
文本特征抽取








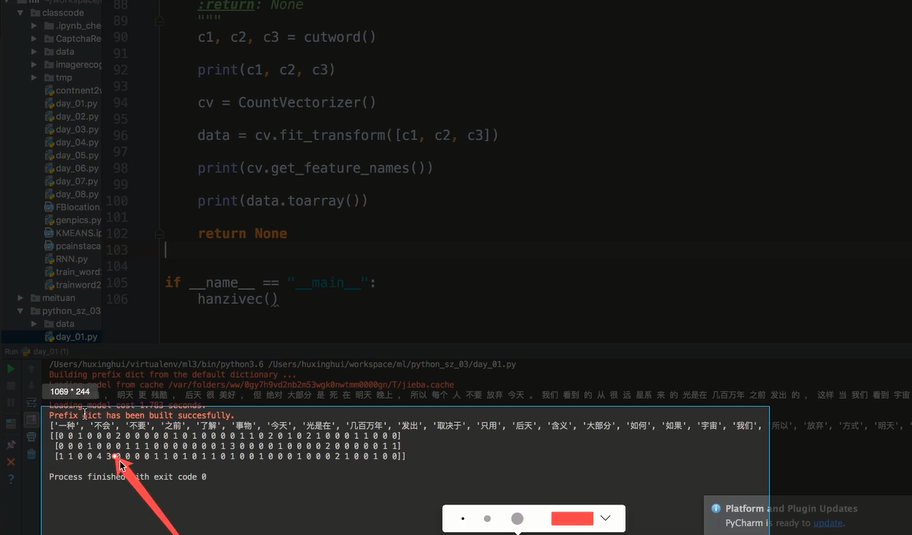

from sklearn.feature_extraction import DictVectorizer # import sklearn # from sklearn.feature_extraction.text import CountVectorizer # # 实例化 CountVectorrizer # vector = CountVectorizer() # # 调用 fit——transform输入并转换数据类型 # res = vector.fit_transform(['life is short,i like python','life is too long, i dislike python']) # # 打印结果 # print(vector.get_feature_names()) # print(res.toarray()) def dictvec(): """ 字典数据抽取 """ # 实例化 dict_ = DictVectorizer(sparse=False) # 调用 fit_transform 转换成数字 data = dict_.fit_transform([{'city':'北京','temperature':100},{'city':'上海','temperature':60},{'city':'深圳','temperature':30}]) print(dict_.get_feature_names()) print(dict_.inverse_transform(data)) print(data) return None from sklearn.feature_extraction.text import CountVectorizer def countvec(): """" 对文本进行特征值化 """ cv = CountVectorizer() data = cv.fit_transform(['人生苦短,我喜欢python','人生漫长,不用python']) print(cv.get_feature_names()) print(data.toarray()) return None import jieba def cutword(): con1 = jieba.cut("今天很残酷,明天更残酷,后天后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天") con2 = jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们呢是在看它的过去") con3 = jieba.cut("如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何2将其与我们所了解的事物相联系") # 转换成列表 content1 = list(con1) content2 = list(con2) content3 = list(con3) # 把列表转换成字符串 c1 = ' '.join(content1) c2 = ' '.join(content2) c3 = ' '.join(content3) return c1, c2, c3 def hanzivec(): """ 中文特征值化 :return:None """ c1,c2,c3 = cutword() print(c1, c2, c3) cv = CountVectorizer() data = cv.fit_transform([c1,c2,c3]) print(cv.get_feature_names()) print(data.toarray()) return None hanzivec()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号