Redis入门指南(一)
基本命令:
redis 不区分大小写
keys pattern ; 获得符合规则的键名列表 支持glob风格通配符,?:一个字符 ; * : 任意个字符; [b-d ] 匹配b到d; \? 匹配“?”
exists key > 0/1 ; 判断一个键是否存在。
del key > 0/1 ; del 不支持通配符,结合Linux管道和xargs命令进行自定义删除。
type key ; 获取键的类型
字符串类型:
储存任何形式的字符串包括二进制数据。一个键最大允许储存512MB。字符串是其他4种数据类型的基础,其他数据类型可以说是组织字符串的形式不同。
set key value;
get key;
incrBy key [ increment ], decrBy key [ increment ],incrByFloat ; incr 是原子操作当且仅当value为整数时,返回递增直之后的值。无key默认为0,返回1。
应用:文章访问量的统计,生成自增ID(做到每天的ID都重新开始),储存文章数据(脚本可以序列化存储的数据拿来使用)
另外:append key value > length; strlen key > lengthb;
Mget key [key ...] ; Mset key value [ key value ...]
PS:位操作
getBit key offset(位置), 一个字节8位(二进制位),将字节转化之后进行操作。
setBit key offset value, bitCount key [start] [end] , bitOp operation destkey key [key ...](对多个字符进行运算,保存结果在 destkey 中。 operation 可以是AND OR XOR NOT)
利用位操作可以紧凑地保存布尔值,比如100万用户的性别,只需要100KB左右的空间。而且getBit 和 setBit 的时间复杂度都是O(1)
散列类型:(HASH)
散列对象的键值也是一种字典结构,其储存了字段(field)和字段值的映射,字段值只能是字符串,也就是不能嵌套其他数据类型。一个散列行键可以包含最多2^32-1
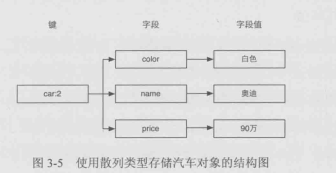
结构优于关系型数据库,可以减少冗余字段。
hget key field; hset key value field ; hMget key field [field...]; hMset key field value[ field value...]; hgetAll ( hset 执行插入返回1,更新操作返回0)
hexists key field; hsetNx key field value (原子操作); hIncrBy key field increment;hdel key field[feild...]
应用:保存各种属性
PS: hKeys key ;hVels key ;(只获取字段名或字段值) hLen key
列表类型:
Redis类型内部使用的双向链表实现的,所以向列表两端添加元素的时间复杂度为O(1).即使是几千万个元素的列表,获取头部或尾部的10条记录也是极为快速。
代价是,通过索引访问元素比较慢。
应用:社交往网站的新鲜事(看最新内容)。可以用来记录日志,新加的日志不会瘦日志数量的影响。还可以存放评论,最新评论可以放到最前。
命令:
lpush key value [value ...], rpush key value [value ...]
lpop key , rpop key
llen key 获取列表中元素的个数。
lRange key start stop 获取数个元素,也可以使用负索引。如果超出,则全部返回。
lrem key count value 删除前count个值为value的元素,count 为+从左开始,-从右开始,=0删除全部的值为value的元素。
PS:
lIndex key index , lset key index value , lInsert key before/after pivot value 值为pivot 的元素
ltrim key start end 截取 ,rpoplpush source destination 将元素从一个表转到另一个表
集合类型:
一个集合类型,可以储存至多 2^32-1个字符串。一般是进行加入和删除操作。类型内部使用的是值为空的散列表(hash table 注意,是散列表,不是散列类型)来实现的。所以这些操作的时间复杂度是O(1)
命令:
sadd key member [member...],srem key member [member...]
smembers key ,获取集合所有的元素;sismember key member 判断元素是否在集合中
集合的运算:
sdiff ke[ key ...] 差集, sinter 交集 , sunion 并集
实践:存储文章的标签(一篇文章可以有多个标签,文章和标签之间没有固定的关系)
PS:
scard key 获取集合中的元素个数。 sdiffStore destination key [key ..] 进行集合运算并储存 和 sdiff 一样,但是会存储在destination中
sinterStore , sunionStore
sRandMember key [count] 随机获取多个元素。+ 做过去重的,-没做去重
有序集合类型:
和列表类型有相同也有很大的不同。
使用散列表和跳跃表(skip list)实现的。时间复杂度O(logN).
列表不能简单调整元素的位置,有序集合可以(通过更改这个元素的分数)
有序集合类比列表更耗内存。
命令: zadd key score member [ score member ...]
zscore key member 获得分数
zRange key start stop [withSores],zRevRange . 按照分数大小顺序排列出来,同时需要获取分数则加 withScores
zRangeByScore key min max [withScores] . 按照分数的范围给出排列
zIncre key increment member
实践:
文章实现按点击量排行。可以将分数设置为时间,就可以按时间排行。
PS:
zcard key , 获取元素的个数;zcount key min max 获取指定分数范围内的元素个数。
zrem key member [member...], 删除一个或者多个
zRemRangeByRank key start stop 按照排名范围删除元素。
zRemRangeByScore key min max 按照分数范围删除元素
zrank key member , zrevRank key member 获得元素的排名
zinterStore destination numkeys key [key ...] 计算有序集合的交集

 浙公网安备 33010602011771号
浙公网安备 33010602011771号