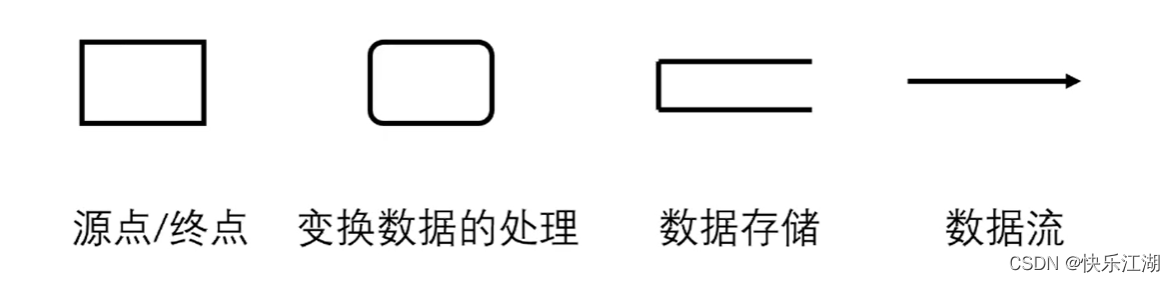
数据流图(Data Flow Diagram,DFD)是一种图形化技术,它描绘信息流和数据从输入移动到输出的过程中所经受的变换。
数据字典

第三章 需求分析
任务
确定对系统的综合要求
分析系统的数据要求
导出系统的逻辑模型
修正系统开发计划
模型
需求分析过程应该建立的三种模型:数据模型、功能模型和行为模型。
实体-联系图:描绘数据对象、数据对象的属性及数据对象之间的关系,用于建立数据模型。
数据流图:描绘当数据在软件系统中流动和被处理的逻辑过程,是建立功能模型的基础。
自顶向下逐步求精
通过可行性研究已经得出了目标系统的高层数据流图,需求分析的目标之一就是把数据流和数据定义到元素级,为了达到这个目标,通常从数据流图的输出端看手分析,这是因为系统的基本功能是是产生这些输出,输出数据决定了系统必须具有的最基本的组成元素。
E-R图

状态转换图
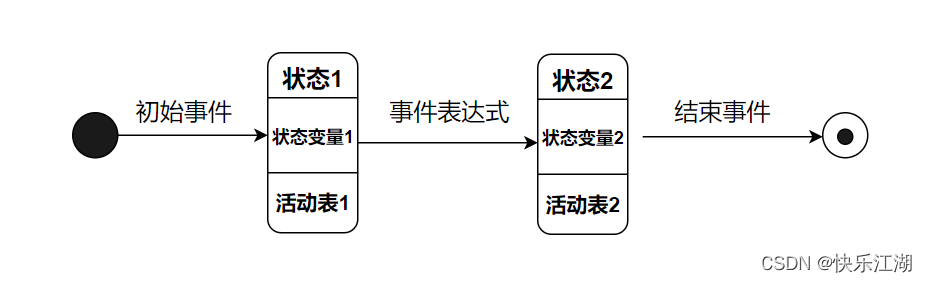
状态转换图:描绘了系统的状态及引起状态转换的事件,是建立行为模型的基础。
层次方框图、Warnier图、IPO图
第四章 形式化说明技术
优点:
能够简洁准确的描述物理现象、对象或动作的结果。
可以在不同软件工程活动之间平滑的过度。
它提供了高层确认的手段。
在开发大型软件系统的过程中应该使用形式化说明技术。
第五章 总体设计
总体设计过程通常由两个主要阶段组成:
系统设计阶段:确定系统的具体实现方案
结构设计阶段:确定软件结构
典型的总体设计过程包括下述9个步骤:
设想供选择的方案
选取合理的方案
推荐最佳方案
功能分解
设计软件结构
设计数据库
制定测试计划
书写文档
审查和复审
设计原理
模块化
模块化就是把程序划分成独立命名且可独立访问的模块,每个模块完成一个子功能,这些模块集成起来构成一个整体,可以完成指定的功能满足用户的需求。
抽象
把相似的方面集中和概括起来,暂时忽略它们之间的差异,这就是抽象。
抽象就是抽出事物的本质特性而暂时不考虑它们的细节。
逐步求精
逐步求精:为了能集中精力解决最主要问题而尽量推迟对问题细节的考虑。
信息隐藏和局部化
信息隐藏:应该这样设计和确定模块,使得一个模块内包含的信息(过程和数据)对于不需要这些信息的模块来说是不能访问的。
局部化:是指把一些关系密切的软件元素物理地放得彼此靠近。
模块独立
模块独立的概念是模块化、抽象、信息隐藏和局部化概念的直接结果。
模块的独立程度可以由两个定性标准度量:内聚、耦合
耦合:
耦合是对一个软件结构内不同模块之间互连程度的度量。
耦合强弱取决于模块间接口的复杂程度,进入或访问一个模块的点,以及通过接口的数据。
设计原则:尽量使用数据耦合,少用控制耦合和特征耦合,限制公共环境的耦合的范围,完全不用内容耦合。
数据耦合:如果两个模块彼此间通过参数交换信息,而且交换的信息仅仅是数据。数据耦合是低耦合。
控制耦合:传递的信息中有控制信息。控制耦合是中等程度的耦合,增加了系统的复杂程度。
特征耦合:当整个数据结构作为参数传递而被调用的模块只需要使用其中一部分数据元素时。
公共环境耦合:当两个或多个模块通过一个公共数据环境互相作用时。公共环境可以是全程变量、共享通信区、内存的公共覆盖区、任何存储介质的文件、物理设备等。
内容耦合:最高程度的耦合,模块之间用来用去
内聚:
内聚标志着一个模块内各个元素彼此之间结合的紧密程度,它是信息隐藏和局部化概念的扩展。
理想内聚的模块只做一件事情。
模块内的高内聚往往意味着模块间的低耦合。
设计原则:力求高内聚,从而获得较高的模块独立性。
低内聚有如下几类:
偶然内聚:一个模块完成一组任务,这些任务彼此之间有关系,关系也是很松散的
逻辑内聚:一个模块完成的任务在逻辑上属于相同或相似的一类。如一个模块产生各种类型的全部输出。
时间内聚:如果一个模块包含的任务必须在同一时间内执行。如模块完成各种初始化工作。
中内聚:
过程内聚:如果一个模块内的处理元素是相关的,且必须以特定次序执行。
通信内聚:如果一个模块中所有元素都使用同一个输入数据和(或)产生同一个输出数据。
高内聚:
顺序内聚:如果一个模块内的处理元素和同一个功能密切相关,且这些处理必须顺序执行(通常一个处理元素的输出数据作为下一个处理元素的输入数据),则称为顺序内聚。根据数据流图划分模块得到往往是顺序内聚模块。
功能内聚:如果模块内的所有处理元素属于一个整体,完成一个单一的功能,则称为功能内聚。功能内聚是最高程度的内聚。
7种内聚的优劣评分:
名称 评分
功能内聚 10
顺序内聚 9
通信内聚 7
过程内聚 5
时间内聚 3
逻辑内聚 1
偶然内聚 0
启发规则
改进软件结构提高模块独立性
模块规模应该适中
深度、宽度、扇出和扇入都应适当
模块的作用域应该在控制域内
力争降低模块接口的复杂程度
设计单入口单出口的模块
模块的功能应该可以预测
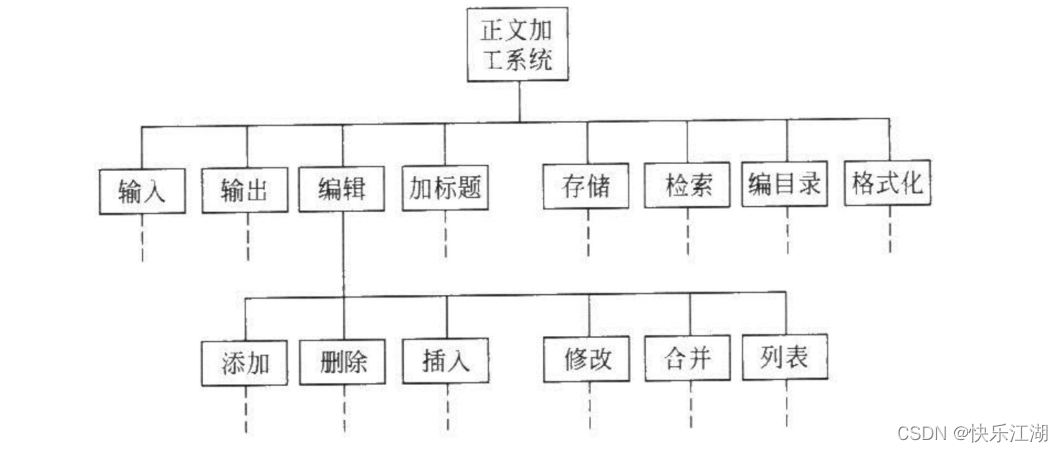
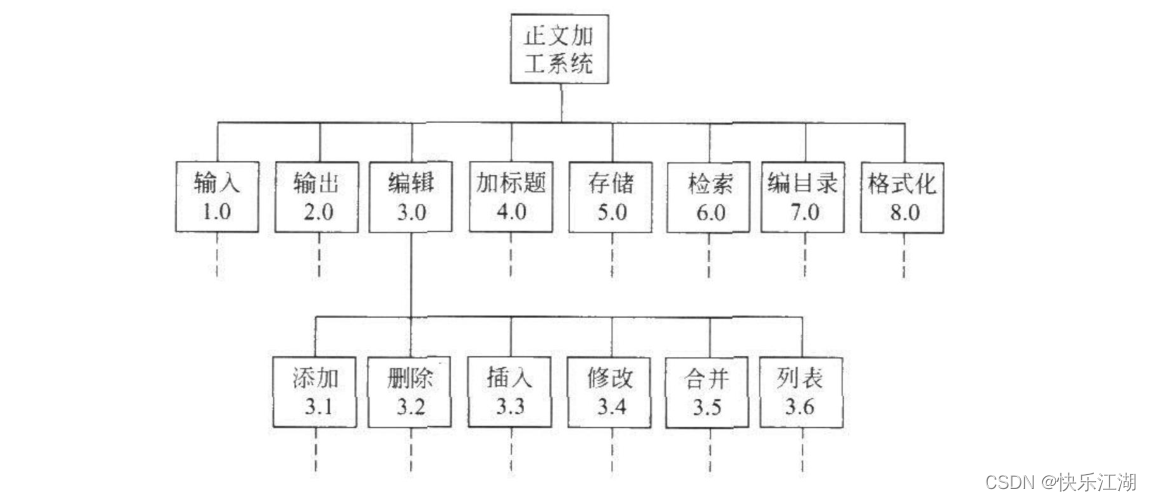
层次图,HIPO就是加个编号
面向数据流的设计方法
面向数据流的设计方法把信息流映射成软件结构,信息流的类型决定了映射的方法。
第六章 详细设计
任务
详细设计的主要任务是设计每个模块的实现算法、所需的局部数据结构
思想
结构化程序设计采用自顶向下、逐步求精的设计方法,各个模块通过“顺序、选择、循环”的控制结构进行连接,并且只有一个入口、一个出口。
程序流程图

盒图
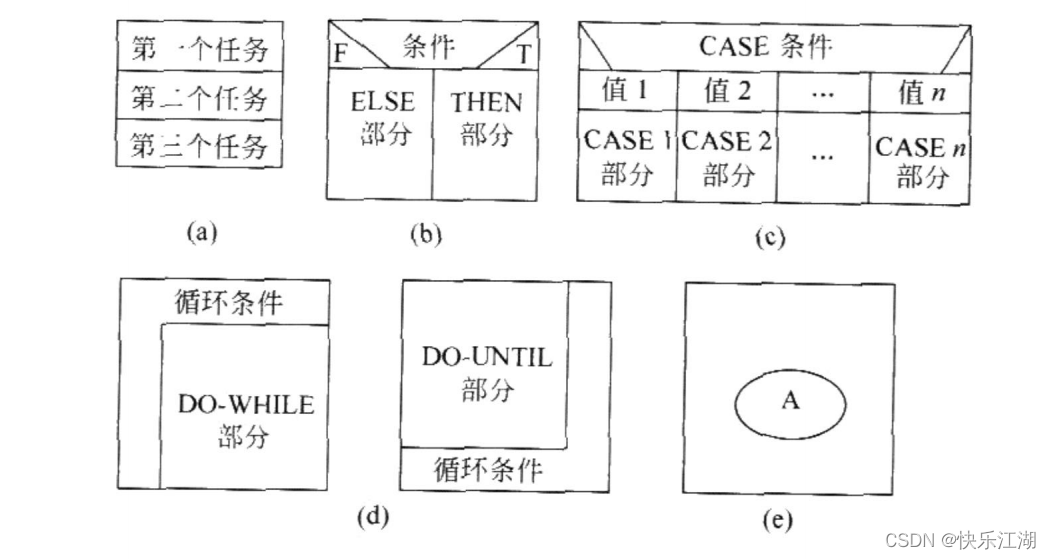
PAD图
顺序、判断、循环、语句
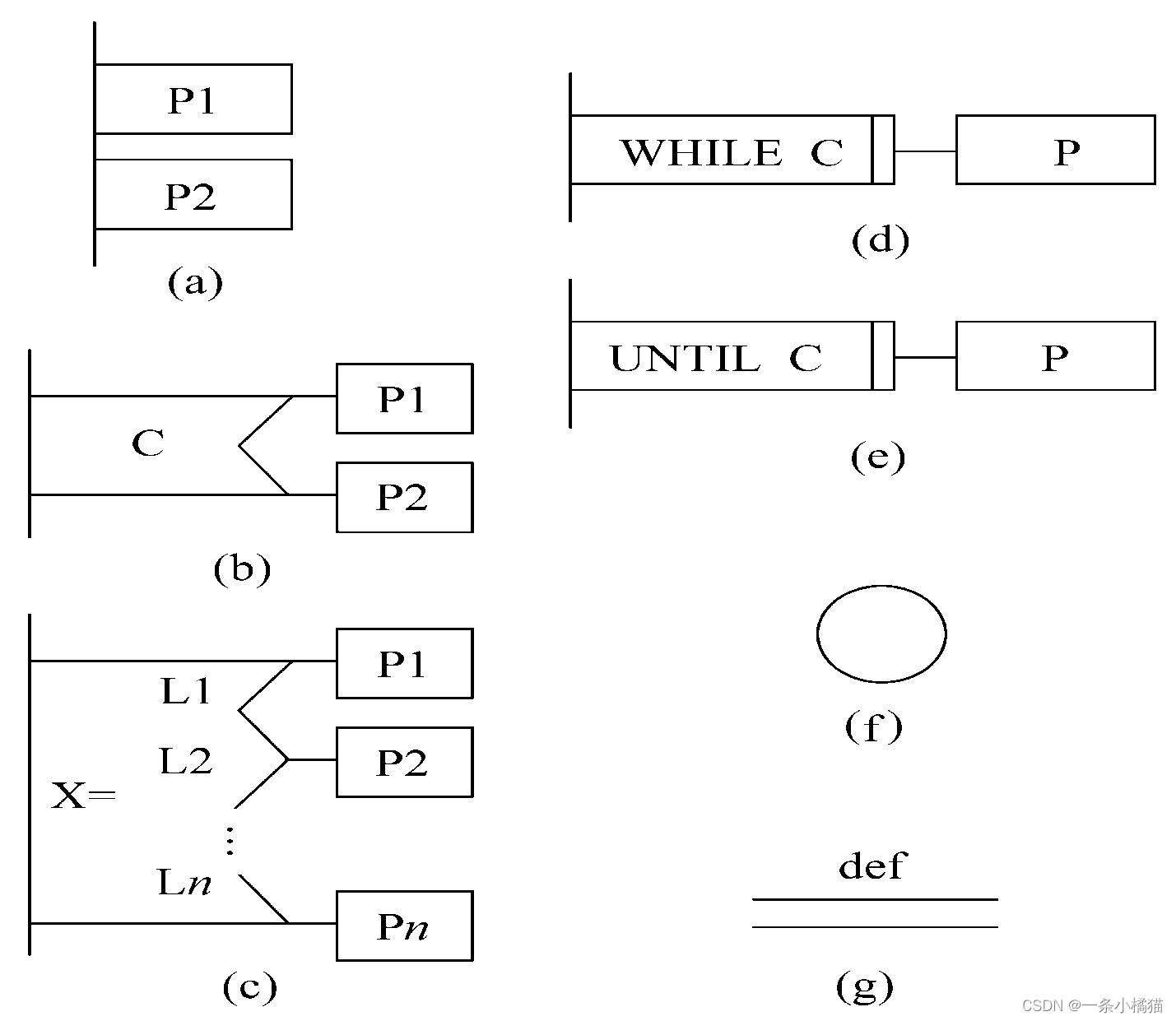
盒图转换
Jackson图
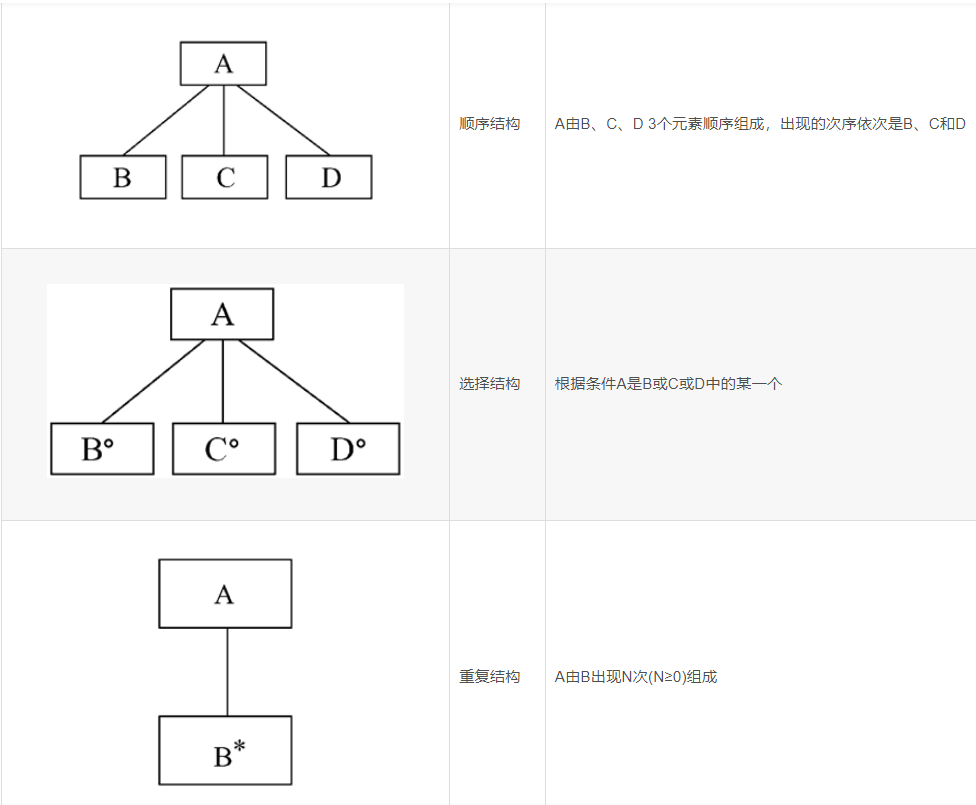
计算环形复杂度的方法
可以用下述3种方法中的任何一种来计算环形复杂度。
流图中线性无关区域数等于环形复杂度
流图G的环形复杂度 V(G)=E-N+2,其中E是流图中边的条数,N是结点数
流图G的环形复杂度 V(G)=P+1,其中P是流图中判定结点的数目
第七章 实现
语言选择
(1)公司结束积累和程序员的知识:相关项目、技术、管理经验、程序员的个人技术特长
(2)软件可移植性和兼容性:目标平台、平台兼容
(3)软件的应用领域:科学计算:Fortran,C,Matlab 移动应用:Java,Swift,C# 网站应用:JSP,PHP,Ruby,ASP.NET 窗体应用:C#,vc++,VB,Delphi,Java
编程风格
(1)程序内部的文档,包括恰当的标识符、适当的注释和程序的视觉组织
(2)数据说明,标准化
(3)语句构造,原则:简单、直接
(4)输入输出
(5)效率,处理时间,存储器容量,输入输出的效率
软件测试的目标
(1)测试是为了发现程序中的错误而执行程序的过程
(2)好的测试方案是极可能发现迄今为止尚未发现的错误的测试方案
(3)成功的测试是发现了至今为止尚未发现的错误的测试
软件测试准则
(1)所有的测试都应该能追溯到用户需求
(2)应该远在测试开始之前就制定测试计划
(3)把Pareto原理应用到软件测试中,很大一部分错误集中在少数一块,一个地方有错,前面后面也有错,错误比较集中
(4)应该从“小规模”测试开始,并逐步进行“大规模”测试
(5)穷举测试是不可能的
(6)应该由独立的第三方从事测试工作
测试方法
(1)黑盒测试:把程序看作一个黑盒子,完全不考虑程序的内部结构和处理过程
(2)白盒测试:测试者完全知道程序的结构和处理算法
测试步骤
(1)模块测试,编程同时做的,又称为单元测试
(2)子系统测试,把经过单元测试的模块放在一起形成一个子系统来测试,着重测试模块的接口
(3)系统测试,集成测试,模拟用户环境
(4)验收测试,要有用户测试,不能让用户发现错误,相当于交东西
(5)平行运行,同时运行新开发出来的系统和被它取代的旧系统,以便比较新旧系统的处理结果
单元测试
单元测试集中检测软件设计的最小单元-模块,主要使用白盒测试技术
测试重点
(1)模块接口 数据输入/输出的正确性
(2)局部数据结构
(3)重要执行通路
(4)出错处理通路 try catch
(5)边界条件 i=n
集成测试
主要是自顶向下集成测试策略和自底向上集成测试策略两种。
自顶向下集成测试策略的优点是:能尽早地对程序的主要控制和决策机制进行检验,因此能较早地发现错误。
缺点是:在测试较高层模块时,低层处理采用桩模块替代,不能反映真实情况,重要数据不能及时回送到上层模块,因此测试并不充分。
自底向上集成测试策略的优点是:不用桩模块,测试用例的设计亦相对简单,但缺点是程序最后一个模块加入时才具有整体形象。
Alpha测试
由用户在开发者的场所进行测试,并且在开发者对用户的“指导”下进行测试。
白盒测试技术
(1)逻辑覆盖
语句覆盖,选择足够多的测试技术,使被测试程序中每个语句至少执行一次
判定覆盖,测试重点,程序中的if语句
条件覆盖,不仅每个语句至少执行一次,而且使判定表达式中的每个条件都取到各种可能的结果
判定/条件覆盖,选取足够多的测试数据,使得判定表达式的每个条件都取到各种可能的值,而且判定表达式也都取到了各种可能的结果
条件组合覆盖,更强的逻辑覆盖标准,它要求选取足够多的测试数据,使得每个判定表达式中的各种可能组合出现一次
路径覆盖,选取足够多测试数据,使程序的每条可能路径都至少执行一次
黑盒测试技术
(1)等价划分是一种黑盒测试技术,这种技术把程序的输入域划分成若干个数据类,据此导出测试用例,一个理想的测试用例能独自发现一类错误
有效等价类 无效等价类(从不同角度违反规则)
(2)边界值分析
(3)错误推测
软件可靠性
程序在给定时间间隔内,按照规格说明书的规定运行的概率
第八章 维护
软件维护的定义:就是在软件已经交付使用之后,为了改正错误或满足新的需要而修改软件的过程。
第一项维护活动:把诊断和改正错误的过程称为改正性维护。
第二项维护活动:适应性维护:为了和变化了的环境适当地配合而进行的修改软件的活动,是既必要又经常的维护活动。
第三项维护活动:完善性维护:在使用软件的过程中用户往往提出增加新功能或修改已有功能的建议,还可能提出一般性的改进意见。通常占软件维护工作的大部分。
第四项维护活动:预防性维护:当为了改进未来的可维护性或可靠性,为了给未来的改进奠定更好的基础而修改软件时。
第九章 面向对象方法学
优点
与人类习惯的思维方法一致
稳定性好
可重用性好
较易开发大型软件产品
可维护性好
概念
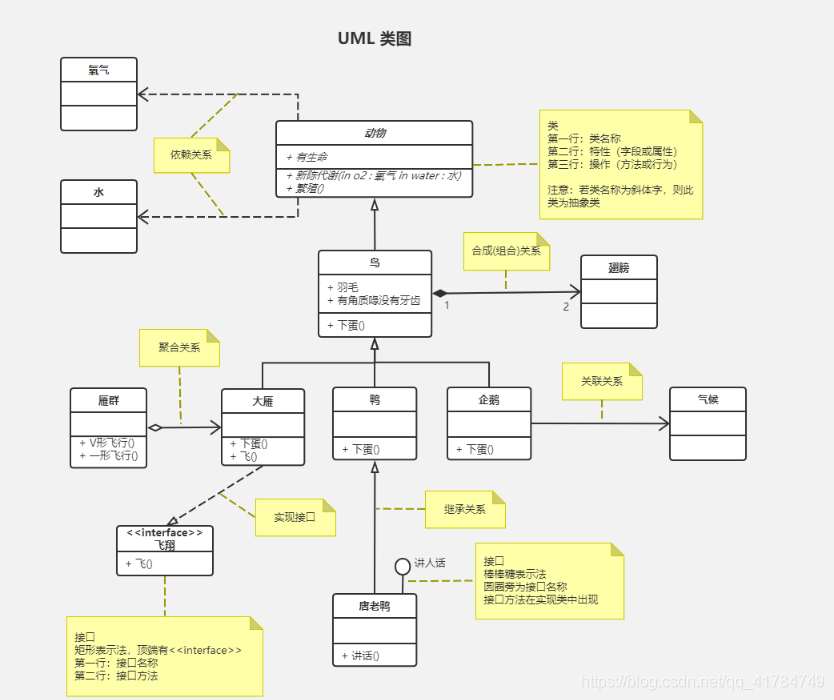
类:是一组具有相同属性和相同操作的对象的集合。类是对具有相同属性和行为的一个或多个对象的描述。
实例:实例就是由某个特定的类所描述的一个具体的对象。
消息:消息就是要求某个对象执行在定义它的那个类中所定义的某个操作的规格说明。组成部分:接收消息的对象;消息选择符(也称为消息名);零个或多个变元
方法:方法就是对象所能执行的操作,也就是类中所定义的服务。
属性:属性就是类中所定义的数据,它是对客观世界实体所具有的性质的抽象。类的每个实例都有自己特有的属性值。
封装:对象封装了对象的数据以及对这些数据的操作。所谓封装就是把某个事物包起来,使外界不知道该事物的具体内容。
继承:继承是子类自动地共享基类中定义的数据和方法的机制。
单重继承:子类仅从一个父类继承属性和方法。
多重继承:子类可从多个父类继承属性和方法。
多态性:多态性是指子类对象可以像父类对象那样使用。
重载(有两种重载):函数重载:指在同一作用域内的若干个参数特征不同的函数可以使用相同的函数名字。
重载:运算符重载:指在同一个运算符可以施加于不同类型的操作数上面。
三种模型
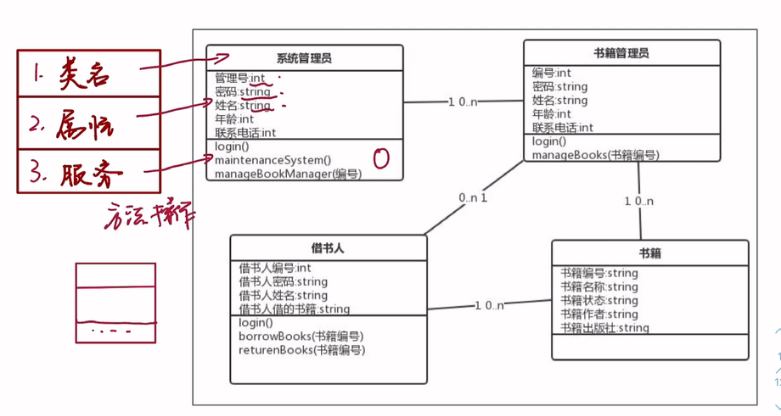
对象模型是类图。
对象模型表示静态的、结构化的系统的“数据”性质。它是对模拟客观世界实体的对象以及对象彼此间的关系的映射,描述了系统的静态结构。
动态模型是顺序图。
动态模型表示瞬时的、行为化的系统的“控制”性质,它规定了对象模型中的对象的合法变化序列。
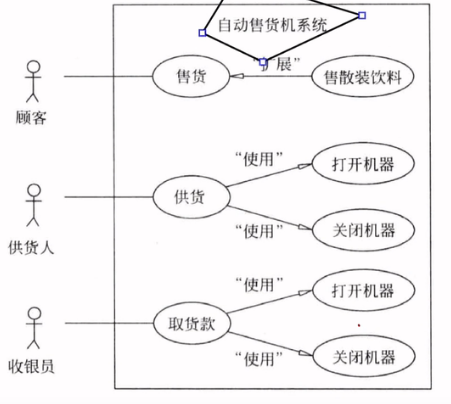
功能模型是用例图。
功能模型表示变化的系统的“功能”性质,它指明了系统应该“做什么”,因此更直接地反映了用户对目标系统的需求。
UML
UML (Unified Modeling Language)为面向对象软件设计提供统一的、标准的、可视化的建模语言。
用例图

类图

状态图
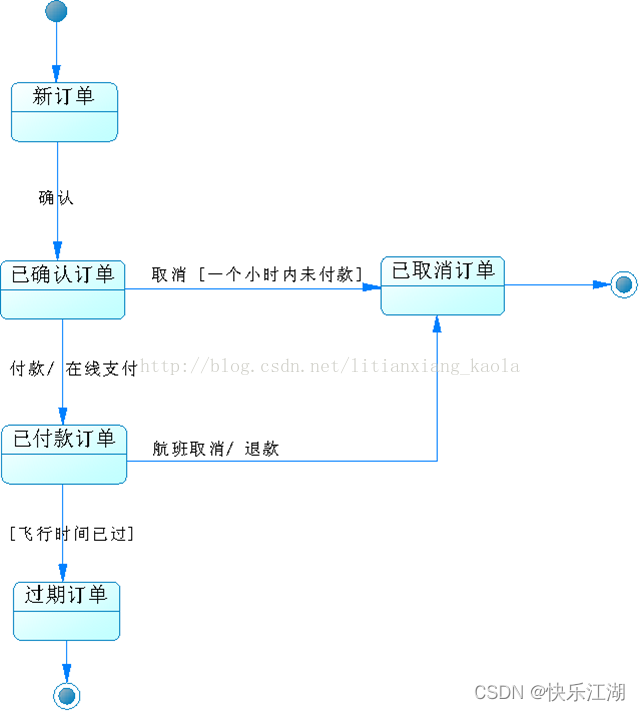
顺序图
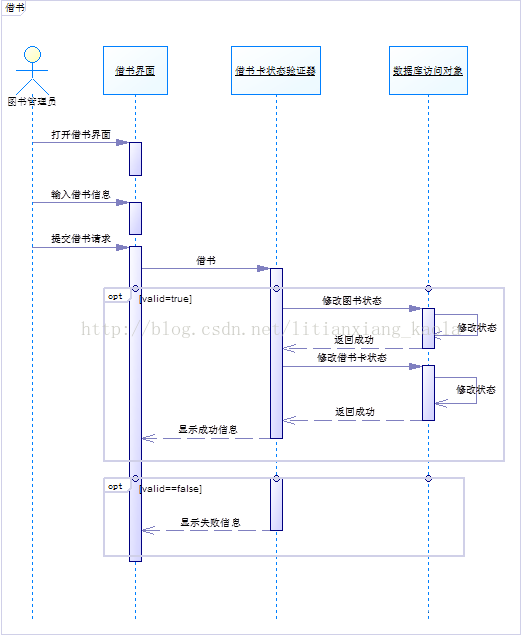
第十章 面向对象分析
任务
面向对象分析与设计主要是得到系统的模型,但面向对象分析的主要任务是描述系统应该解决什么问题,即分析模型,它还不涉及到系统的组织结构等细节信息。
流程
面向对象建模得到的模型包含系统的 3 个要素:
静态结构(对象模型)
交互次序(动态模型)
数据变换(功能模型)
复杂问题(大型系统)的对象模型通常由下述五个层次组成:
主题层
类与对象层
结构层
属性层
服务层
第十一章 面向对象设计
面向对象设计准则
1、模块化;把程序整体划分成一个个独立命名且可独立访问的完成单个子功能的模块。采用模块化,软件结构清晰,不仅容易设计也容易阅读和理解,有利于软件开发工程的组织管理
2、抽象:抽出事物的本质特性,暂不考虑其细节,使设计从具体实现方法中超脱。包括程序抽象、数据抽象、参数抽象。
3、信息隐藏:对象封装。有利于测试期间和以后的软件维护期间进行软件的修改。
4、弱耦合:包括交互耦合、继承耦合。
5、强内聚:包括服务内聚、类内聚、一般-特殊内聚。
6、可重用:是提高软件开发生产率和目标系统质量的重要途径。
重用
重用也叫再用或复用,是指同一事物不作修改或稍加改动就多次重复使用。
• 实例重用
(1) 使用适当的构造函数,按照需要创建类的实例
(2) 用几个简单的对象作为类的成员创建出一个更复杂的类
• 继承重用
继承性提供了一种对已有的类构件进行裁剪的机制
• 多态重用
(1) 使对象的对外接口更加一般化,降低了消息连接的复杂程度
(2) 提供一种简便可靠的软构件组合机制
系统分解
软件工程师在设计比较复杂的应用系统时普遍采用的策略,也是首先把系统分解成若干个比较小的部分,然后再分别设计每个部分。
层次
块状
设计问题域子系统
- 调整需求
- 重用已有的类
- 把问题域类组合在一起
- 添加一般化类以建立协议
- 调整继承类层次
设计人机交互子系统
- 用户分类
- 描述用户
- 设计命令层次
- 设计人机交互类
设计任务管理子系统
- 确定事件驱动型任务
- 确定时钟驱动型任务
- 确定优先任务
- 确定关键任务
- 确定协调任务
- 尽量减少任务数
- 确定资源需求
数据管理子系统
设计数据管理子系统
文件管理系统:不同系统有明显差异
关系数据库管理系统:
(1) 运行开销大
(2) 不能满足高级应用的需求
(3) 与程序设计语言的连接不自然
第十三章 软件项目管理
软件项目规模估算的方法
Loc估算法
FP估算法
PERT估算法


 浙公网安备 33010602011771号
浙公网安备 33010602011771号