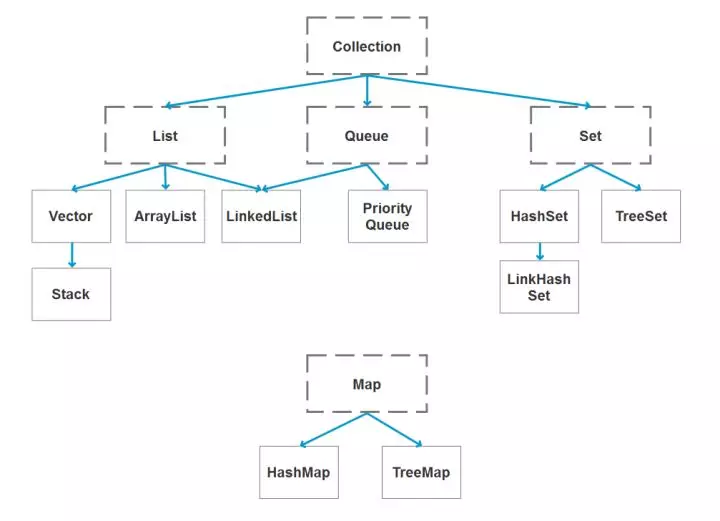
集合比较
TreeMap的两种排序方法
TreeSet可以实现对元素按照某种规则进行排序
一 自然排序
1.Student类中实现 Comparable<T>接口
2.重写Comparable接口中的Compareto方法
@Override public int compareTo(Student s) { //return -1; //-1表示放在红黑树的左边,即逆序输出 //return 1; //1表示放在红黑树的右边,即顺序输出 //return o; //表示元素相同,仅存放第一个元素 //主要条件 姓名的长度,如果姓名长度小的就放在左子树,否则放在右子树 int num=this.name.length()-s.name.length(); //姓名的长度相同,不代表内容相同,如果按字典顺序此 String 对象位于参数字符串之前,则比较结果为一个负整数。 //如果按字典顺序此 String 对象位于参数字符串之后,则比较结果为一个正整数。 //如果这两个字符串相等,则结果为 0 int num1=num==0?this.name.compareTo(s.name):num; //姓名的长度和内容相同,不代表年龄相同,所以还要判断年龄 int num2=num1==0?this.age-s.age:num1; return num2; }
二 比较器排序
1.单独创建一个比较类,这里以MyComparator为例,并且要让其继承Comparator<T>接口
2.重写Comparator接口中的Compare方法
TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>() { @Override public int compare(Student s1, Student s2) { int num = s1.getName().length() - s2.getName().length(); int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num; int num3 = num2 == 0 ? s1.getAge() - s2.getAge() : num2; return num3; } });
A:自然排序:要在自定义类中实现Comparerable<T>接口 ,并且重写compareTo方法
B:比较器排序:在自定义类中实现Comparetor<t>接口,重写compare方法
TreeMap和HashMap的区别
1、 HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)。
2、在Map 中插入、删除和定位元素,HashMap是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。使用HashMap要求添加的键类明确定义了hashCode()和 equals()的实现。
两个map中的元素一样,但顺序不一样,导致hashCode()不一样。
同样做测试:
在HashMap中,同样的值的map,顺序不同,equals时,false;
而在treeMap中,同样的值的map,顺序不同,equals时,true,说明,treeMap在equals()时是整理了顺序了的。????
HashTable与HashMap
1、同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的。
2、HashMap允许存在一个为null的key,多个为null的value 。
3、hashtable的key和value都不允许为null。
Arraylist和Linkedlist
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinkedList比较占优势,因为ArrayList要移动数据。 这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
Vector和ArrayList
1,vector是线程同步的,所以它也是线程安全的,而arraylist是线程异步的,是不安全的。如果不考虑到线程的安全因素,一般用arraylist效率比较高。
2,如果集合中的元素的数目大于目前集合数组的长度时,vector增长率为目前数组长度的100%,而arraylist增长率为目前数组长度的50%。如果在集合中使用数据量比较大的数据,用vector有一定的优势。
3,如果查找一个指定位置的数据,vector和arraylist使用的时间是相同的,如果频繁的访问数据,这个时候使用vector和arraylist都可以。而如果移动一个指定位置会导致后面的元素都发生移动,这个时候就应该考虑到使用linklist,因为它移动一个指定位置的数据时其它元素不移动。
ArrayList 和Vector是采用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,都允许直接序号索引元素,但是插入数据要涉及到数组元素移动等内存操作,所以索引数据快,插入数据慢,Vector由于使用了synchronized方法(线程安全)所以性能上比ArrayList要差,LinkedList使用双向链表实现存储,按序号索引数据需要进行向前或向后遍历,但是插入数据时只需要记录本项的前后项即可,所以插入数度较快。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号