《Function Programming in C++》
说明
《Functional Programming in C++》书中代码练习测试以及一些笔记,部分代码需要用到C++20可以使用在线编译器编译代码
地址:https://coliru.stacked-crooked.com/
或者自己编译gcc-11.2及以上版本安装
1 介绍
1.1 什么是函数式编程
- 用常用的函数范式模板代替一些循环等,比如
std::one_of(),std::count(),std::transform()等 - 使用ranges(C++20)的管道操作
|
1.2 纯函数
函数,只使用(但不修改)传递给它们的参数,以计算出结果
- OOP可以用更好的管理程序状态,但不能减少程序状态
例子,文本编辑器在按保存的时候用户输入了,该保存哪些?
- OOP通过封装活动部件使代码变得易懂。FP通过最大限度地减少活动部件来使代码易于理解。
比如在例子中计算多个文件的行数,如果计算时候文件在改写,那么就要考虑到不同的状态
这种写法可以规避掉count_lines的状态传递
std::vector<int> count_lines_in_files(const std::vector<std::string> &files)
{
reuturn files | transform(count_lines);
}
避免状态改变逐层传递产生耦合!!
1.3 函数式思考
想着输入是什么,输出是什么,怎样把输入映射到输出,而不是算法的每一步去写代码
1.4 函数式编程的好处
1.4.1 代码健壮和可读
函数式写法代码更加精炼
1.4.2 并发和同步
共享改变状态是写并发时的问题。并发编程写纯函数,因为不改变状态,在单线程多线程一样使用
比如
std::vector<double> xs = {1, 2, 3, 4, ...};
auto result = sum(xs | transform(sqrt));
如果sqrt是纯函数,那么求和算法就可以切块累加然后合并了,不管是单线程还是多线程都可以运行
由于C++没有纯函数的标记,所以不能自动并行。如果是循环就没有那么轻易地实现并行了
注意,C++编译器在发现循环体为纯的时候会自动向量化或者做其他优化
1.4.3 持续优化
2 开始函数式编程
2.1 函数把函数当参数
对于过滤人群的函数调用,可以总结为
filter: (collection<T>, (T → bool)) → collection<T>
而结构体的映射转换使用的transform原型为
transform: (collection<In>, (In → Out)) → collection<Out>
2.2 STL例子
2.2.1 计算均值
通常做法
double average_score(const std::vector<int> &scores)
{
int sum = 0;
for (int score: scores) {
sum += score;
}
return sum / (double) scores.size();
}
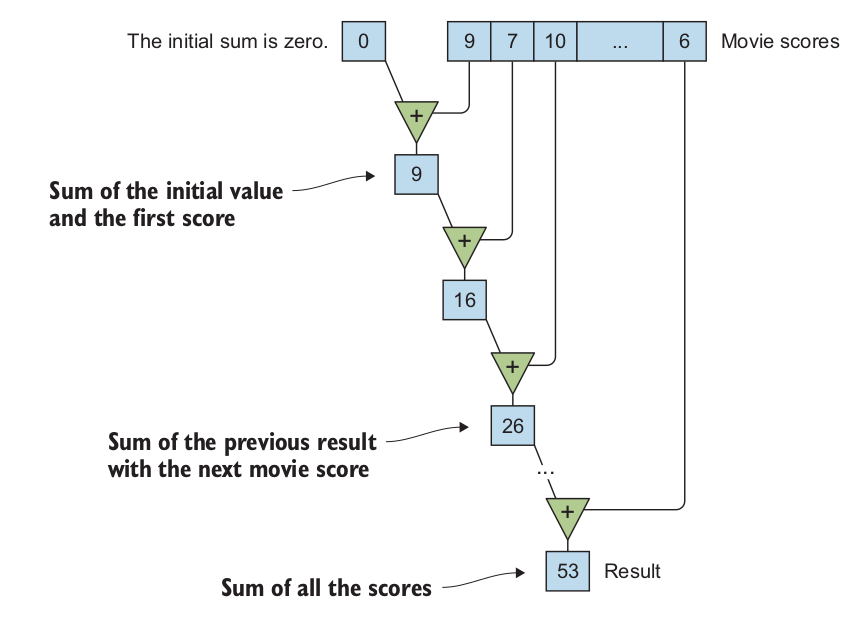
我们可以使用std::accumulate来实现:
double average_score(const std::vector<int> &scores)
{
return std::accumulate(scores.cbegin(), scores.cend(), 0) /
(double) scores.size();
}
并行版本的算法,需要使用execution里面的函数std::reduce
double average_score(const std::vector<int>& scores)
{
return std::reduce(
std::execution::par,
scores.cbegin(), scores.cend(),
0
) / (double) scores.size();
}
编译并行程序如果出现问题,例如
error: #error Intel(R) Threading Building Blocks 2018 is required; older versions are not supported.
需要编译最新版本的TBB库,教程在:https://github.com/oneapi-src/oneTBB/blob/master/INSTALL.md
2.2.2 折叠
std::accumulate`也可以自定义操作符,或者使用已经有的例如`std::multiplies
std::accumulate是特殊的函数,会顺序执行,不能够进行并行化
使用std::accumulate计算行数
int f(int previous_count, char c)
{
return (c != '\n') ? previous_count
: previous_count + 1;
}
int count_lines(const std::string & s)
{
return std::accumulate(
s.cbegin(), s.cend(),
0,
f
);
}
该方法用f函数判断是否是回车符,自定义了std::accumulate的运算函数。如果需要从尾部运算到头部,把迭代器cbegin换成crbegin就可以了
2.2.3 字符串修剪
需要用到的算法是std::find_if
bool is_not_space(char c)
{
return c != ' ';
}
std::string trim_left(std::string s)
{
s.erase(s.begin(),
std::find_if(s.begin(), s.end(), is_not_space));
return s;
}
std::string trim_right(std::string s)
{
s.erase(std::find_if(s.rbegin(), s.rend(), is_not_space).base(),
s.end());
return s;
}
std::string trim(std::string s)
{
return trim_left(trim_right(std::move(s)));
}
使用base()函数把反向迭代器转换成正向迭代器
2.2.4 集合划分
使用std::partition和std::stable_partition可以把集合按照特定要求一分为二排列
比如把女性放队列前面
std::partition(
people.begin(), people.end(),
is_female
);
而两者的区别就是std::partition排列的时候不会考虑相同类之间元素的顺序,效率相对后者较高。而std::stable_partition会保持同类元素之间的相对顺序
2.2.5 过滤和变换
使用std::remove_if过滤
people.erase(
std::remove_if(people.begin(), people.end(),
is_not_female),
people.end());
std::remove或者std::remove_if并不能真正的删除元素,而是把要删除的元素移动到末尾,配合std::erase来彻底删除元素
使用std::copy_if拷贝特定元素
std::vector<person_t> females;
std::copy_if(people.cbegin(), people.cend(),
std::back_inserter(females),
is_female);
std::back_inserter可以在原有集合的基础上提供向后插入的容器,由于std::copy_if事先并不知道需要拷贝多少元素,所以需要动态扩充的容器来进行拷贝
std::copy_if四个参数的原型
template<class InputIt, class OutputIt, class UnaryPredicate>
OutputIt copy_if(InputIt first, InputIt last,
OutputIt d_first, UnaryPredicate pred)
{
while (first != last) {
if (pred(*first))
*d_first++ = *first;
first++;
}
return d_first;
}
可以看到std::copy_if并不会扩充目标容器
用std::copy_if除了拷贝到std::back_inserter容器里面还可以拷贝到流里面,比如
std::ostream_iterator<int>(std::cout, " ")
2.3 STL算法的兼容性问题
通常STL算法的兼容性都比手写循环兼容性好,比如以下找出所有女性并把名字存储记录的代码
std::vector<std::string> names;
for (const auto &person : people) {
if (is_female(person)) {
names.push_back(name(person));
}
}
使用transform加上filter函数可以简洁,原型如下
filter : (collection<T>, (T -> bool)) -> collection<T>
transform : (collection<T>, (T -> T2)) -> collection<T2>
filter是C++20里面的,在<ranges>头文件里面
std::vector<std::string> names;
transform(filter(people, is_female), name);
利用filter过滤出符合的元素然后进行一对一的集合元素转换
使用该方法解决了两个算法之间存在中介变量的问题,比如需要生命临时的用来存女性的集合的数组
使用两次std::copy_if也能达到std::stable_partition的功能
std::vector<person_t> separated(people.size());
const auto last = std::copy_if(
people.cbegin(), people.cend(),
separated.begin(),
is_female);
std::copy_if(
people.cbegin(), people.cend(),
last,
is_not_female);
2.4 编写自己的高等级函数
很多STL算法在第三方库里面也有实现,比如Boost
2.4.1 以变量的方式接收函数
例如
template <typename FilterFunction>
std::vector<std::string> names_for(
const std::vector<person_t> &people,
FilterFunction filter);
2.4.2 使用循环实现
template <typename FilterFunction>
std::vector<std::string> names_for(
const std::vector<person_t> &people,
FilterFunction filter)
{
std::vector<std::string> result;
for (const person_t &person : people) {
if (filter(person)) {
result.push_back(name(person));
}
}
return result;
}
2.4.3 递归和尾随调用优化
上面用循环的方式,每次找到一个人,都会相应的更改结果
使用递归方式如下:
template <typename FilterFunction>
std::vector<std::string> names_for(
const std::vector<person_t>& people,
FilterFunction filter)
{
if (people.empty()) {
return {};
} else {
const auto head = people.front();
const auto processed_tail = names_for(
tail(people),
filter);
if (filter(head)) {
return prepend(name(head), processed_tail);
} else {
return processed_tail;
}
}
}
该实现方式并不高效,vector并没有现成的tail函数,需要自己实现
另外一种实现方式如下:
template <typename FIlterFunction, typename Iterator>
std::vector<std::string> names_for(
Iterator people_begin,
Iterator people_end,
FilterFunction filter)
{
...
const auto processed_tail = names_for(
people_begin + 1,
people_end,
filter);
...
}
第二种实现方法也会有每次都会在vector后面添加的情况,但是每次迭代占用的栈内存开销都很大,有些甚至会溢出崩溃
尾部递归的实现:
template <typename FilterFunction, typename Iterator>
std::vector<std::string> names_for_helper(
Iterator people_begin,
Iterator people_end,
FilterFunction filter,
std::vector<std::string> previously_collected)
{
if (people_begin == people_end) {
return previously_collected;
}
const auto head = *people_begin;
if (filter(head)) {
previously_collected.push_back(name(head));
}
return names_for_helper(
people_begin + 1,
people_end,
filter,
std::move(previously_collected));
}
// 调用函数
template <typename FilterFunction, typename Iterator>
std::vector<std::string> names_for_helper(
Iterator people_begin,
Iterator people_end,
FilterFunction filter)
{
names_for_helper(people_begin, people_end, filter, {});
}
2.4.4 使用折叠实现
递归是一种低层次的结构,通常在春FP函数中会加以避免,前面说高层次的结构在FP里面更受欢迎,因为因为递归错综复杂
使用std::accumulate实现
std::vector<std::string> append_name_if(
std::vector<std::string> previously_collected,
const person_t &person)
{
if (filter(person)) {
previously_collected.push_back(name(person));
}
return previously_collected;
}
...
return std::accumulate(
people.cbegin(),
people.cend(),
std::vector<std::string>{},
append_name_if);
但是该例子里面有个重要的问题是拷贝次数太多了,每次调用append_name_if都会生成previously_collected的拷贝,C++20里面优化了std::accumulate的拷贝问题,也可以自己实现move_accumulate方法,以下是C++20优化后的实现
template<class InputIt, class T, class BinaryOperation>
constexpr // since C++20
T accumulate(InputIt first, InputIt last, T init,
BinaryOperation op)
{
for (; first != last; ++first) {
init = op(std::move(init), *first); // std::move since C++20
}
return init;
}
3 函数对象
3.1 函数和函数对象
两种不同的写法
int max(int arg1, int arg2) { ... }
auto max(int arg1, int arg2) -> int { ... }
3.1.1 自动类型推导
int answer = 42;
auto ask1() { return answer; }
const auto &ask2() { return answer; }
使用decltype(auto)返回值
template <typename Object, typename Function>
decltype(auto) call_on_object(Object &&object, Function function)
{
return function(std::forward<Object>(object));
}
变量完美转发
使用折叠引用和std::forward
3.1.2 函数指针
int ask() { return 42; }
typedef decltype(ask) * function_ptr;
class convertible_to_function_ptr {
public:
operator function_ptr() const //函数指针callable_object
{
return ask;
}
};
int main()
{
auto ask_ptr = &ask;
std::cout << ask_ptr() << '\n'; //调用函数指针
auto ask_ref = ask;
std::cout << ask_ref() << '\n'; //调用函数引用
convertible_to_function_ptr ask_wrapper;
std::cout << ask_wrapper() << '\n'; // 对象转换成函数指针
}
3.1.3 重载调用操作符
语法:
class function_object {
public:
return_type operator()(arguments) const
{
...
}
};
要取出年龄大于42岁的人,通常可以这么做
bool older_than_42(const person_t& person)
{
return person.age > 42;
}
std::count_if(persons.cbegin(), persons.cend(),
older_than_42);
但是这种方式并不通用,更加通用的办法是创建一个callable类,把42当构造参数传入
class older_than
{
public:
older_than(int limit) : m_limit(limit) {}
bool operator() (const person_t &person) const
{
return person.age() > m_limit;
}
private:
int m_limit;
}
older_than older_than_42(42);
std::count_if(persons.cbegin(), persons.cend(),
older_than(42));
std::count_if并不需要传入参数为函数指针,只需要是能够被调用的就行
3.1.4 创建通用函数对象
用于通用对象的比较函数对象
template<typename T>
class older_than {
public:
older_than(int limit) :
m_limit(limit) {}
bool operator()(const T &object) const
{
return object.age() > m_limit;
}
private:
int m_limit;
};
std::count_if(persons.cbegin(), persons.cend(),
older_than<person_t>(42));
std::count_if(cars.cbegin(), cars.cend(),
older_than<car_t>(5));
std::count_if(projects.cbegin(), projects.cend(),
older_than<project_t>(42));
上面函数对象以来类型来创建,通过只设置单个函数为模板函数创建能够自动推导类型的函数对象模板,使其更加通用
class older_than {
public:
older_than(int limit) : m_limit(limit) {}
template<typename T>
bool operator()(T &&object) const
{
return std::forward<T(object).age() > m_limit;
}
};
older_than predicate(5);
std::count_if(persons.cbegin(), persons.cend(), predicate);
std::count_if(cars.cbegin(), cars.cend(), predicate);
std::count_if(projects.cbegin(), projects.cend(), predicate);
3.2 Lambda表达式和闭包
使用 lambda 表达式
std::copy_if(people.cbegin(), people.cend(),
std::back_inserter(females),
[](const person_t& person) {
return person.gender() == person_t::female;
}
);
3.2.1 Lambda表达式语法
[a, &b] (int x, int y) { return a * x + b * y; }
头 变量 函数体
不同函数头的作用
[a, &b]—— a值抓取,b引用抓取[]—— 不使用附近作用域[&]—— 引用抓取所有函数体用过的变量[=]—— 值抓取所有函数体用过的变量this—— 抓取this指针[&, a]—— 除了a按值抓取,其他都按引用抓取[=, &b]—— 除了b按引用抓取,其他都按值抓取
3.2.2 使用lambda表达式
class company_t {
public:
std::string team_name_for(const person_t &employee) const;
int count_team_members(const std::string &team_name) const;
private:
std::vector<person_t> m_employees;
...
};
int company_t::count_team_members(const std::string &team_name) const
{
return std::count_if(
m_employees.cbegin(), m_employees.cend(),
[this, &team_name](const person_t &employee) {
return team_name_for(employee) == team_name;
}
);
}
使用mutable关键字标记的lambda表达式可以告诉编译器这个lambda上的调用操作符不应该是常数
int count = 0;
std::vector<std::string> words{"An", "ancient", "pond"};
当声明一个lambda表达式,编译器就会声明一个callable类,
()操作符为函数
3.2.3 在lambdas中创建任意的成员变量
使用值抓取move only类型std::unique_ptr时会有问题
std::unique_ptr<sesson_t> session = create_sesson();
auto request = server.request("GET /", session->id());
request.on_complete(
[session]
(response_t response)
{
std::cout << "Got response: " << response
<< " for session: " << session;
}
);
上述方式会报错,需要在抓取的时候使用移动语义std::move
request.on_complete(
[ session = std::move(session),
time = current_time()
]
(response_t response)
{
std::cout << "Got response: " << response
<< " for session: " << session
<< " the request took: "
<< (current_time() - time)
<< "milliseconds";
}
);
time在创建该匿名函数时就已经定义好了,无论后续在哪里调用
3.2.4 通用lambda表达式
lambda表达式参数支持auto关键字,能够根据调用入参自己选择类型
auto predicate = [limit = 42] (auto &&object) {
return object.age() > limit;
}
std::count_if(persons.cbegin(), persons.cend(),
predicate);
std::count_if(cars.cbegin(), cars.cend(),
predicate);
std::count_if(projects.cbegin(), projects.cend(),
predicate);
C++20中更加通用的lambda表达式
支持使用decltype
[] (auto first, decltype(first) second) { … }
或者使用模板
[] <typename T> (T first, T second) { … }
3.3 编写比lambda表达式更复杂的函数对象
写过滤函数需要重复很多代码
ok_response = filter(response,
[] (const response_t &response) {
return !response.error();
});
failed_response = filter(response,
[] (const response_t &response) {
return response.error();
});
理想的调用方式是这样的
ok_response = filter(response, not_error);
// 或者 filter(response, !error);
// 或者 filter(response, error == false);
failed_response = filter(response, error);
// 或者 filter(response, not_error == false);
// 或者 filter(response, error == true);
需要定义一个类,存储一个bool类型
class error_test_t {
public:
error_test_t(bool error = true) : m_error(error) {}
template <typename T>
bool operator()(T &&value) const
{
return m_error == (bool) std::forward<T>(value).error();
}
private:
bool m_error;
};
error_test_t error(true);
error_test_t not_error(false);
如果需要支持!操作,还要重载该操作符
class error_test_t {
public:
...
error_test_t operator==(bool test) const
{
return error_test_t(
test ? m_error : !m_error
);
}
error_test_t operator!() const
{
return error_test_t(!m_error);
}
};
3.3.1 STL中的操作符函数对象
STL中的操作符函数对象可以用在排序和累计中
std::vector<int> numbers{1, 2, 3, 4};
product = std::accumulate(numbers.cbegin(), numbers.cend(), 1,
std::multiplies<int>());
std::vector<int> numbers{5, 21, 13, 42};
std::sort(numbers.begin(), numbers.end(), std::greater<int>());
// numbers now contain {42, 21, 13, 5}
// 算术操作
std::plus
std::minus
std::multiplies
std::divides
std::modulus // %
std::negates // -a
// 比较操作
std::equal_to
std::not_equal_to
std::greater
std::less
std::greater_equal
std::less_equal
// 逻辑操作
std::logical_and
std::logical_or
std::logical_not
// 位操作
std::bit_and
std::bit_or
std::bit_xor
C++14中,在使用标准库中的运算符包装器时,你可以省略该类型。直接使用std::greater<>(),而不是std::greater<int>()
3.3.2 其他库中的操作符函数对象
Boost库。比如Boost库中的phoenix
using namespace boost::phoenix::arg_names;
std::vector<int> numbers{21, 5, 62, 42, 53};
std::partition(numbers.begin(), numbers.end(),
arg1 <= 42);
// numbers now contain {21, 5, 42, 62, 53}
// <= 42 > 42
arg1为定义的占位符,该函数代表按照第一个变量把集合划分开
然后还可以运用在其他上,比如累加
std::accumulate(numbers.cbegin(), numbers.cend(), 0,
arg1 + arg2 * arg2 / 2);

也可以算乘法或者进行排序
product = std::accumulate(numbers.cbegin(), numbers.cend(), 1,
arg1 * arg2);
std::sort(numbers.begin(), numbers.end(), arg1 > arg2);
3.4 使用std::function包装函数
std::function<float (float, float)> test_function;
test_function = std::fmaxf; // 函数
test_function = std::multiplies<float>(); // 类的调用函数
test_function = std::multiplies<>(); // 类通用调用函数
test_function = [x] (float a, float b) { return a * x + b; }; // lambda表达式
test_function = [x] (auto a, auto b) { return a * x + b; }; // 通用lanbda表达式
test_function = (arg1 + arg2) / 2; // boost.phoenix 表达式
test_function = [](std::string s) { return s.empty(); } // 错误
std::function本质上是重载了()操作符的可调用类(callable)
std::function在绑定函数时需要用到std::ref确保是引用传参
std::function<void()> bound_f = std::bind(f, n1, std::ref(n2), std::cref(n3));
4 从旧的函数创建新的函数
4.1 部分功能的应用
之前的比较是用模板的形式,涉及到具体对象的方法,并不通用,下面采用的是重载调用操作符
class greater_than {
public:
greater_than(int value) : m_value {}
bool operator()(int arg) const
{
return arg > m_value;
}
private:
int m_value;
};
...
greater_than greater_than_42(42);
greater_than_42(1); // false
greater_than_42(50); // true
std::partition(xs.begin(), xs.end(), greater_than(6));
4.1.1 将二元操作函数转换为单一函数的通用方法
更通用的方式封装别的用户的二元操作函数,比如说>是两个操作变量,greater_than把一个变量构造函数传入进去,变成一个一元函数
template<typename Function, typename SecondArgType>
class partial_application_on_2nd_impl {
public:
partial_application_on_2nd_impl(Function function,
SecondArgType second_arg)
: m_function(function)
, m_value(second_arg)
{}
template<typename FirstArgType>
auto operator()(FirstArgType &&first_arg) const
-> decltype(m_function(
std::forward<FirstArgType>(first_arg),
m_second_arg))
{
return m_function(
std::forward<FirstArgType>(first_arg),
m_second_arg);
}
...
private:
Function m_function;
SecondArgType m_second_arg;
};
// 绑定函数
template<typename Function, typename SecondArgType>
partial_application_bind2nd_impl<Function, SecondArgType>
bind2nd(Function &&function, SecondArgType &&second_arg)
{
return partial_application_bind2nd_impl<Function, SecondArgType>(
std::forward<Function>(function),
std::forward<SecondArgType>(second_arg));
}
auto greater_than_42 = bind2nd(std::greater<int>(), 42);
greater_than_42(1); // false
greater_than_42(50); // true
使用bind2nd把角度转换成弧度
// 把角度转换成弧度
std::vector<double> degrees = {0, 30, 45, 60};
std::vector<double> radians(degrees.size());
std::transform(degrees.cbegin(), degrees.cend(),
radians.begin(),
bind2nd(std::multiplies<double>, PI / 180));
4.1.2 使用std::bind指定函数变量
std::bind1st`和`std::bind2nd`都被弃用了,可以使用`std::bind
auto bound = std::bind(std::greater<double>(), _1, 42);
bool is_6_greater_than_42 = bound(6);
占位符_1和_2在<functional>头文件的命名空间std::placeholders里面
通过绑定不同的占位符变为不同的操作
auto is_greater_than_42 =
std::bind(std::greater<double>(), _1, 42);
auto is_less_than_42 =
std::bind(std::greater<double>(), 42, _1);
4.1.3 反转二元操作函数的变量
可以把_1和_2位置调换,使得变量传入也交换
std::sort(scores.begin(), scores.end(),
std::bind(std::greater<double>, _2, _1));
4.1.4 使用std::bind处理更多变量的函数
enum output_format_t
{
name_only,
full_name,
};
void print_person(const person_t &person,
std::ostream &out,
person_t::output_format_t format);
std::for_each(people.cbegin(), people.cend(),
std::bind(print_person,
_1,
std::ref(std::cout),
person_t::name_only
));
也可以绑定类成员函数,比如print在person_t中
class person_t {
public:
...
void print(std::ostream &out, person_t::output_format_t format);
}
std::for_each(people.cbegin(), people.cend(),
std::bind(&person_t::print,
_1,
std::ref(std::cout),
person_t::name_only
));
4.1.5 使用lambda表达式替代std::bind
auto is_greater_than_42 =
[] (double value) {
return std::greater<double>()(value, 42);
};
auto is_less_than_42 =
[] (double value) {
return std::greater<double>()(42, value);
};
排序的实现
std::sort(scores.begin(), scores.end(),
[] (double value1, double value2) {
return std::greater<double>()(value2, value1);
});
打印的实现
std::for_each(people.cbegin(), people.cend(),
[] (const person_t &person) {
print_person(person,
std::cout,
person_t::name_only);
});
std::for_each(people.cbegin(), people.cend(),
[&file] (const person_t &person) {
print_person(person,
file,
person_t::name_only);
});
4.2 Currying:不同的方式看函数
柯理化(currying):从Haskell引进的词汇,把一个多参数函数转换成单参数函数, 并且返回一个能接受余下参数并返回结果的新函数。
例如,一个函数f0需要输出2个参数,Currying后,第一个函数f1接收第一个参数a1后返回一个函数f2,f2接受第二个参数a2后返回最终结果
// 正常版本的调用
int result = f0(10, 2);
// Currying版本的调用
auto f1 = f0(10);
int f2 = f1(2);
大于函数的Currying版本
// greater : (double, double) -> bool
bool greater(double first, double second)
{
return first > second;
}
// greater_curried : double → (double → bool)
auto greater_curried(double first)
{
return [first] (double second) {
return first > second;
}
}
greater(2, 3); // false
greater_curried(2); // 返回函数对象
greater_curried(2)(3); // false
4.2.1 更方便的创建Currying函数的方式
auto print_person_cd(const person_t &person)
{
return [&] (std::ostream &out) {
return [&] (person_t::output_format_t format) {
print_person(person, out, format);
}
}
}
使用make_curried,后面第11章节会提供代码
using std::cout;
auto print_person_cd = make_curried(print_person);
// 所有的方式都可以调用
print_person_cd(martha, cout, person_t::full_name);
print_person_cd(martha)(cout, person_t::full_name);
print_person_cd(martha, cout)(person_t::full_name);
print_person_cd(martha)(cout)(person_t::full_name);
auto print_martha = print_person_cd(martha);
print_martha(cout, person_t::name_only);
auto print_martha_to_cout = print_person_cd(martha, cout);
print_martha_to_cout(person_t::name_only);
注意并不是所有的调用方式都可以,必须确保按照变量输入的先后顺序来进行
4.2.2 使用Currying处理数据库权限
result_t query(connection_t &connection,
session_t &session,
const std::string &table_name,
const std::string &filter);
考虑单一数据库,单一连接情况,创建一个query函数,使其能够满足以下API操作
auto table = "Movies";
auto filter = "Name = \"Sintel\"";
results = query(local_connection, session, table, filter);
auto local_query = query(local_connection);
auto remote_query = query(remote_connection);
results = local_query(session, table, filter);
auto main_query = query(local_connection, main_session);
results = main_query(table, filter);
auto movies_query = main_query(table);
results = movies_query(filter);
4.2.3 Currying和部分函数应用
部分函数应用(Partial function application):部分函数的应用是指以少于其总参数数的方式调用一个多参数函数。这将导致一个新的函数接受剩余的参数数。通过部分函数应用创建的简单函数是非常有用的,而且通常比匿名函数的语法要求要少得多1。
部分函数应用可以改变绑定变量顺序,而Currying先绑定第一个变量,这个是区别
auto local_query = query(local_connection);
auto local_query = std::bind(query, local_connection, _1, _2, _3);
auto session_query = std::bind(query, _1, main_session, _2, _3);
当你有一个特定的函数,你想绑定它的参数时,部分函数应用很有用。在这种情况下,你知道这个函数有多少个参数,你可以准确地选择你想绑定到一个特定的值的参数。当你可以得到一个有任意数量参数的函数时,Currying在一般情况下特别有用。因为在这种情况下,不知道变量个数意味着std::bind就不能实现。
4.3 函数构成
《编程珠玑》里面的“读取一个文本文件,确定最常使用的n个词,并打印出这些词的排序列表及其频率。”问题,Doug McIlroy的UNIX shell脚本解决方式:
tr -cs A-Za-z '\n' |
tr A-Z a-z |
sort |
uniq -c |
sort -rn |
sed ${1}q
用C++来解决该问题的转换步骤:
- 有一个文件。从里面把单词分出来
- 把分出来的单词放到无序map里面
std::unordered_map<std::string, unsigned int>,把每个单词的数目记录 - 遍历map中的元素,把map转换成pair,并且数目在前
- 排序
- 打印
我们可以创建根据其他元素类型容器决定元素类型的容器
template <typename C,
typename T = typename C::value_type>
std::unodered_map<T, unsigned int> count_occurrences(const C &collection);
最终看起来的形式
void print_common_words(const std::string& text)
{
return print_pairs(
sort_by_frequency(
reverse_pairs(
count_occurrences(
words(text)
)
)
)
);
}
4.4 再谈函数提升
提升(lifting)是一个编程术语,给你提供了一种方法,将一个给定的函数转化为一个适用于更广泛背景的类似函数。
提升是一个概念,它允许你将一个函数转化为另一个(通常是更一般的)环境中的相应函数。2
拿字符串转大写举例
void to_upper(std::string &string);
实现方法比如:
void pointer_to_upper(std::string* str)
{
if (str) to_upper(*str);
}
void vector_to_upper(std::vector<std::string>& strs)
{
for (auto& str : strs) {
to_upper(str);
}
}
void map_to_upper(std::map<int, std::string>& strs)
{
for (auto& pair : strs) {
to_upper(pair.second);
}
}
这种实现方法看起来毫无价值,实现取决于容器类型,不得不去实现针对各种变量类型的方法
应该创建一个high-order函数,只关注于操作单一的字符串,和一个函数处理字符串指针,创建一个函数处理字符串向量和字符串map。这些函数称为提升函数,因为它们将对某一类型进行操作的函数提升到一个结构或包含该类型的集合。
使用C++14特性来实现
void to_upper(std::string &string);
// 指针提升
template <typename Function>
auto pointer_lift(Function f)
{
return [f] (auto *item) {
if (item) {
f(*item);
}
}
}
// 集合提升
template <typename Function>
auto collection_lift(Function f)
{
return [f] (auto &items) {
for (auto &item : items) {
f(item);
}
};
}
// 例子
std::string str{"lift"};
std::string *pstr = new std::string{"lift"};
std::vector<std::string> vstr{"lift", "function"};
to_upper(str);
pointer_lift(to_upper)(pstr);
collection_lift(to_upper)(vstr);
4.4.1 颠倒成对的列表
在之前那个问题中,第3步,涉及需要把map转化成pair集合并且数目要提到前面去,代码如下
template <typename C,
typename P1 = typename std::remove_cv<
typename C::value_type::first_type>::type,
typename P2 = typename C::value_type::second_type
>
std::vector<std::pair<P2, P1>> reverse_pairs(const C &items)
{
std::vector<std::pair<P2, P1>> result(item.size());
std::transform(
std::begin(items), std::end(items),
std::begin(result),
[] (const std::pair<const P1, P2> &p) {
return std::make_pair(p.second, p.first);
}
);
return result;
}
std::remove_cv`可以移除`const`和`volatile
5 纯粹:避免可变状态
5.1 可变状态的问题
例如电影类movie_t
// 电影类
class movie_t {
public:
double average_score() const;
...
private:
std::string name;
std::list<int> scores;
};
// 计算平均评分的方法
double movie_t::average_score() const
{
return std::accumulate(scores.begin(),
scores.end(), 0)
/ (double) scores.size();
}
问题出现在当你在计算平均分时别人在添加分数,新添加的可能在里面也可能不在里面。.size()函数可能返回的时之前的大小。也就是迭代器事先确定好了,但是计算的时候又加了元素,所以size会变大,平均值变小了。
C++11之前的std::list并不会保存列表大小,所以每次都会重新遍历计算。所以需要在电影类里面自己存储一个size
class movie_t {
public:
double average_score() const;
...
private:
std::string name;
std::list<int> scores;
size_t scores_size;
};
但是这样做的坏处时当项目越来越大,这种变量越来越多,重构的难度就越来越大。需要确保变量在使用的时候不可被修改。
5.2 纯粹的函数和指称的透明度
这些问题都来自一个设计缺陷:让软件系统中的几个组件负责相同的数据,而不知道另一个组件何时改变该数据。避免该问题出现的最简单的办法是禁止数据改动。
但是说起来简单做起来难。很多时候和用户交互面临这个问题。保存的时候用户在进行输入,一个按钮按下,其他按钮不知道用户鼠标点击了什么。
但是如果不提交改变任何状态,就不可能做任何事。只能计算你自己传入参数的程序。你不能 做交互程序,不能保存数据到磁盘或者数据库,不能发送网络请求等。程序就毫无用处。
首先还是理解纯和不纯函数。第1章说纯函数只使用传递给它们的参数值,以便返回结果。它们不需要有任何副作用来影响你程序中的任何其他函数或你系统中的任何其他程序。纯函数还需要在用相同的参数调用时总是返回相同的结果。
现在通过一个概念名为引用透明性(referential transparency)更精确的定义纯粹,引用透明性是表达式的一个特征,而不仅仅是函数。我们可以说表达式是任何指定计算并返回结果的东西。如果我们把整个表达式替换成它的返回值,程序的行为也不会有什么不同,我们就说表达式是引用透明性的。如果一个表达式是引用透明性的,那么它就没有可观察到的副作用,因此该表达式中使用的所有函数都是纯的。
参考透明度,是函数式编程中常用的一个术语,意味着给定一个函数和一个输入值,你将总是收到相同的输出。这就是说,在函数中没有使用外部状态。 也就是函数的输出只取决于他的输入3
例如
// 全局变量G
int G = 10;
// 引用透明
int pulsOne(int x)
{
return x + 1;
}
// 非引用透明
int plusG(int x)
{
return x + G;
}
如果一个表达式是引用透明的,那么它就没有可观察的副作用(observable side effects),因此该表达式中使用的所有函数都是纯的。
搜索和打印最大值
double max(const std::vector<double> &numbers)
{
assert(!numbers.empty());
auto result = std::max_element(numbers.cbegin(),
numbers.cend());
std::cerr << "Maximum is: " << *result << std::endl;
return *result;
}
int main()
{
auto sum_max =
max({1}) +
max({1, 2}) +
max({1, 2, 3});
std::cout << sum_max << std::endl;
}
相比以下代码
int main()
{
auto sum_max =
1 +
2 +
3;
std::cout << sum_max << std::endl;
}
前面的max函数也能得出最后一样的结果,但是在这个过程中有输出打印到std::cerr了,所以并不是纯粹的。
5.3 无副作用编程
在纯函数变成中,创建新的值而不是改变值。不是改变对象的值,而是从之前那个对象创建拷贝,这个拷贝中值已经改变为新的。在电影例子中,当你在计算电影分数时,你已经有电影分数列表,别人不能更改,他们只能创建一个新的列表,在这个列表中加入新的分数。
这种方法起初听起来是反直觉的;它似乎与我们通常认为的世界运作方式相反。但奇怪的是,它背后的想法几十年来一直是科幻小说的一部分,甚至被一些古希腊哲学家所讨论。有一个流行的概念,即我们生活在许多平行世界中的一个–每当我们做出一个选择,我们就会创造一个新的世界,在这个世界中我们做出了确切的选择,还有一些平行世界,我们在其中做出了不同的选择。
在编程时,我们通常不关心所有可能的世界;我们只关心一个。这就是为什么我们认为我们在改变一个单一的世界,而不是一直在创造新的世界并抛弃以前的世界。这是一个有趣的概念,不管这是否是世界的运作方式,它在开发软件时确实有其优点。
在迷宫中行走的例子
while (1) {
- 绘制迷宫和玩家
- 读取用户输入
- 是否可以移动(按下方向箭头键)检查目的地单元是否是墙,不是墙则移动到目的地
- 检查是否到达退出点,到达则显示消息,退出循环
}
首先,迷宫不会改变,玩家的状态会改变,迷宫可以用不可改变的类。
在移动的过程中,我们需要计算以下内容:
- 移动的方向
- 之前的位置,知道从哪里移动
- 是否能够移动到目的地
position_t next_position(
direction_t direction,
const position_t &previous_position,
const maze_t &maze)
{
const position_t desired_position{previous_position, direction};
return maze.is_wall(desired_position) ? previous_postion
: desired_position;
}
position_t::position_t(const position_t &original,
direction_t direction)
: x { direction == Left ? original.x - 1 :
direction == Right ? original.x + 1 :
original.x }
, y { direction == Up ? original.y + 1 :
direction == Down ? original.y - 1 :
original.y }
{}
最终的循环
void process_events(const maze_t &maze,
const position_t ¤t_position)
{
if (maze.is_exit(current_position)) {
return;
}
const direction_t direction = ...;
draw_maze();
draw_player(current_position, direction);
const auto new_position = next_position(direction,
current_position,
maze);
process_events(maze, new_position);
}
int main()
{
const maze_t maze("maze.data");
process_events(maze, maze.start_position());
}
更大的组件需要考虑使用moveable组件。你可以创建一个巨大的、包罗万象的世界结构,每当你需要改变其中的某些东西时,你就会重新创建。这将有很大的性能开销(即使你使用为函数式编程优化的数据结构,如第8章所述),并会大大增加你的软件的复杂性。
相反,你通常会有一些可变的状态,你认为总是要复制和传递是低效的,你会对你的函数进行建模,使它们返回关于世界上应该改变的语句,而不是总是返回世界的新副本。这种方法所带来的是系统的可变和纯粹部分之间的明确分离。(设计模式中的命令模式)
5.4 并发环境下的可变和不可变状态
可变的状态会导致问题,因为它允许共享责任(这甚至违背了最佳的OOP实践)。这些问题在并发环境中得到了提升,因为责任可以由多个组件同时分担。
void client_disconnected(const client_t &client)
{
// 释放客户端资源
...
// 减少连接数目
connected_clients--;
if (connected_clients == 0) {
// 省电模式
}
}
并行运行的时候connected_clients--会同时执行,比如初值为2,两个都是2-1=1,最终结果变为1。简单的解决办法:让编程人员通过mutexes来禁用数据的并发。
我经常开玩笑说,与其捡起Djikstra的可爱缩写(mutex–代表互斥),不如把基本的同步对象称为 “瓶颈”。瓶颈有时是有用的,有时是不可缺少的,但它们从来不是好事。在最好的情况下,它们是一种必要的邪恶。任何鼓励任何人过度使用瓶颈、将瓶颈保持过久的东西都是不好的。这里的问题不仅仅是互斥锁和解锁中额外递归逻辑的直线性能影响,而是对整个应用程序并发性的更大、更广泛、更难以描述的影响。
— David Butenhof on comp.programming.threads
锁有时候很有用,但是需要少用,而不是作为不良软件设计的借口。在for循环中使用锁,是低级结构,对于实现并发编程的高级抽象很有用,但不应该在正常的代码中出现太多。
阿姆达尔定律4:
假设原来在一个系统中执行一个程序需要时间����,其中某一个部分占的时间百分比为�,然后,把这一部分的性能提升�倍。即这一部分原来需要的时间为�����,现在需要的时间变为(�����/�)。则整个系统执行此程序需要的时间变为:�=1(1−�)+�/�

解决问题的办法一个就是不使用并发,另外一个就是不使用改变的数据。而第三个办法就是使用改变数据但是不共享。
你有四个选择:拥有不可变的数据而不共享,拥有可变的数据而不共享,拥有不可变的数据而共享,以及拥有可变的数据而共享。只有最后一种情况才会有问题。
5.5 变为常量的重要性
C++有两种办法限制改变:const和constexpr关键字
const std::string name{"John Smith"};
std::string name_copy = name; // 拷贝
std::string &name_ref = name; // 可改变引用,错误
const std::string &name_constref = name; // 不可改变引用
std::string *name_ptr = &name; // 可改变指针,错误
const std::string *name_constptr = &name; // 不可改变指针
const指针和const引用对象只能调用对象的const方法
class person_t
{
public:
std::string name() { return m_name; }
std::string name_const() const { return m_name; }
private:
std::string m_name;
};
person_t person;
const auto &p = person;
std::string name = p.name(); // 错误
std::string name = p.name_const(); // 正确
5.5.1 逻辑和内部常数
创建不可改变的C++类的最简单方法就是声明所有成员变量为常量
class person_t
{
public:
const std::string name;
const std::string surname;
...
};
或者使用getter函数封装
class person_t
{
public:
std::string name() const;
std::string surname() const;
private:
std::string m_name;
std::string m_surname;
...
};
使用mutable修饰成员变量使得const函数可以改变类成员变量
class person_t
{
public:
employment_history_t employment_history() const
{
std::uniqu_lock<std::mutex>
lock{m_employment_history_mutex};
if (!m_employment_history.loaded()) {
load_employment_history();
}
return m_employment_history;
}
};
5.5.2 优化临时成员函数
当你将类设计为不可变时,每当您想要创建setter成员函数时,你都需要创建一个函数,该函数返回一个对象的副本,在该副本中,特定的成员值被更改。
person_t new_person {
old_person.with_name("Jonne")
.with_surname("Jones);
};
with_name方法返回一个全新的person_t实例
实现:
class person_t
{
public:
person_t with_name(const std::string &name) const &
{
person_t result(*this);
result.m_name = name;
return result;
}
person_t with_name(const std::string &name) &&
{
person_t result(std::move(*this));
result.m_name = name;
return result;
}
};
在函数后面使用const &表示该函数只能用在const引用对象上,而&&代表该函数只能用在右值对象上
5.5.3 const的陷阱
你可能使用过多的const而掉进了陷阱
CONST禁止移动对象
person_t some_function()
{
person_t result;
// do something
return result;
}
...
person_t person = some_function();
如果编译器不进行优化,返回person_t时会创建一个新的实例给调用者。但是编译器会进行优化,称为命名返回值优化(named return value optimization, NRVO)
const函数会打破这一规则,返回const对象会导致副本
浅CONST
另一个问题是,CONST很容易被颠覆,例如
class company_t
{
public:
std::vector<std::string> employees_names() const;
private:
std::vector<person_t *> m_employees;
};
你不能通过employees_names修改员工名称,但是类中实际的m_employees是以指针的形式存在的,这意味着你不可以改变指针的值,但是指针指向的数据是可以修改的
propagate_const包装器
C++17之后的propagete_const可以解决这个问题,在<experimental/propagate_const>里面
6 懒惰评估
NOTE: lazy evaluation,计算表达式的评估(evaluation)也就是计算结果,lazy的意思可以参考lazy load(懒加载)
计算需要花费时间,当两个矩阵A和B相乘,只需要写
auto P = A * B;
问题就是你可能不需要该计算结果,而浪费了CPU时间
另外一种办法就是说有需要时,P应该被计算为A * B的结果。仅仅只是定义它,而不是立即做计算。当程序某个部分需要P的值,才来进行计算。不是在之前计算
可以通过lambda表达式来定义
auto P = [A, B] {
return A * B;
}
如果有人需要值,则可以调用P()
但是带来的问题就是如果不止一次需要求值呢?这样就会每次都进行计算,所以在计算后记住值就很重要
这就是懒惰的表现:你不提前做工作,而是尽可能地推迟工作。因为你很懒,你也想避免多次做同样的事情,所以在你得到结果后,你会记住它。
6.1 C++的懒惰
不幸的是不像其他语言一样,C++不支持懒惰评估,但是提供了一些工具可以仿真程序行为。
lazy_val模板
template<typename F>
class lazy_val
{
private:
F m_computation;
mutable bool m_cache_initialized;
mutable decltype(m_computation()) m_cache;
mutable std::mutex m_cache_mutex;
public:
lazy_val(F computation) :
m_computation(computation),
m_cache_initialization(false)
{}
// 也可以写成
// const decltype(m_computation()) &operator() const
operator const decltype(m_computation()) & () const
{
std::unique_lock<std::mutex> lock{m_cache_mutex};
if (!m_cache_initialized) {
m_cache = m_computation();
m_cache_initialized = true;
}
return m_cache;
}
};
template <typename F>
inline lazy_val<F> make_lazy_val(F &&computation)
{
return lazy_val<F>(std::forward<F>(computation));
}
该程序在多线程上还是次优的,只有在第一次计算时才需要加锁。也可以使用std::call_once来解决
template<typename F>
class lazy_val
{
private:
F m_computation;
mutable decltype(m_computation()) m_cache;
mutable std::once_flag m_value_flag;
public:
...
operator const decltype(m_computation()) & () const
{
std::call_once(m_value_flag, [this] {
m_cache = m_computation();
});
return m_cache;
}
};
6.2 懒惰作为优化技巧
6.2.1 懒惰的排序集合
假设你有一个存储在向量中的几百个雇员的集合。 你有一个窗口,可以一次显示10个雇员;用户可以选择根据各种标准对雇员进行排序,如姓名、年龄、为公司工作的年限等等。 当用户选择根据员工的年龄进行排序时,程序应该显示10名最年长的员工,并允许用户向下滚动以查看其余的排序列表。
你可以通过对整个集合进行排序并一次显示10名员工来轻松实现这一目标。尽管如果你希望用户对整个排序的列表感兴趣,这可能是一个很好的方法,但如果不是这样的话,这将是矫枉过正。用户可能只对前10个列表感兴趣,而每次排序的标准改变时,你都要对整个集合进行排序。
为了使其尽可能高效,你需要想出一种懒惰的方式来对集合进行排序。 你可以把这个算法建立在quicksort上,因为它是最常用的内存排序算法。
quicksort的基本变体所做的事情很简单:它从集合中抽取一个元素,将所有大于该元素的元素移到集合的开头,然后将其余的元素移到集合的结尾(你甚至可以使用std::partition来完成这个步骤)。 然后对两个新创建的分区重复这一步骤。
为了使算法变得懒惰–只对集合中需要显示给用户的部分进行排序,而对其余部分不进行排序,你应该怎么改?你不能避免做分区步骤,但你可以推迟对你不需要排序的部分集合的递归调用。
你只有在需要时才会对元素进行排序。 这样,你就避免了对数组中不需要排序的部分进行算法的递归调用。
懒惰快速排序的复杂度
因为C++标准规定了它所定义的所有算法的所需复杂度,有人可能对你刚才定义的懒惰quicksort算法的复杂度感兴趣。让集合的大小为n,并假设你想得到前k项。
对于第一个分区步骤,你需要O(n)个操作;对于第二个,O(n/2);以此类推,直到达到你需要完全排序的分区大小。总的来说,对于分区,你在普通情况下有O(2n),这与O(n)相同。
为了对大小为k的分区进行完全排序,你需要O(k log k)次操作,因为你需要执行常规的quicksort。因此,总的复杂度将是O(n + k log k),这相当不错:这意味着如果你要搜索集合中的最大元素,你将和std::max_element算法处于同一水平。O(n)。而如果你要对整个集合进行排序,那将是O(n log n),就像普通的quicksort算法。
6.2.2 用户界面中的项目视图
虽然前面的例子的重点是展示如何修改一个特定的算法,使其更加懒惰,但你需要懒惰的原因是很常见的。每当你有大量的数据,但在有限的屏幕空间内向用户展示这些数据时,你就有机会通过偷懒来进行优化。一个常见的情况是,你的数据存储在某个数据库中,而你需要以这样或那样的方式向用户展示它。
为了重用上一个例子的想法,设想你有一个包含员工数据的数据库。当显示员工时,你想把他们的名字和他们的照片一起显示出来。在前面的例子中,你需要懒惰的原因是,当你需要一次只显示10个项目时,对整个集合进行排序是多余的。
现在你有一个数据库,它要为你做排序。这是否意味着你应该一次性加载所有的东西?当然不是。你没有做排序,但是数据库在做–就像懒惰排序一样,数据库倾向于在请求时对数据进行排序。如果你一次得到所有的员工,数据库将不得不对所有的员工进行排序。 但排序并不是唯一的问题。在你这边,你需要显示每个员工的图片–而加载图片需要时间和内存。如果你一次装入所有的东西,你会使你的程序慢下来,并使用太多的内存。
相反,常见的方法是懒散地加载数据–只有在需要向用户展示时才加载。这样一来,你就可以使用更少的处理器时间和更少的内存。唯一的问题是,你不可能完全偷懒。你将无法保存所有先前加载的员工照片,因为这样做又会需要太多的内存。你需要开始忘记以前加载的数据,并在再次需要它时重新加载它。
6.2.3 通过缓存函数结果来修剪递归树
C++可以根据需要自定义懒惰程度
计算斐波那契数
unsigned int fib(unsigned int n)
{
return n == 0 ? 0 :
n == 1 ? 1 :
fib(n - 1) + fib(n - 2);
}
该实现方式效率很低,有两个循环调用,重复了计算
// 使用缓存方式
std::vector<unsigned int> cache{0, 1};
unsigned int fib(unsigned int n)
{
if (cache.size() > n) {
return cache[n];
} else {
const auto result = fib(n - 1) + fib(n - 2);
cache.push_back(result);
return result;
}
}
这种方法的好处就是不需要发明新的算法计算,因为fib函数是纯的,你甚至不需要知道其计算原理
计算斐波那契数列的高效缓存
// 如果不考虑多次计算,甚至只需要记录前两次的结果就可以实现了
class fib_cache
{
public:
fib_cache() :
m_previous{0},
m_last{1},
m_size{2}
{}
size_t size() const
{
return m_size;
}
unsigned int operator[](unsigned int n) const
{
return n == m_size - 1 ? m_last :
n == m_size - 2 ? m_previous :
0;
}
void push_back(unsigned int value)
{
m_size++;
m_previous = m_last;
m_last = value;
}
private:
int m_previous;
int m_last;
size_t m_size;
};
6.2.4 动态编程是一种懒惰的形式
动态编程(Dynamic programming)是一种通过将复杂的问题分割成许多小问题来解决的技术。当你解决这些较小的问题时,你存储它们的解决方案,这样你就可以在以后重新使用它们。这种技术被用于许多现实世界的算法中,包括寻找最短路径和计算字符串距离。
在某种意义上,你为计算第n个斐波那契数的函数所做的优化也是基于动态编程的。你有一个问题fib(n),你把它分成两个小问题:fib(n - 1)和fib(n - 2)。(这对斐波那契数的定义很有帮助。)通过存储所有小问题的结果,你大大优化了初始算法。
虽然这是对fib函数的明显优化,但情况并非总是如此。让我们考虑计算两个字符串之间的相似性问题。其中一个可能的衡量标准是列文斯坦距离(Levenshtein)1(或编辑距离),它是将一个字符串转化为另一个字符串所需的最小的删除、插入和替换的数量。比如说:
- example和example——距离为0,字符串相同
- example和exam——距离为3,需要删除3个字符
- exam和eram——距离为1,需要把x换成r
递归的计算列文斯坦距离
unsigned int lev(unsigned int m, unsigned int n)
{
return m == 0 ? n :
n == 0 ? m :
std::min({
lev(m - 1, n) + 1,
lev(m, n - 1) + 1,
lev(m - 1, n - 1) + (a[m - 1] != b[n - 1])
});
}
6.3 通用的记忆化
记忆化缓存
虽然通常为每个问题单独编写自定义缓存更好,这样你可以控制一个特定的值在缓存中停留多长时间(就像fib(n)的备忘录化版本的forgetful cache那样),并确定保持缓存的最佳结构(例如,对lev(m, n)使用矩阵),但有时能够将一个函数放入一个包装器并自动得到该函数的记忆化版本是很有用的。
template <typename Result, typename ... Args>
auto make_memoized(Result (*f) (Args ...))
{
// 创建一个缓存,将参数通过map映射到计算结果上。
// 如果你想在多线程环境中使用它,你需要用一个mutex来同步它的变化。
std::map<std::tuple<Args...>, Result> cache;
return [f, cache] (Args... args) mutable -> result
{
// 判断结果是否已经缓存
const auto args_tuple =
std::make_tuple(args...);
const auto cached = cache.find(args_tuple);
if (cached == cache.end()) {
// 没有缓存就计算结果缓存
auto result = f(args...);
cache[args_tuple] = result;
return result;
} else {
// 有缓存直接返回缓存结果
return cached->second;
}
}
}
简单来讲就是牺牲空间换取时间
记忆化后的fib函数版本使用
auto fibmemo = make_memoized(fib);
std::cout << "fib(15) = " << fibmemo(15)
<< std::endl;
std::cout << "fib(15) = " << fibmemo(15)
<< std::endl;
这个版本只会第二次执行得到优化,原因是fib函数里面没有调用缓存的版本
template <typename F>
unsigned int fib(F &&fibmemo, unsigned int n)
{
return n == 0 ? 0
: n == 1 ? 1
: fibmemo(n - 1) + fibmemo(n - 2);
}
记忆化封装
class null_param {};
template <class Sig, class F>
class memoize_helper;
template <class Result, class... Args, class F>
class memoize_helper<Result (Args...), F>
{
private:
using function_type = F;
using args_tuple_type
= std::tuple<std::decay_t<Args>...>;
function_type f;
mutable std::map<args_tuple_type, Result> m_cache;
mutable std::recursive_mutex m_cache_mutex;
public:
template <typename Function>
memoize_helper(Function &&f, null_param) :
f(f)
{}
memoize_helper(const memoize_helper &other) :
f(other.f)
{}
template <class... InnerArgs>
Result operator()(InnerArgs &&... args) const
{
std::unique_lock<std::recursive_mutex>
lock{m_cache_mutex};
const auto args_tuple =
std::make_tuple(args...);
const auto cached = m_cache.find(args_tuple);
if (cached != m_cache.end()) {
return cached->second;
} else {
auto &&result = f(
*this,
std::forward<InnerArgs>(args)...);
m_cache[args_tuple] = result;
return result;
}
}
};
template <class Sig, class F>
memoize_helper<Sig, std::decay_t<F>>
make_memoized_r(F &&f)
{
return {std::forward<F>(F), detail::null_param()};
}
// 创建
auto fibmemo = make_memoized_r<
unsigned int(unsigned int)>(
[](auto &fib, unsigned int n) {
std::cout << "calculating " << n << "!\n";
return n == 0 ? 0
: n == 1 ? 1
: fib(n - 1) + fib(n - 2);
});
6.4 表达式模板和惰性字符串连接
一般字符串连接的实现方式
std::string fullname = title + " " + surname + ", " + name;
根据加法的左关联原则,可以看作
std::string fullname = (((title + " ") + surname) + ", ") + name;
该过程会创建销毁不需要的缓冲区域做临时计算
template <typename ...Strings>
class lazy_string_concat_helper;
template <typename LastString, typename ...Strings>
class lazy_string_concat_helper<LastString,
Strings...>
{
private:
// 存储原来字符串的拷贝
LastString data;
lazy_string_concat_helper<Strings...> tail;
public:
lazy_string_concat_helper(
LastString data,
lazy_string_concat_helper<Strings...> tail) :
data(data),
tail(tail)
{}
int size() const
{
return data.size() + tail.size();
}
template <typename It>
void save(It end) const
{
const auto begin = end - data.size();
std::copy(data.cbegin(), data.cend(),
begin);
tail.save(begin);
}
operator std::string() const
{
std::string result(size(), '\0');
save(result.end());
return result;
}
lazy_string_concat_helper<std::string,
LastString,
Strings...>
operator+(const std::string &other) const
{
return lazy_string_concat_helper
<std::string, LastString, Strings...>(
other,
*this
);
}
};
// 由于这个是递归的实现,为了避免无限循环迭代,还需要一个基础版本
tempalte <>
class lazy_string_concat_helper<>
{
public:
lazy_string_concat_helper() {}
int size() const
{
return 0;
}
template <typename It>
void save(It) const {}
lazy_string_concat_helper<std::string>
operator+(const std::string &other) const
{
return lazy_string_concat_helper<std::string>(
other,
*this
);
}
};
使用
lazy_string_concat_helper<> lazy_concat;
int main(int argc, char *argv[])
{
std::string name = "Jane";
std::string surname = "Smith"
const std::string fullname =
lazy_concat + surname + ", " + name;
std::cout << (std::string)fullname << std::endl;
}
6.4.1 纯净和表达式模板
如果用引用存储,在真正获取到值之前对原来数据的修改都会生效
template <typename LastString, typename ...Strings>
class lazy_string_concat_helper<LastString,
Strings...>
{
private:
// 存储原来字符串的拷贝
const LastString &data;
lazy_string_concat_helper<Strings...> tail;
public:
lazy_string_concat_helper(
const LastString& data,
lazy_string_concat_helper<Strings...> tail) :
data(data),
tail(tail)
{}
...
};
// 未知原因段错误
int main()
{
std::string name = "Jane";
std::string surname = "Smith";
const auto fullname =
lazy_concat + surname + std::string(", ") + name;
name = "John";
std::cout << "begin print" << std::endl;
std::cout << (std::string)fullname << std::endl;
}
7 范围
Ranges
根据人的归属划分组
template <typename Persons, typename F>
void group_by_team(Person &person,
F team_for_person,
const std::vector<std::string> &teams)
{
auto begin = std::begin(persons);
const auto end = std::end(persons);
for (const auto &team : teams) {
begin = std::partition(begin, end,
[&] (const auto &person) {
return team == team_for_person(person);
});
}
}
主要的问题是,STL算法将一个集合的开头和结尾的迭代器作为单独的参数,而不是采取集合本身。这有一些影响:
- 这些算法不能作为结果返回一个集合。
- 即使你有一个返回集合的函数,你也不能直接把它传递给算法:你需要创建一个临时变量,这样你就可以对它调用开始和结束。
- 由于前面的原因,大多数算法都会对其参数进行变异,而不是让它们保持不可变,只是将修改后的集合作为结果返回。
这些因素使得在不具备至少是局部可改变变量的情况下,很难实现程序逻辑。
7.1 引入ranges
之前章节的一段代码
std::vector<std::string> names =
transform(
filter(people, is_female),
name
);
使用类似UNIX的管道语法规则,可以让代码更简洁
std::vector<std::string> names = people | filter(is_female)
| transform(name);
7.2 创建只读的数据视图
过滤代理迭代器的增加操作符
auto &operator++()
{
++m_current_position;
m_current_position =
std::find_if(m_current_position,
m_end,
m_predicate);
return *this;
}
7.2.2 ranges的transform函数
转换代理迭代器的解引用运算操作
auto operator*() const
{
return m_function(
*m_current_position
);
}
名字直接通过m_function解出来了
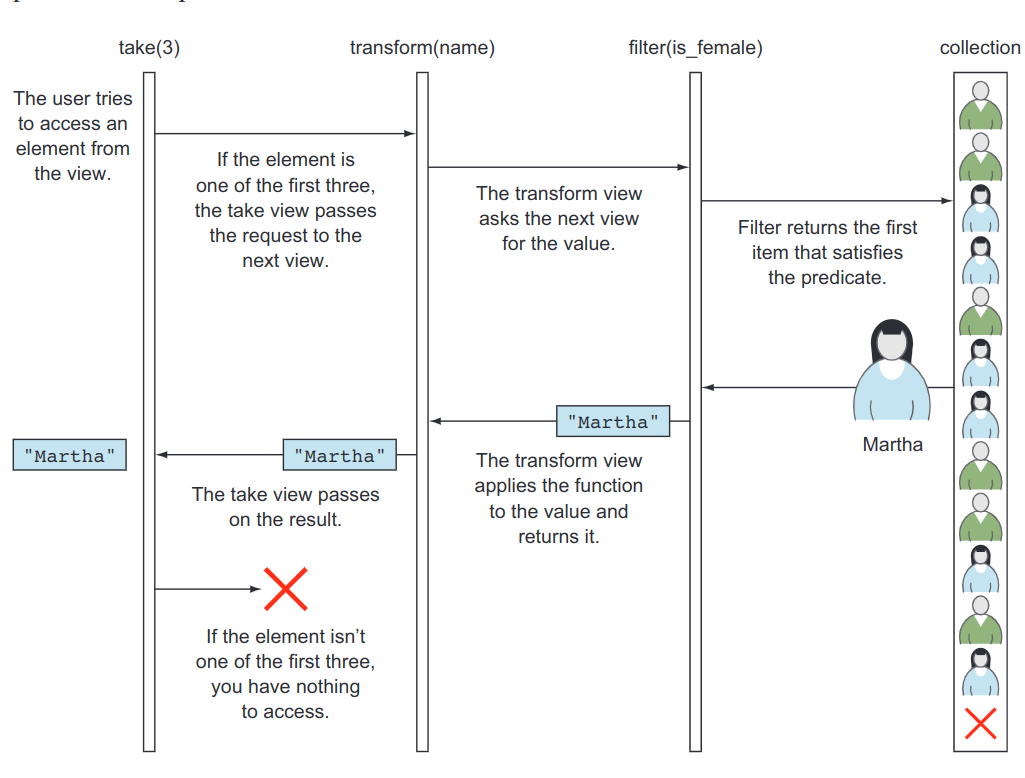
7.2.4 range值的懒惰估计
evaluation,解算,估计
例子
std::vector<std::string> names = people | filter(is_female)
| transform(name)
| take(3);
分析:
- 当
people | filter(is_female)估计,创建了一个新的view,没有从集合里面取得单一的person - 把视图传给
| transform(name),创建了一个新的视图,仍然没有从里面取元素或者调用name函数 - 应用
| take(3),同样只是创建了一个新的视图 - 从
| take(3)的结果构造字符串向量,进行计算
当构造向量时,进行了以下操作:
- 调用代理迭代器上面的解引用操作符,迭代器为
take返回的范围 take创建的代理迭代器将请求传递给transform创建的代理迭代器。该迭代器传递请求- 试图解除对过滤器转换所定义的代理迭代器的引用。它穿过源集合,找到并返回第一个满足
is_female谓词的人。这个是你第一次访问集合中的任何一个人,也是第一次调用is_female函数 - 通过解除引用过滤器代理迭代器检索到的人被传递
name函数,结果被返回给take迭代器,后者将其名字传递到名字向量中插入
当插入一个元素后,下一个,然后再下一个,直到到达最后
7.3 ranges里面的可变值
前面的例子是不改变原集合,有些时候需要改变初始集合。我们把这些变换称为动作(actions),和视图(views)相对
动作转换的一个常见例子是排序。为了能够对一个集合进行排序,你需要访问它的所有元素并对它们重新排序。你需要改变原始集合,或者创建并保留整个集合的排序副本。当原始集合不是随机访问的(例如一个链表),并且不能有效地进行排序时,后者尤其重要;你需要把它的元素复制到一个可以随机访问的新集合中,并对它进行排序。
统计所有出现过单词的集合
需要用到
range-v3库,在https://github.com/ericniebler/range-v3
给字符串排序去重复的例子
std::vector<std::string> words =
read_text() | action::sort
| action::unique;
视图和动作的这种组合使你有能力选择什么时候你想懒惰地完成某件事,什么时候你想急切地完成某件事。有这种选择的好处是,当你不期望源集合中的所有项目都需要处理时,以及当项目不需要被处理超过一次时,你可以偷懒;如果你知道结果集合中的所有元素会被经常访问,你可以急于计算它们。
7.4 使用划定的和无限的ranges
划定的(delimited),无限的(infinite)
通常的测试是否到末尾的方法
auto i = std::begin(collection);
const auto end = std::end(collection);
for (; i != end; ++i) {
// ...
}
并不需要迭代器,而是需要测试是否到末尾,这个特殊值叫做哨兵(sentinel)。可以更自由的测试是否到range的末尾
7.4.1 使用划定的ranges优化处理输入ranges
一个划定的ranges是一个你事先不知道终点的范围,但你有一个谓词函数可以告诉你什么时候到达终点。比如字符串,根据\0来判断是否结束
还有比如用迭代器获取输入
std::accumulate(std::istream_iterator<double>(std::cin),
std::istream_iterator<double>(),
0);
该方法会一直接受
double类型的输入,直到输入的类型不再为double
迭代器std::istream_iterator实现哨兵值的方式例如:
template<typename T>
bool operator==(const std::istream_iterator<T> &left,
const std::istream_iterator<T> &right)
{
if (left.is_sentinel() && right.is_sentinel()) { return true; }
else if (left.is_sentinel()) {
// 测试是否为哨兵谓词
// 对于右边的迭代器为真
} else if (right.is_sentinel()) {
// 测试是否为哨兵谓词
// 对于左边的迭代器
} else {
// 两个迭代器都为正常迭代器,
// 测试两个是否指向相同的位置
}
}
7.4.2 使用sentinels创建无限的ranges
sentinels方法为你提供了限定ranges的优化。但还有一点:你现在也能轻松地创建无限的ranges了。 无限ranges没有终点,就像所有正整数的范围。你有一个开始———数字0,但没有结束。
虽然你为什么需要无限的数据结构并不明显,但它们时常会派上用场。使用整数范围的一个最常见的例子是枚举另一个范围内的项目。 想象一下,你有一个按分数排序的电影范围,你想把前10部电影和它们的位置写到标准输出。
要做到这一点,你可以使用view::zip函数。它需要两个范围,并将这些范围中的项目配对。结果范围中的第一个元素将是一对项目:第一个范围的第一个项目和第二个范围的第一个项目。第二个元素将是一对,包含第一个范围的第二个项目和第二个范围的第二个项目,以此类推。一旦任何一个源范围结束,产生的范围就会结束。
template <typename Range>
void write_top_10(const Range &xs)
{
auto items =
view::zip(xs, view::ints(1))
| view::transform([] (const auto &pair) {
return std::to_string(pair.second) + " " + pair.first;
})
| view::take(10);
for (const auto &item : items) {
std::cout << item << std::endl;
}
}
当你在便利一个ranges但是只有在遍历的时候才知道有多长。你如果要根据长度遍历可能要遍历两次,第一次为了view::zip,第二次为了view::transform处理。
这样的另一个好处就是代码更加通用,算法支持在无限ranges情况下工作
7.5 使用ranges计算词频
range-v3库里面有istream_range可以把std::cin的输入转成ranges ,标准库里面有std::ranges::istream_view
首先需要对输入字符串进行预处理,然后再进行筛选
std::string string_to_lower(const std::string &s)
{
return s | view::transform(tolower);
}
std::string string_only_alnum(const std::string &s)
{
return s | view::filter(isalnum);
}
std::vector<std::string> words =
istream_range<std::string>(std::cin)
| view::transform(string_to_lower)
| view::transform(string_only_alnum)
| view::remove_if(&std::string::empty); // 类成员函数指针
const auto results =
words | view::group_by(std::equal_to<>())
| view::transform([] (cosnt auto &group) {
const auto begin = std::begin(group);
const auto end = std::end(group);
const auto count = std::distance(begin, end);
const auto word = *begin;
return std::make_pair(count, word);
})
| to_vector | action::sort; //转成vector排序
这段代码怎么都编译不过!!
8 函数式数据结构
到目前为止,我主要谈的是更高层次的函数式编程概念,我们花了相当长的时间来研究没有可改变状态的编程的好处。问题是,程序往往有许多移动部件。在第五章讨论纯粹性的时候,我说过,其中一个选择是只让主要组件拥有可变的状态。所有其他组件都是纯粹的,并计算出一系列应该在主组件上执行的变化,但实际上并不改变任何东西。然后主组件可以对自己执行这些变化。
这种方法在程序的纯粹部分和处理可变状态的部分之间建立了明确的分离。问题是,设计这样的软件往往不容易,因为你需要注意功能数据结构计算出的状态变化的应用顺序。如果你没有正确地做到这一点,你可能会遇到类似于在并发环境中处理易变状态时的数据竞赛。
因此,有时有必要避免所有的可变–甚至没有中央可变的状态。如果你使用标准的数据结构,每当你需要一个新版本的数据时,你就必须复制这些数据。 每当你想改变一个集合中的一个元素时,你就需要创建一个新的集合,这个集合与旧的集合相同,但所需的元素已经改变。在使用标准库提供的数据结构时,这样做效率很低。在这一章中,我们将介绍那些可以有效复制的数据结构。创建一个数据结构的修改副本也将是一个高效的操作。
8.1 不可改变的链表
使用共享指针管理链表内部元素,然后链表的修改可以根据修改的位置减少总体的复制量
8.2 不可改变的vector-like数据
(Copy-on-write), lazy copy
并不是每次都进行复制,而是对之前的数据进行切片记录到新的数据里面,直到最后需要进行转换写入才把真正的数据计算出来
9 代数数据类型和模式匹配
需要解决的一个问题,覆盖非预期或者无效状态
假设对网页上文字计数,步骤分为
- 初始状态,还没开始计数
- 计数状态,接受网页,计数
- 最终状态,完全接收完毕,计数完毕
你可能需要以下数据结构
struct state_t {
bool started = false;
bool finished = false;
unsigned count = 0;
socket_t web_page;
};
9.1 代数数据类型
函数式编程世界里,从老的类型构建新的类型通常通过两种方式:求和(sum)和乘积(product)(因此,这些新的类型被称为代数性的)。A和B类型的乘积是一个包含A和B的类型(它将是A类所有值的集合与B类所有值的集合的笛卡尔乘积)。比如状态是两个bool类型和unsigned类型和socket_t类型的乘积。多个的类似。
当我们希望组合多种类型为一种,可以创建新的类或者使用std::pair或者std::tuple当我们不需要成员值被命名
bool operator<(const person_t& left, const person_t& right)
{
return std::tie(left.m_surname, left.m_name) <
std::tie(right.m_surname, right.m_name);
}
这段代码会先比较m_surname,再比较m_name
由于std::pair和std::tuple里面的成员名称并不确定,所以要少用或者限定适用范围只在本地,而不是把接口暴露给别人使用
枚举是一种特殊的总和类型。你通过指定它可以持有的不同值来定义一个枚举。该枚举类型的一个实例可以精确地持有这些值中的一个。如果你把这些值当作一个元素的集合,那么枚举就是这些集合的和类型。
9.1.1 通过继承对类型归总(sum)
父类
class state_t
{
protected:
state_t(int type) :
type(type)
{}
public:
virtual ~state_t() {}
int type;
};
表示不同状态的类型
class init_t : public state_t
{
public:
enum { id = 0 };
init_t() :
state_t(id)
{}
};
class running_t : public state_t
{
public:
enum { id = 1 };
running_t() :
state_t(id)
{}
unsigned count() const
{
return m_count;
}
private:
unsigned m_count = 0;
socket_t m_web_pages;
};
class finished_t : public state_t
{
public:
enum { id = 2 };
finished_t(unsigned count) :
state_t(id),
m_count(count)
{}
unsigned count() const
{
return m_count;
}
// ...
private:
unsigned m_count;
};
主程序需要一个指针指向state_t,通常的做法是用unique_ptr
主程序代码
class program_t
{
public:
program_t() :
m_state(std::make_unique<init_t>())
{}
// ... 其他代码
void counting_finished()
{
assert(m_state->type == running_t::id);
auto state = static_cast<running_t*>(m_state.get());
m_state = std::make_unique<finished_t>(state->count());
}
private:
std::unique_ptr<state_t> m_state;
};
使用这种方法,您不再具有无效状态。如果尚未开始计数,则计数不能大于零(在这种情况下,计数甚至不存在)。计数过程结束后,计数不会意外更改,您可以准确地知道程序始终处于哪个状态。通过状态限制了数据的生命周期
此外,您不需要关注为特定状态获取的资源的生命周期。关注web_page。在将所有需要的变量放入state_t结构的原始方法中,您可能会忘记在读取完套接字后关闭它。只要state_t的实例存在,套接字实例就会继续存在。通过使用sum类型,当您切换到另一个状态时,特定状态所需的所有资源将自动释放。在这种情况下,running_t的析构函数将关闭web_page的套接字。
当你使用继承来实现和类型时,你会得到开放的和类型。状态可以是任何继承自state_t的类,这使得它很容易被扩展。 虽然这有时很有用,但你通常知道程序应该有哪些可能的状态,你不需要允许其他组件动态地扩展状态集。
继承的方法也有一些缺点。如果你想保持它的开放性,你需要使用虚拟函数和动态调度(至少对于析构器),你必须使用类型标签(程序里面的type)以避免依赖缓慢的dynamic_cast,而且你必须在堆上动态地分配状态对象。你还需要注意不要让m_state指针失效(nullptr)。
9.1.2 通过std::variant对类型归总(sum)
状态代码去掉继承关系
class init_t
{
public:
init_t()
{}
};
class running_t
{
public:
running_t()
{}
unsigned count() const
{
return m_count;
}
private:
unsigned m_count = 0;
socket_t m_web_pages;
};
class finished_t
{
public:
finished_t(unsigned count) :
m_count(count)
{}
unsigned count() const
{
return m_count;
}
// ...
private:
unsigned m_count;
};
主程序代码
class program_t
{
public:
program_t() :
m_state(init_t())
{}
// ...
void counting_finished()
{
auto *state = std::get_if<running_t>(&m_state);
assert(state != nullptr);
m_state = finished_t(state->count());
}
private:
std::variant<init_t, running_t, state_t> m_state;
};
与第一个解决方案相比,std::variant的好处很多。 它几乎不需要模板,因为类型标记是由std::variant处理的。你也不需要创建一个继承层次,其中所有被求和的类型都必须继承自一个超类型;你可以求和现有的类型,如字符串和向量。另外,std::variant不执行任何动态内存分配。变体实例将像普通的联合体一样,拥有你想要存储的最大类型的大小(加上几个字节用于簿记)。
可以参考FlatBuffer里面的Union类型,void*指针加上类型枚举
std::any类是基于继承的开放总和类型的一个替代方案。 它是一个类型安全的容器,用于存放任何类型的值。 尽管它在某些情况下很有用,但它并不像std::variant那样有效,而且不应该被用作std::variant的简单到类型的替代。
9.1.3 实现特定状态
有了program_t后可以实现具体逻辑,但是具体在什么地方
最佳的办法是在状态里面实现,而不是放在program_t中每次需要判断当前状态然后执行不同的代码,例如
class running_t
{
public:
running_t(const std::string &url) :
m_web_page(url)
{}
void count_words()
{
m_count = std::distance(
std::istream_iterator<std::string>(m_web_page),
std::istream_iterator<std::string>());
}
unsigned count() const
{
return m_count;
}
private:
unsigned m_count = 0;
std::istream m_web_page;
};
把逻辑放在program_t类之外,把所有的东西放在状态类中。这种方法消除了使用get_if和index检查的需要,因为只有当你处于某个特定状态时,代表该状态的类的成员函数才会被调用。缺点是现在的状态类需要按程序状态的变化,这意味着它们需要互相了解,从而破坏了封装。
9.1.4 特殊归总类型:Optional值
实现为空或者有值
struct nothing_t{};
template<T>
using optional = std::variant<nothing_t, T>;
std::optional是比std::variant更特定化的归总类型
9.1.5 用于错误处理的归总类型
如果需要追踪错误,可以创建一种值,要么包含值要么包含错误在里面
// 本代码可以通过编译测试
#include <exception>
#include <stdexcept>
#include <vector>
#include <optional>
#include <variant>
#include <iostream>
template<typename T, typename E>
class expected
{
private:
union
{
T m_value;
E m_error;
};
bool m_valid;
// 默认构造, 只能自己调用
explicit expected(bool valid = false) : m_valid(valid)
{
}
public:
// 拷贝构造
expected(const expected &other) :
m_valid(other.m_valid)
{
if (m_valid) {
// 拷贝new构造
new(&m_value) T(other.m_value);
} else {
new(&m_error) E(other.m_error);
}
}
// 移动构造
expected(expected &&other) noexcept:
m_valid(other.m_valid)
{
if (m_valid) {
// 移动new构造
new(&m_value) T(std::move(other.m_value));
} else {
new(&m_error) E(std::move(other.m_error));
}
}
// 联合体必须指定析构类型
~expected()
{
if (m_valid) {
m_value.~T();
} else {
m_error.~E();
}
};
// 为了std::swap调用,实现swappable
void swap(expected &other)
{
if (m_valid) {
if (other.m_valid) {
// 都有效,交换值
std::swap(m_value, other.m_value);
} else {
// 当前有效,交换对象无效的情况
auto temp = std::move(other.m_error);
other.m_error.~E();
new(&other.m_value) T(std::move(m_value));
m_value.~T();
new(&m_error) E(std::move(temp));
std::swap(m_valid, other.m_valid);
}
} else {
if (other.m_valid) {
// 另一个有效,另一个调用交换函数
if (other.m_valid) {
other.swap(*this);
} else {
// 都无效,交换错误
std::swap(m_error, other.m_error);
}
}
}
}
// 转换为bool类型操作符,用于条件判断
explicit operator bool() const
{
return m_valid;
}
// 转换成为optional操作符,比如std::optional(...)
explicit operator std::optional<T>() const
{
if (m_valid) {
return m_value;
} else {
return std::nullopt;
}
}
T &get()
{
if (!m_valid) {
throw std::logic_error("Missing a value");
}
return m_value;
}
E &error()
{
if (m_valid) {
throw std::logic_error("There is no error");
}
return m_error;
}
template<typename ...Args>
static expected success(Args &&...params)
{
expected result;
result.m_valid = true;
new(&result.m_value)
T(std::forward<Args>(params)...);
return result;
}
template<typename ...Args>
static expected failed(Args &&...params)
{
expected result;
result.m_valid = false;
new(&result.m_value)
E(std::forward<Args>(params)...);
return result;
}
};
// 实现get_if函数
template<typename T, typename Variant,
typename Expected = expected<T, std::string>>
Expected get_if(const Variant &variant)
{
const T *ptr = std::get_if<T>(variant);
if (ptr) { return Expected::success(*ptr); }
else {
return Expected::failed("Variant doesn't contain the desired type");
}
}
template<typename ...Args>
void print_result(const std::string &name, expected<Args...> &v)
{
if (v) {
std::cout << name << " succeed" << std::endl;
std::cout << "val: " << v.get() << std::endl;
} else {
std::cout << name << " error" << std::endl;
std::cout << "err: " << v.error() << std::endl;
}
};
int main()
{
auto result = expected<double, std::string>::success(1.0);
print_result("result", result);
auto result1 = expected<double, std::string>::failed("error occurred");
print_result("result1", result1);
auto op_result = std::optional(result1);
std::variant<int, double> a{1};
auto get_result = ::get_if<double>(&a);
print_result("get_result", get_result);
}
现在,如果你的函数可能会失败,则可以在返回结果时调用成功或错误。
其中new的用法参考:
9.2 使用代数数据类型建模
在设计数据类型时,主要的想法是使非法状态不可能被表达出来。这就是为什么std::vector的size成员函数会返回一个无符号的值(即使有些人不喜欢无符号类型1)——这样的类型加强了你的直觉,即大小不能是负的,也是为什么像std::reduce这样的算法(我们在第2章中谈到过)要用适当的类型来表示执行策略,而不是用普通的整数标志。
对于你创建的类型和函数,你也应该这样做。与其考虑你需要哪些数据来覆盖你的程序可能处于的所有状态,并将它们放在一个类中,不如考虑如何定义数据以覆盖你的程序可能处于的状态。
我们使用一个新的设想:Tennis kata,来证明这个。他的目的是要实现一个简单的网球比赛。在tennis中,两名球员(假设不存在双打)互相比赛。每当一个球员不能把球送回对方的球场时,该球员就失去了球,分数也会被更新。
网球的计分系统很独特,但很简单:
- 可能的分数为0、15、30和40
- 如果球员有40分并且赢球了,他们赢下比赛
- 如果双方都是40,规则就有点不同了:这时游戏就进入了两点(deuce)。
- 当处于平分时,赢得球的一方拥有优势(advantage)。
- 如果选手在有优势的情况下赢得了球,他们就赢得了比赛。如果选手输掉了球,比赛就回到了两点。
在本节中,我们将检查网球比赛的程序状态的几种实现。我们将讨论每一种的问题,直到我们达成一个解决方案,使实现没有无效的状态。
9.2.1 简单的方法,以及它的不足之处
class tennis_t
{
int player_1_points;
int player_2_points;
};
这样覆盖率所有的可能状态,但是问题是允许分数为无效的数字,考虑采用枚举的方式替代整数
class tennis_t
{
enum class points
{
love, // 零分
fifteen,
thirty,
forty,
};
points player_1_points;
points player_2_points;
};
降低了程序状态的数字,但是也存在问题。首先它允许两个运动员的分数都为40(是不允许的,该状态有特殊名字),然后没办法通过枚举表述优势(advantage)和两点(deuce)。但是会产生新的无效状态(一个为两分,一个为零分)
9.2.2 一个更复杂的方法:自上而下的设计
比赛分为两种主要状态:分数为数字的,还有就是在两点或优势状态。正常状态计分保持两个玩家的分数。然而事情并不简单。如果使用之前定义的points枚举,你会有两个玩家都有40分的可能性,但是这不允许,应该被报告为两分状态。
去掉forty状态,用正常分数和40分数表示
class tennis_t
{
enum class points
{
love,
fifteen,
thirty,
};
enum class player
{
player_1,
player_2,
};
// 普通积分状态
struct normal_scoring
{
points player_1_points;
points player_2_points;
};
// 40分状态
struct forty_scoring
{
player leading_player;
points other_player_scores;
};
// 两点状态
struct deuce {};
// 一方优势状态
struct advantage
{
player player_with_advantage;
};
// 定义归总类型
std::variant
<normal_scoring,
forty_scoring,
deuce,
advantage
> m_state;
};
{% note NOTE %} 有一个状态是可能缺失的:游戏结束状态,它应该表示哪个玩家获胜。如果你想打印出赢家并终止程序,你不需要添加这个状态。但如果你想让程序继续运行,你也需要实现这个状态。这很容易做到;你只需要创建另一个结构,用一个成员变量来存储赢家,并扩展m_state的变量。 {% endnote %}
通常也不需要做这么多去移除无效状态(你可能决定手动解决40-40的情况),但是这种建模方式把不同的状态分割成独立子部件,分别描述
9.3 用模式匹配更好地处理代数数据类型
在实现带有optional值、varant和其他代数数据类型的程序时,主要的问题是,每次你需要一个值时,你都必须检查它是否存在,然后从它的包装类型中提取。 即使你创建了没有和类型的状态类,你也需要同等的检查,但只是在你设置值的时候,而不是每次你想访问它们的时候。
因为这个过程可能很繁琐,所以许多函数式编程语言提供了一种特殊的语法,使之更容易。通常情况下,这种语法看起来像switch-case语句,不仅可以与特定的值相匹配,还可以与类型和更复杂的模式相匹配:
switch (state) {
case normal_score_state:
...
break;
case forty_scoring_state:
...
break;
...
};
但是糟糕的是这种代码只能在state是整型的情况下运作。
参考 [访问者模式]({% post_path ‘设计模式笔记’ %}#visitor)
现在想象一个世界,这个代码也可以测试字符串,并且可以与variant一起工作,根据变体variant中的变量类型执行不同的情况。如果每个案例都是类型检查、值检查和你可以定义的自定义谓词的组合呢?这就是大多数函数式编程语言中模式匹配的样子。
C++提供了为模板元编程做模式匹配的方法,但是对于普通程序来说我们需要另外的办法。标准库提供了std::visit函数获取std::variant和对应里面存储的值执行的函数。例如,打印函数可以这么写:
std::visit([] (const auto &value) {
std::cout << value << std::endl;
},
m_state);
使用std::visit通常有用但是大多数情况下效率不高。如果需要根据不同的值执行不同的函数,可以用case语句。
你可以通过创建一个重载函数对象来做到这一点,它将为不同的类型分开实现;正确的函数将根据存储在变体实例中的值的类型被调用。为了使之尽可能简短,让我们使用C++17中的语言特性。 与旧版编译器兼容的实现可在随附的代码示例中找到:
template <typename ...Ts>
struct overloaded : Ts... { using Ts::operator()...; };
template <typename ...Ts> overloaded(Ts...) -> overloaded<Ts...>;
overloaded模板接受一个函数对象的列表,并创建一个新的函数对象,将所有提供的函数对象的调用操作符作为自己的对象(using Ts::operator()…部分)。
{% note NOTE %} 实现重载结构的代码片断使用了C++17中引入的类的模板参数推导。 模板参数推导依赖于类的构造函数来找出模板参数。你可以提供一个构造函数,或者像前面的例子那样提供一个推导准则。 {% endnote %}
测试overloaded的代码:
#include <variant>
#include <string>
#include <iostream>
template<typename ...Ts>
struct overloaded : Ts ...
{
using Ts::operator()...;
};
template<typename ...Ts>
overloaded(Ts...) -> overloaded<Ts...>;
struct Point
{
double x;
double y;
};
int main()
{
using V = std::variant<int, double, std::string, Point>;
V v_int{1};
V v_dbl{1.0};
V v_str{"aa"};
V v_pnt{Point{1.0, 2.0}};
auto visitor = overloaded{
[](int i) {
std::cout << "int:" << i << std::endl;
},
[](double i) {
std::cout << "double:" << i << std::endl;
},
[](std::string i) {
std::cout << "std::string:" << i << std::endl;
},
[](Point i) {
std::cout << "Point:{" << i.x << "," << i.y << "}" << std::endl;
},
};
std::visit(visitor, v_int);
std::visit(visitor, v_dbl);
std::visit(visitor, v_str);
std::visit(visitor, v_pnt);
}
结果:
int:1
double:1
std::string:aa
Point:{1,2}
overloaded的实现可以在std::visit的例子里面找到。现在可以简化网球状态的switch代码
void point_for(player which_player)
{
std::visit(
overloaded {
[&] (const normal_scoring &state) {
// 增加分数,或者切换状态
},
[&] (const forty_scoring &state) {
// 运动员胜利,或者切换到两点
},
[&] (const deuce &state) {
// 切换到优势状态
},
[&] (const advantage &state) {
// 玩家胜利,或者切换到两点
}
},
m_state);
);
}
{% note NOTE %} λ表达式可以理解为callable class,本质上也是一个类 {% endnote %}
std::visit调用重载函数对象,该对象将给定的类型与它的所有重载进行匹配,并执行最匹配的那一个(类型上)。 虽然语法没有那么漂亮,但这段代码提供了switch语句的有效等价物,它对存储在变体中的对象的类型起作用。
你可以很容易地为std::optional、为expected类、甚至为基于继承的和类型创建一个访问函数,这将给你一个统一的语法来处理你创建的所有和类型。
9.4 用Mach7库进行强大的模式匹配
到目前为止,你已经看到了对类型的简单模式匹配。你可以通过把if-else链隐藏在类似于overloaded的结构后面,轻松地创建对特定值的匹配。
但如果能够对更高级的模式进行匹配,那就更有用了。例如,当玩家少于30分时,你可能需要单独的处理程序来处理normal_scoring,以及当他们有30分时,因为在这种情况下,你需要将比赛状态改为forty_scoring。
不幸的是,C++没有一个允许这样做的语法。但一个叫Mach7的库可以让你写出更高级的模式,尽管语法有点尴尬。
使用Mach7来更高效的进行模式匹配
Mach7库是由Yuriy Solodkyy、Gabriel Dos Reis和Bjarne Stroustrup创建的,作为一个实验,最终将被用作扩展C++以支持模式匹配的基础。尽管这个库是作为一个实验开始的,但它被认为足够稳定,可以普遍使用。它通常比访问者模式(不要与std::visitor的变体混淆)更有效。Mach7的主要缺点是它的语法。
使用Mach7函数形式变为:
void point_for(player which_player)
{
Match(m_state)
{
...
// 如果拥有40分的选手赢得了球,他们就赢得了比赛;不需要考虑另一个选手的分数。
Case(C<forty_scoring>(which_player, _))
// 如果球是由没有得到40分的一方赢得的(前面的情况不是比赛),而另一方目前的分数是30分,那么比赛就处于两分。
Case(C<forty_scoring>(_, 30))
// 如果前面两种情况都不符合,则增加该玩家的积分。
Case(C<forty_scoring>())
...
}
EndMatch
}
10 单子
单子(Monads)
10.1 不是你父亲的函子
函子是数学的一个抽象分支——范畴论中的一个概念,它的正式定义听起来和它的理论一样抽象。我们将以一种对C++开发人员来说更直观的方式来定义它。
如果一个类模板F有一个定义在它上面的转换(或映射)函数,那么它就是一个函子(见图10.1)。转换函数接收一个类型为F<T1>的实例f和一个函数t。T1 → T2,并返回一个F<T2>类型的值。这个函数可以有多种形式,所以为了清楚起见,我们将使用第七章中的管道符号。
转换函数需要遵守以下两个规则:
- 用一个身份函数转换一个函子实例,会返回相同的(等于)函子实例。
f | transform([] (auto value) { return value; }) == f
- 用一个函数转换一个函子,然后用另一个函数转换,这与用这两个函数的组合转换函子是一样的。
f | transform(t1) | transform(t2) ==
f | transform([=](auto value) { return t2(t1(value)); })
这看起来很像std::transform算法和range库的view::transform。 这不是偶然的:来自STL的泛型集合和范围是函子。 它们都是包装类型,在它们身上定义了一个良好的变换函数。值得注意的是,另一个方向并不成立:不是所有的函子都是集合或范围。
10.1.1 处理optional值
其中一个最基础的函子是std::optional类型。它需要一个转换函数定义它
template <typename T1, typename F>
auto transform(const std::optional<T1> &opt, F f)
-> decltype(std::make_optional(f(opt.value())))
{
if (opt) {
return std::make_optional(f(opt.value()));
} else {
return {};
}
}
另外,你可以创建一个range view,当std::optional包含一个值时,它将给出一个元素,否则就是一个空范围。这将使你能够使用管道语法。(查看 functors-optional 代码示例,它定义了as_range函数,将std::optional转换为最多一个元素的范围。)
与用if-else语句手动处理缺失值相比,使用转换函数有什么好处?请考虑以下情况。你有一个管理用户登录的系统。它可以有两种状态:用户要么登录,要么不登录。很自然的,用一个std::optional<std::string>类型的current_login变量来表示。 如果用户没有登录,current_login的可选值将为空;否则它将包含用户名。我们将使current_login变量成为一个全局变量,以简化代码示例。
现在想象一下,你有一个检索用户全名的函数和一个将你传递给它的任何内容创建为HTML格式的字符串的函数:
std::string user_full_name(const std::string& login);
std::string to_html(const std::string& text);
为了得到当前用户的HTML格式的字符串,你可以随时检查是否有一个当前用户,或者你可以创建一个函数,返回std::optional<std::string>。如果没有用户登录,该函数返回一个空值;如果有用户登录,它将返回格式化的全名。这个函数的实现很简单,因为你已经有了一个能对可选值起作用的转换函数。
transform(
transform(
current_login,
user_full_name),
to_html);
或者,为了返回一个range,你可以通过使用管道语法来执行转换:
auto login_as_range = as_range(current_login);
login_as_range | view::transform(user_full_name)
| view::transform(to_html);
看了这两个实现,有一点很明显:没有任何东西说这段代码对可选值有效。它可以适用于数组、向量、列表或其他任何定义了转换函数的东西。如果你决定用任何其他的函数来代替std::optional,你不需要改变代码。
范围的特殊性
需要注意的是,没有从
std::optional到range的自动转换,反之亦然,所以你需要手动执行转换。严格来说,view::transform函数并没有正确地定义为使某物成为一个函数。这个函数总是返回一个范围,而不是你传递给它的同一类型。这种行为可能是有问题的,因为你不得不手动转换类型。但当你考虑到范围所提供的好处时,这只是一个小麻烦。
想象一下,你想创建一个函数,接收一个用户名的列表,并给你一个格式化的全名列表。 该函数的实现将与在可选值上工作的函数相一致。使用expected<T, E>而不是std::optional<T>的函数也是如此。 这就是广泛适用的抽象(如函数)带给你的力量:你可以编写通用代码,在各种情况下都能正常工作。
10.2 单子:比函子更强大
函子允许你轻松地处理包装好的值的转换,但它们有一个严重的限制。想象一下,函数user_full_name和to_html会失败。而且它们不是返回字符串,而是返回std::optional<std::string>:
std::optional<std::string> user_full_name(const std::string &login);
std::optional<std::string> to_html(const std::string &text);
在这种情况下,转换函数不会有什么帮助。 如果你试图使用它并写出与前面例子相同的代码,你会得到一个复杂的结果。作为提醒,transform接收了一个函子F<T1>的实例和一个从T1到T2的函数,并且它返回了一个F<T2>的实例。
transform(current_login, user_full_name)
返回函数类型不为std::optional<std::string>。user_full_namefunction接收一个字符串并返回一个optional值,使得T2 = std::optional<std::string>。这反过来又使变换的结果成为一个嵌套的可选值std::optional<std::optional<std::string>。你执行的转换越多,你得到的嵌套就越多——这处理起来是不愉快的。
这就是单子引入的地方。一个单子M<T>是一个具有定义在其上的额外函数的函子——一个去除一级嵌套的函数:
join: M<M<T>> -> M<T>
通过join,你不再有使用不返回普通值而是返回单子(functor)实例的函数的问题了。
代码变为如下:
join(transform(
join(transform(
current_login,
user_full_name)),
to_html))
// 或者写成range的形式
auto login_as_range = as_range(current_login);
login_as_range | view::transform(user_full_name)
| view::join
| view::transform(to_html)
| view::join;
当你改变函数的返回类型时,你做了一个侵入性的改变。如果你通过使用if-else检查来实现一切,你将不得不对代码进行重大的修改。在这里,你需要避免对一个值进行多次包装。
很明显,您可以进一步简化它。在前面的所有转换中,您都对结果执行连接。你能把它们合并成一个函数吗?
你可以——这是一种更常见的定义单子的方法。你可以说一个单子M是一个包装类型,它有一个构造函数(一个从T类型的值构造M<T>实例的函数)和一个mbind函数(它通常被称为bind,但我们将使用这个名字,所以它不会与std::bind混淆),它是transform和join的组合:
construct: T → M<T>
mbind: (M<T1>, T1 → M<T2>) → M<T2>
很容易证明所有的单子都是函子。使用mbind和construct实现转换很简单。
与函子的情况一样,有一些规则。为了在你的程序中使用单子,它们不是必需的:
- 如果你有一个函数
f:T1 → M<T2>以及一个T1的值,将该值包装到单子M中,然后将其与函数f绑定与在其上调用函数f相同:
mbind(construct(a), f) == f(a)
- 这条规则是一样的,只是转过来。如果将包装值绑定到构造函数,则会得到相同的包装值:
mbind(m, construct) == m
- 这个规则不太直观。它定义了
mbind操作的关联性:
mbind(mbind(m, f), g) == mbind(m, [] (auto x) {
return mbind(f(x), g) })
尽管这些规则可能看起来令人反感,但它们的存在是为了精确定义一个行为良好的单子。 从现在开始,您将依赖您的直觉:单子是您可以构造并绑定到函数的东西。
10.3 基础的例子
让我们从几个简单的例子开始。正确学习C++时,首先要了解基本类型,而第一个包装类型是std::vector。那么,让我们看看如何从中创建一个函子。你需要检查两件事:
- 函子是包含一个模板变量的类
- 您需要一个可以采用一个
vector的transform函数,以及一个可以转换其元素的函数。transform将返回转换后元素的vector
douglasgeorgekurtgraham…dgkg…transform字符串向量首字母向量字符串转换为首字母的变换
std::vector是一个类模板,所以你很好。有了范围,实现适当的变换功能是轻而易举的事:
template <typename T, typename F>
auto transform(const std::vector<T>& xs, F f)
{
return xs | view::transform(f) | to_vector;
}
您将给定的vector视为一个range,并使用f转换其每个元素。为了让函数返回一个vector,按照函子定义的要求,您需要将结果转换回vector。如果你想更宽松,你可以返回一个range。
现在你有了一个函子,让我们把它变成一个单子。在这里你需要construct 和mbind函数。construct应该取一个值并从中创建一个vector。 这 自然的事情是使用vector的实际构造函数。 如果你想写一个合适的 从单个值构造vector的函数,您可以轻松地制作一些东西 像这样:
template <typename T>
std::vector<T> make_vector(T&& value)
{
return {std::forward<T>(value)};
}
使用
std::forward来做完美转发
你只剩下mbind了。要实现它,考虑变换加连接很有用
douglasgeorgekurtgraham…dgkgtransform字符串向量合并成向量字符串转换为依次每个字符…oug…eoroaorh……douglasgeorgekurtgrahamjoin包含了原来字符串向量的所有字符
mbind函数(与transform不同)需要一个将值映射到单子实例的函数——在本例中,映射到std::vector的实例。这意味着对于原始向量中的每个元素,它将返回一个新向量,而不仅仅是一个元素。
template <typename T, typename F>
auto mbind(const std::vector<T>& xs, F f)
{
auto transformed =
xs | view::transform(f)
| to_vector;
return transformed
| view::join
| to_vector;
}
您已经为vector实现了mbind函数。 它的效率不如预期的那么高,因为它将所有中间结果保存到临时向量中;但重点是这说明了std::vector是一个单子。
该示例将
mbind定义为一个接受两个参数并返回结果的函数。为方便起见,本章的其余部分使用带有管道语法的mbind函数,因为它更具可读性。我会写xs | mbind(f)而不是mbind(xs, f)。 这不是你可以开箱即用的东西——它需要一些样板,你可以在本书随附的10-monad-vector和10-monad-range示例中看到。
10.4 范围和单子理解
Range and monad comprehensions
我们用于向量的相同方法适用于类似的集合,例如数组和列表。所有这些集合在你工作的抽象级别方面都是相似的。它们是相同类型项目的平面集合。
上面图里面的transfrom也可以用来筛选固定的元素,如果不符合条件返回空的集合,然后用join组装起来
mbind的过滤
template <typename C, typename P>
auto filter(const C& collection, P predicate)
{
return collection
| mbind([=](auto element) {
return view::single(element)
| view::take(predicate(element)
? 1 : 0);
});
}
想象一下,您需要生成一个毕达哥拉斯三元组列表(两个数字的平方和等于第三个数字的平方)。要使用for循环编写它,您需要嵌套其中三个。mbind函数允许您使用范围执行类似的嵌套
view::ints(1)
| mbind([](int z) {
return view::ints(1, z)
| mbind([z](int y) {
return view::ints(y, z) |
view::transform([y,z](int x) {
return std::make_tuple(x, y, z);
});
});
})
| filter([] (auto triple) {
...
});
使用for_each和yield_if
view::for_each(view::ints(1), [](int z) {
return view::for_each(view::ints(1, z), [z](int y) {
return view::for_each(view::ints(y, z), [y,z](int x) {
return yield_if(
x * x + y * y == z * z,
std::make_tuple(x, y, z)
);
});
});
});
范围理解有两个组成部分。第一个是for_each,它遍历你给它的任何集合,并收集你传递给它的函数产生的所有值。如果您有多个嵌套范围推导,则所有产生的值都会连续放置在结果范围中。范围推导不会生成范围的范围;它使结果变平。第二部分是yield_if。如果指定为第一个参数的谓词成立,它将在结果范围内放置一个值。
简而言之,范围理解只不过是与filter结合的变换或mbind 。而且因为这些函数存在于任何单子中,不仅适用于范围,我们也可以称它们为单子推导式。
10.5 失败处理
不通过抛出异常的方式
10.5.1 std::optional<T>作为单子
optional允许你表达一个值可能会丢失的可能性。虽然这本身很好,但使用可选项有一个缺点:如果要使用它,则需要不断检查该值是否存在。对于您之前定义的user_full_name和to_html函数,它们返回std::optional<std::string>,您会得到充斥着检查的代码:
std::optional<std::string> current_user_html()
{
if (!current_login) {
return {};
}
const auto full_name = user_full_name(current_login.value());
if (!full_name) {
return {};
}
return to_html(full_name.value());
}
想象一下,您有更多需要像这样链接的功能。代码将开始看起来像旧的C代码,几乎每次函数调用后都必须检查errno。
相反,你会做一些更聪明的事情。一旦你看到一个值的上下文应该在调用另一个函数时被剥离,想想单子。对于可选值,上下文是有关该值是否存在的信息。因为其他函数取普通值,调用时需要去掉这个上下文。
这正是单子允许您做的事情:编写函数而无需做任何额外的工作来处理上下文信息。 std::make_optional是单子的构造函数,mbind很容易定义
template <typename T, typename F>
auto mbind(const std::optional<T>& opt, F f)
-> decltype(f(opt.value()))
{
if (opt) {
return f(opt.value());
} else {
return {};
}
}
如果原始值丢失或函数f失败并返回一个空的可选项,这将给出一个空结果。否则返回有效结果。如果您使用这种方法链接多个函数,您将获得自动错误处理:这些函数将一直执行,直到第一个失败。 如果没有函数失败,你会得到结果。
现在函数变得简单多了:
std::optional<std::string> current_user_html()
{
return mbind(
mbind(current_login, user_full_name),
to_html);
}
或者,您可以创建一个mbind转换,它与范围具有相同的管道语法,并使代码更具可读性:
std::optional<std::string> current_user_html()
{
return current_login | mbind(user_full_name)
| mbind(to_html);
}
这看起来与单子示例完全一样。在那种情况下,你有普通的功能并使用了transform;在这里,函数返回optional值,并且您正在使用mbind。
10.5.2 expected<T, E>作为单子
std::optional只能告诉你有错误但是不知道原因,而expected<T, E>两个都做到了,单子实现如下:
template <
typename T, typename E, typename F,
typename Ret = typename std::result_of<F(T)>::type
>
Ret mbind(const expected<T, E>& exp, F f)
{
if (!exp) {
return Ret::error(exp.error());
}
return f(exp.value());
}
您可以轻松地转换函数,不仅可以判断您是否有值,还可以包含错误。为了简单起见,让我们使用整数来表示错误:
expected<std::string, int> user_full_name(const std::string& login);
expected<std::string, int> to_html(const std::string& text);
current_user_html函数的实现不需要改变:
expected<std::string, int> current_user_html()
{
return current_login | mbind(user_full_name)
| mbind(to_html);
}
和以前一样,如果没有发生错误,该函数将返回一个值。否则,一旦您绑定的任何函数返回错误,执行将停止并将该错误返回给调用者
需要注意的是,对于单子,您需要一个模板参数,而这里有两个。如果您需要对错误执行转换而不是对值执行转换,则可以轻松地对错误执行mbind。
10.5.3 try单子
预期类型允许你使用任何东西作为错误类型。你可以使用整数作为错误代码,使用字符串来表达错误信息,或者两者的某种组合。你也可以通过指定错误类型为std::exception_ptr来使用与正常异常处理相同的异常类层次结构。
NOTE:
std::result在c++17已经弃用,可以使用std::invoke_result
template<typename F,
typename Ret = typename std::invoke_result<F>::type,
typename Exp = expected<Ret, std::exception_ptr>>
Exp mtry(F f)
{
try {
return Exp::success(f());
} catch (...) {
return Exp::failed(std::current_exception());
}
}
auto result = mtry([=] {
auto users = system.users();
if (users.empty()) {
throw std::runtime_error("No users");
}
return users[0];
});
// 还可以另外方式实现
template<typename T>
T get_or_throw(const expected<T, std::exception_ptr> &exp)
{
if (exp) {
return exp.value();
} else {
std::rethrow_exception(exp.error());
}
}
std::current_exception可以获取当前的异常指针,类型为std::exception_ptr。
#include <iostream>
#include <string>
#include <exception>
#include <stdexcept>
void handle_eptr(std::exception_ptr eptr) // 可以按值传递
{
try {
if (eptr) {
std::rethrow_exception(eptr);
}
} catch(const std::exception& e) {
std::cout << "Caught exception \"" << e.what() << "\"\n";
}
}
int main()
{
std::exception_ptr eptr;
try {
std::string().at(1); // 生成 std::out_of_range
} catch(...) {
eptr = std::current_exception(); // 捕获
}
handle_eptr(eptr);
} // 析构 std::out_of_range 调用
10.6 处理单子的状态
单体在函数式世界中流行的原因之一是,你可以用一种纯粹的方式实现有状态的程序。 对我们来说,这并不是必须的;我们在C++中一直有可变的状态。
另一方面,如果你想通过使用单子和不同的单子转换链来实现程序,能够跟踪这些链的每一个状态可能会很有用。如果你想要纯函数,它们不能有任何副作用;你不能从外部世界改变任何东西。那么,你怎么能改变状态呢?
不纯的函数可以对状态进行隐性改变。仅仅通过调用函数,你看不到发生了什么,也看不到什么被改变了。如果你想以一种纯粹的方式来改变状态,你需要使每一个改变都是显式的。
最简单的方法是把当前状态和常规参数一起传递给每个函数:函数应该返回新的状态。我在第5章中谈到了这个想法,在那里我们接受了通过创建新的世界而不是改变当前世界来处理可变状态的想法。
使用之前的例子但是不用optional或者expected,而是使用日志debug
template <typename T>
class with_log
{
public:
with_log(T value, std::string log = std::string()) :
: m_value(value),
m_log(log) {}
T value() const { return m_value; }
std::string log() { return m_log; }
private:
T m_value;
std::string m_log;
};
然后重新定义user_full_name和to_html
with_log<std::string> user_full_name(const std::string &login);
with_log<std::string> to_html(const std::string &text);
mbind函数
template<typename T,
typename F
typename Ret = typename std::invoke_result<F, T>::type>
Ret mbind(const with_log<T> &val, F f)
{
const auto result_with_log = f(val.value());
return Ret(result_with_log.value(), val.log() + result_with_log.log());
}
使用这种方式可以把每个链的日志依次记录下来。你可以有多个并行日志–一个用于你创建的每个单体转换链,而不需要任何特殊的日志设施。一个函数可以写到不同的日志,这取决于谁调用了它,你不必指定 “这个日志在这里”和 “那个日志在那里”。 此外,这种日志方法可以让你在异步操作链中保留日志,而不需要交织不同链的调试输出。
10.7 并发和延续单子
对于类似std::cin流的容器,程序可能需要阻塞直到用户输入完所有数据,这对于交互来说很不友好。这时需要用到future
10.7.1 Futures作为单子
首先确认future能否作为函子。你需要能够创建一个转换函数,它接受一个future<T1>和一个函数 f: T1 → T2,然后返回一个future<T2>的实例。
返回future的函数改为:
future<std::string> user_full_name(const std::string& login);
future<std::string> to_html(const std::string& text);
然后使用mbind函数
future<std::string> current_user_html()
{
return current_user() | mbind(user_full_name)
| mbind(to_html);
}
在这个片段中,三个异步操作被自然地链接在一起。每个函数都继续了前一个函数所做的工作。因此,传递给mbind的函数通常被称为 continuation ,而你定义的future-value monad被称为 continuation monad。
10.7.2 futures的实现
与阻塞获取future的值,不如编写如果future已经可以了该做什么的函数。
future的mbind实现如下:
template<typname T, typename F>
auto mbind(const future<T> &future, F f)
{
return future.then(
[] (future<T> finished) {
return f(finished.get());
});
}
在通常的 C++ 生态系统之外,还有一些其他库实现了它们自己的 futures。它们中的大多数都使用基本概念,并添加了处理和报告异步操作期间可能发生的错误的功能。
除了标准库和 Boost 之外,最值得注意的例子是 Folly 库的 Future 类和 Qt 的 QFuture。Folly 提供了一个干净的 future 概念实现,它永远不会阻塞(如果 future 没有准备好,.get 将抛出异常,而不是阻塞)。QFuture 通过使用信号和槽的方式连接 continuation,但它也像标准库的 future 一样在 .get 上阻塞。QFuture 还具有超越基本概念的其他功能,它可以收集多个值而不仅仅是单个结果。尽管存在这些少量差异,但所有这些类都可以使用单子绑定操作来链接多个异步操作。
10.8 单子组合
返回单子类型的函数
user_full_name : std::string -> M<std::string>
to_html : std::string -> M<std::string>
例如:
M<std::string> user_html(const M<std::string> &login)
{
return mbind(mbind(login, user_full_name), to_html);
}
user_html就是user_full_name和to_html的组合
返回单子的组合函数模板
template <typename F, typename G>
auto mcompose(F f, G g)
{
return [=](auto value) {
return mbind(f(value), g);
}
}
这样就可以直接改为:
auto user_html = mcompose(user_full_name, to_html);
mcompose 函数也可以用于更简单的单子,例如 ranges(以及 vectors、lists 和 arrays)。假设你有一个 children 函数,它给出一个包含指定人的所有子代的 range。它具有单子函数的正确签名:它接受一个 person_t 值,并产生一个 person_t 的 range。你可以创建一个函数来检索所有grandchildren。
auto grandchildren = mcompose(children, children);
Kleisli组合
如果把单子函数和构造函数组合,仍然是同样的函数
mcompose(f, construct) == f
mcompose(construct, f) == f
如果有三个函数f,g和h,可以组合成如下结果
mcompose(f, mcompose(g, h)) == mcompose(mcompose(f, g), h)
这个叫Kleisli组合

 浙公网安备 33010602011771号
浙公网安备 33010602011771号