

梯度下降法 part 2 ver 0.9 beta
梯度下降法
介绍
梯度下降是迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以)。在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法。在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。反过来,如果我们需要求解损失函数的最大值,这时就需要用梯度上升法来迭代了。在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。
梯度:对于可微的数量场f(x,y,z),以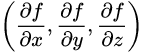 为分量的向量场称为f的梯度或斜量。
为分量的向量场称为f的梯度或斜量。
梯度下降法(gradient descent)是一个最优化算法,常用于机器学习和人工智能当中用来递归性地逼近最小偏差模型
相关知识学习
机器“学习”的工作原理,类似一道微积分习题
介绍梯度下降的思想,不仅是神经网络学习的基础,机器学习中很多其他技术也是基于这个方法。
从概念上讲,认为每个神经元与上一层的所有神经元相连接,决定其激活值的加权值和中的权重,有点像是那些连接的强弱,而偏置则表明神经元是否更容易被激活,在一开始,我们会完全随机地初始化所有的权重和偏置值。
代价函数的需要
用更加数学的语言来说,将每个垃圾输出激活值,与你想要的值之间的差的平方加起来,称之为训练单个样本的“代价”,(注意下,网络能对图像进行正确的分类时,这个平分和就比较小,如果网络找不着点,这个平分和就很大),代价函数取决于网络对于上万个训练数据的综合表现

代价平均值也叫Empirical Risk"经验风险“
只告诉电脑它有多糟糕不是很有用的,还需要告诉它,怎么改变这些权重和偏置值。
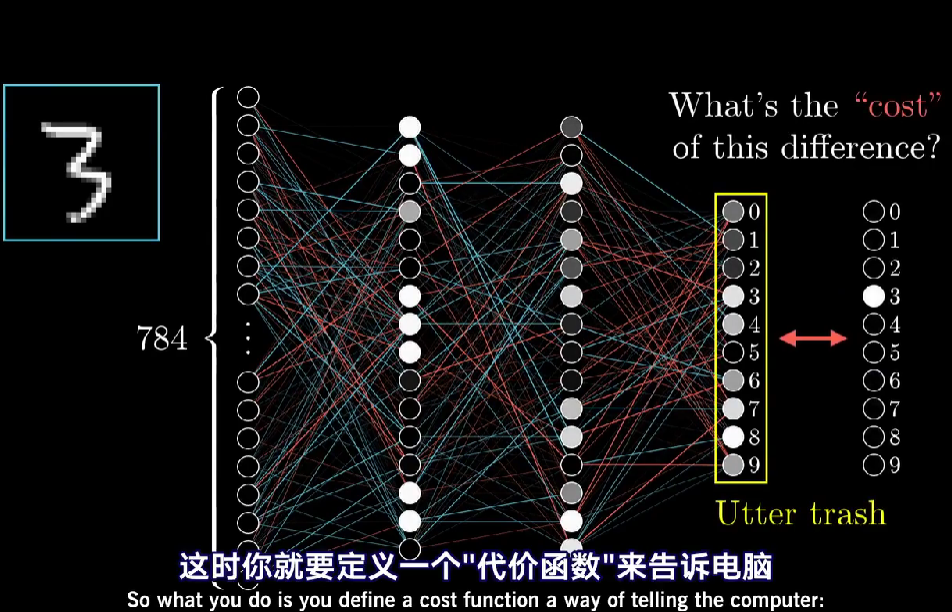
为了简化问题 先不想一个有13000个变量的函数,而先考虑简单的一元函数,只有一个输入变量,只输出一个数字
要怎么找输入值x,使得函数值最小化呢,可以通过微积分,直接算出这个最小值
但函数很复杂的话,就不一定能写出来。如

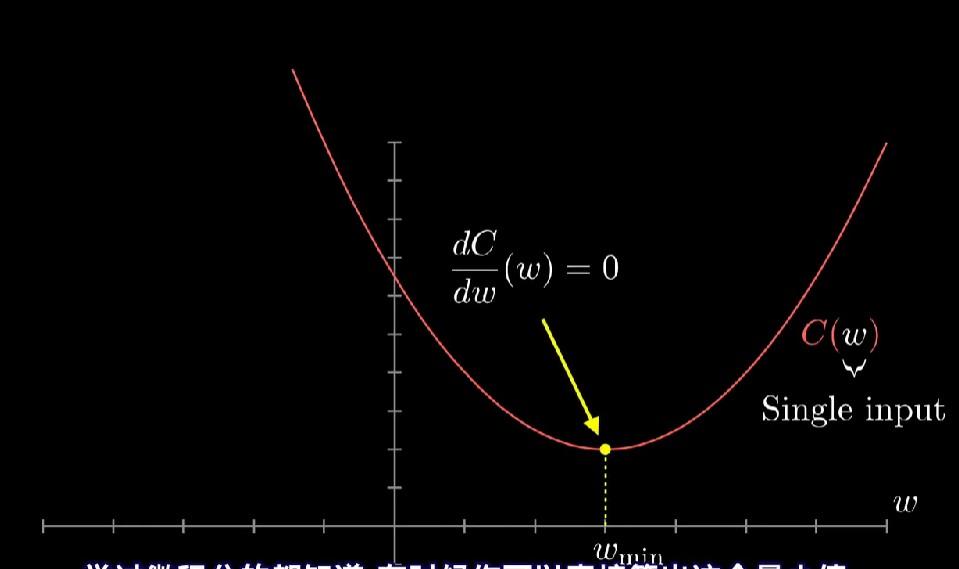
还有一个更灵巧的技巧是先随便挑一个输入值,然后考虑向左还是向右走,函数值才会变小,若找到这里的函数斜率,斜率为正,就向左,斜率为负,就向右走,在每一个点上都这样重复,计算新斜率,再适当地走一小步,就会逼近函数的某个局部最小值(注意,就算很简单的一元函数,由于不知道一开始输入值在哪里,最后你可能会落到许多不同的坑里,且无法保证你落到的局部最小值就是代价函数可能达到的全局最小值。
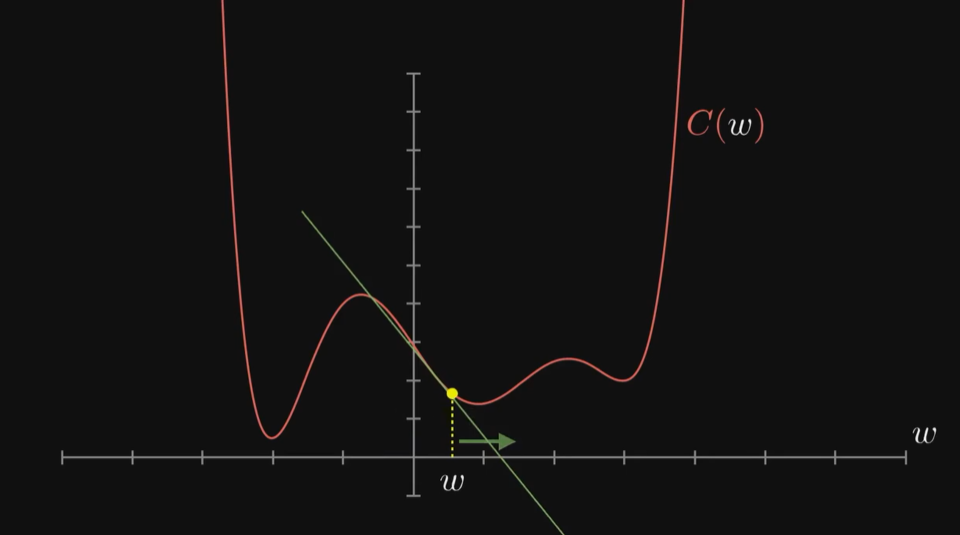
如果每步的大小和斜率成比例,那么在最小值附近斜率会越来越平缓,每步会越来越小,这样可以防止调过头。
多元微积分,函数的梯度指出了函数的最陡增长方向,就是说,按梯度的方向走,函数值增长的就最快,那沿梯度的负方向,函数值自然就降低的最快,

其实不过是先计算梯度,再按梯度反方向走一小步下山,然后循环,处理带13000个输入函数也是一个道理
反向传播算法[BP]

提到让网络学习,实质上就是让代价函数的值最小,为了达到这个结果,代价函数有必要平滑的,这样才能每次挪一点点,最后找到一个局部最小值。
也顺便解释了,为什么人工神经元的激活值是连续的,而非直接沿袭生物学神经元那种二元式的。
按照负梯度的倍数,不停调整函数输入值的过程,就叫做梯度下降法。
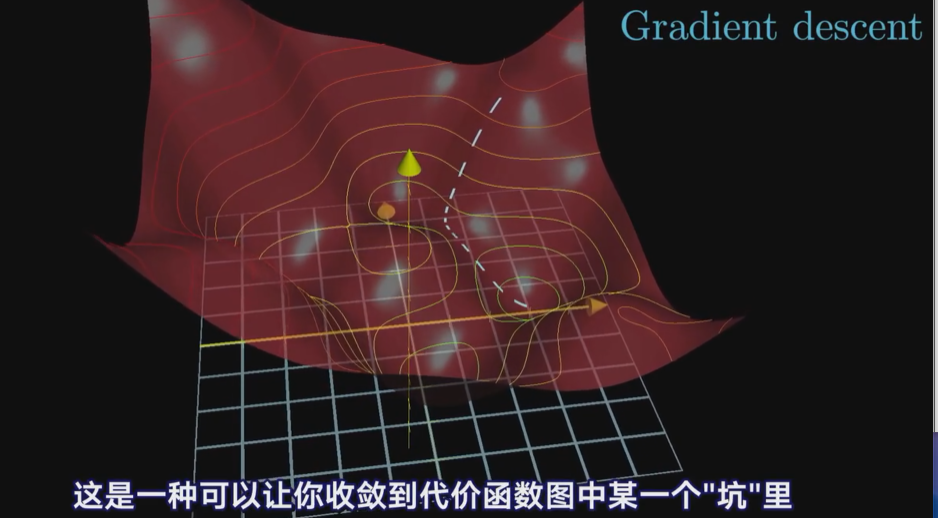
1.改变了那些权重,影响力最大,2.当你随机初始化权重和偏置,通过梯度下降法调整参数




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通