MyBatis(2):深入学习
请注意,本文学习自 @我没有三颗心脏
编写日志输出环境配置文件
在开发过程中,最重要的就是在控制台查看程序输出的日志信息,在这里我们选择使用 log4j 工具来输出:
-
准备工作: 将【MyBatis】文件夹下【lib】中的 log4j 开头的 jar 包都导入工程并添加依赖。
在【src.main.resources】下新建一个文件 log4j.properties 资源:# Global logging configuration # 在开发环境下日志级别要设置成 DEBUG ,生产环境设为 INFO 或 ERROR log4j.rootLogger=DEBUG, stdout # Console output... log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n其中,第一条配置语句 “
log4j.rootLogger=DEBUG, stdout” 指的是日志输出级别,一共有 7 个级别(OFF、 FATAL、 ERROR、 WARN、 INFO、 DEBUG、 ALL)。- 一般常用的日志输出级别分别为 DEBUG、 INFO、 ERROR 以及 WARN,分别表示 “调试级别”、 “标准信息级别”、 “错误级别”、 “异常级别”。如果需要查看程序运行的详细步骤信息,一般选择 “DEBUG” 级别,因为该级别在程序运行期间,会在控制台才打印出底层的运行信息,以及在程序中使用 Log 对象打印出调试信息。
- 如果是日常的运行,选择 “INFO” 级别,该级别会在控制台打印出程序运行的主要步骤信息。“ERROR” 和 “WARN” 级别分别代表 “不影响程序运行的错误事件” 和 “潜在的错误情形”。
- 文件中 “stdout” 这段配置的意思就是将 DEBUG 的日志信息输出到 stdout 参数所指定的输出载体中。
第二条配置语句 “
log4j.appender.stdout=org.apache.log4j.ConsoleAppender” 的含义是,设置名为 stdout 的输出端载体是哪种类型。- 目前输出载体有
ConsoleAppender(控制台)
FileAppender(文件)
DailyRollingFileAppender(每天产生一个日志文件)
RollingFileAppender(文件大小到达指定大小时产生一个新的文件)
WriterAppender(将日志信息以流格式发送到任意指定的地方) - 这里要将日志打印到 IDEA 的控制台,所以选择 ConsoleAppender
第三条配置语句 “
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout” 的含义是,名为 stdout 的输出载体的 layout(即界面布局)是哪种类型。- 目前输出端的界面类型分为
HTMLLayout(以 HTML 表格形式布局)
PatternLayout(可以灵活地指定布局模式)
SimpleLayout(包含日志信息的级别和信息字符串)
TTCCLayout(包含日志产生的时间、线程、类别等信息) - 这里选择灵活指定其布局类型,即自己去配置布局。
第四条配置语句 “
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n” 的含义是,如果 layout 界面布局选择了 PatternLayout 灵活布局类型,要指定的打印信息的具体格式。- 格式信息配置元素大致如下:
%m 输出代码中的指定的信息
%p 输出优先级,即 DEBUG、 INFO、 WARN、 ERROR 和 FATAL
%r 输出自应用启动到输出该 log 信息耗费的毫秒数
%c 输出所属的类目,通常就是所在类的全名
%t 输出产生该日志事件的线程名
%n 输出一个回车换行符,Windows 平台为 “rn”,UNIX 平台为 “n”
%d 输出日志时的时间或日期,默认个事为 ISO8601,也可以在其后指定格式,比如 %d{yyy MMM dd HH:mm:ss},输出类似:2018 年 4 月18 日 10:32:00
%l 输出日志事件的发生位置,包括类目名、发生的线程,以及在代码中的行数
MyBatis 高级映射
在上一篇文章中,我们讲解了一个 MyBatis 的入门程序的开发,了解了 MyBatis 开发的基本内容。今天我们先来了解一下 MyBatis 是如何处理多张数据库表之间的关联关系,其中包括:
- 一对一的查询
- 一对多查询
- 多对多查询
- 延迟加载
一对一查询
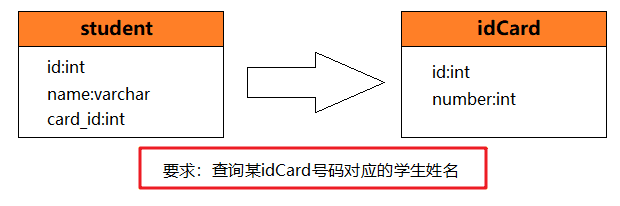
首先我们先来建立一个数据模型(删掉之前创建的 student 表):
use mybatis;
CREATE TABLE student (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(255) DEFAULT NULL,
card_id int(11) NOT NULL,
PRIMARY KEY (id)
)AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE card (
id int(11) NOT NULL AUTO_INCREMENT,
number int(11) NOT NULL,
PRIMARY KEY (id)
)AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO student VALUES (1,'student1',1);
INSERT INTO student VALUES (2,'student2',2);
INSERT INTO card VALUES (1,1111);
INSERT INTO card VALUES (2,2222);
- 注意: 这里并没有在数据库中设置外键,而是让 MyBatis 去处理多表之间的关系。事实上,外键只是用来保证数据一致性,在某些特殊的情况下(例如高并发秒杀系统中),会专门设置不适用外键,因为存在一定的性能损耗。
然后我们要来确认我们查询的 SQL 语句,我们或许可以简单的写成下面这样:
SELECT
student.*,
card.*
FROM
student,card
WHERE student.card_id = card.id AND card.number = #{value}
- 提示: 在日常开发中,总是先确定业务的具体 SQL ,再将此 SQL 配置在 Mapper 文件中
确定了主要的查询 SQL 后,接下来我们分别使用 resultType 和 resultMap 来实现这个一对一查询的实例。
1. 使用 resultType 实现
首先创建学生 student 表所对应的 Java 实体类 Student,其中封装的属性信息为响应数据库中的字段:
package pojo;
public class Student {
int id;
String name;
int card_id;
/* getter and setter */
}
最终我们执行查询(上述的 SQL 语句)的结果如下:
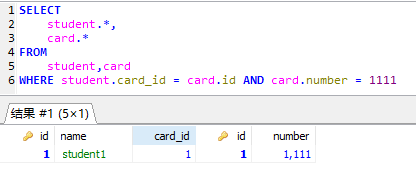
由于最终的查询的结果是由 resultType 指定的,也就是只能映射一个确定的 Java 包装类,上面的 Stuent 类只包含了学生的基本信息,并没有包含 Card 的信息,所以我们要创建一个最终映射类,以 Student 类为父类,然后追加 Card 的信息:
package pojo;
public class StudentAndCard extends Student {
private int number;
/* getter and setter /*
}
然后在 Student.xml 映射文件中定义 <select> 类型的查询语句 SQL 配置,将之前设计好的 SQL 语句配置进去,然后指定输出参数属性为 resultType,类型为 StudentAndCard 这个 Java 包装类:
<select id="findStudentByCard" parameterType="_int" resultType="Student">
SELECT
student.*,
card.*
FROM
student,card
WHERE student.card_id = card.id AND card.number = #{value}
</select>
然后在测试类中编写测试方法:
@Test
public void test() throws IOException {
// 根据 mybatis-config.xml 配置的信息得到 sqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
// 然后根据 sqlSessionFactory 得到 session
SqlSession session = sqlSessionFactory.openSession();
// 找到身份证身份证号码为 1111 的学生
StudentAndCard student = session.selectOne("findStudentByCard",1111);
// 获得其姓名并输出
System.out.println(student.getName());
}
获得正确结果:
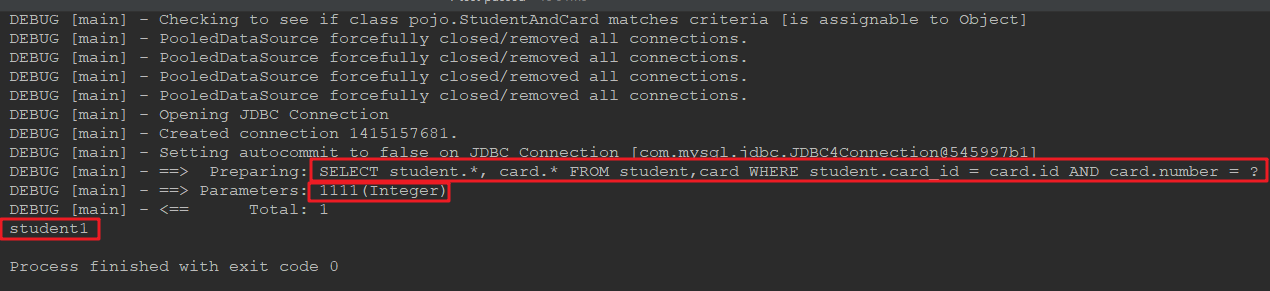
2. 使用 resultMap 实现
使用 resultMap 可以将数据字段映射到名称不一样的响应实体类属性上,重要的是,可以映射实体类中包裹的其他实体类。
首先我们来创建一个封装了 Card 号码和 Student 实体类的 StudentWithCard 类:
package pojo;
public class StudentWithCard {
Student student;
int number;
int id;
/* getter and setter */
}
SQL 语句依然没有变化,但是使用的输出映射属性改为了 resultMap ,其中的映射类型是 id 为 StudentInfoMap 的 resultMap 配置:
<select id="findStudentByCard" parameterType="_int" resultMap="StudentInfoMap">
SELECT
student.*,
card.*
FROM
student,card
WHERE student.card_id = card.id AND card.number = #{value}
</select>
<resultMap id="StudentInfoMap" type="pojo.StudentWithCard">
<!-- id 标签表示对应的主键
column 对应查询结果的列值
property 对应封装类中的属性名称
-->
<id column="id" property="id"/>
<result column="number" property="number"/>
<!-- association 表示关联的嵌套结果,
可以简单理解就是为封装类指定的标签
-->
<association property="student" javaType="pojo.Student">
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="card_id" property="card_id"/>
</association>
</resultMap>
稍微修改一下测试类,测试使用 resultMap 实现的一对一查询映射:
@Test
public void test() throws IOException {
// 根据 mybatis-config.xml 配置的信息得到 sqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
// 然后根据 sqlSessionFactory 得到 session
SqlSession session = sqlSessionFactory.openSession();
// 找到身份证身份证号码为 1111 的学生
StudentWithCard student = session.selectOne("findStudentByCard", 1111);
// 获得其姓名并输出
System.out.println(student.getStudent().getName());
}
测试仍然能得到正确的结果:
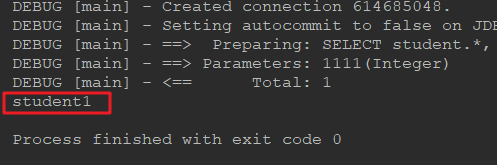
一对多查询
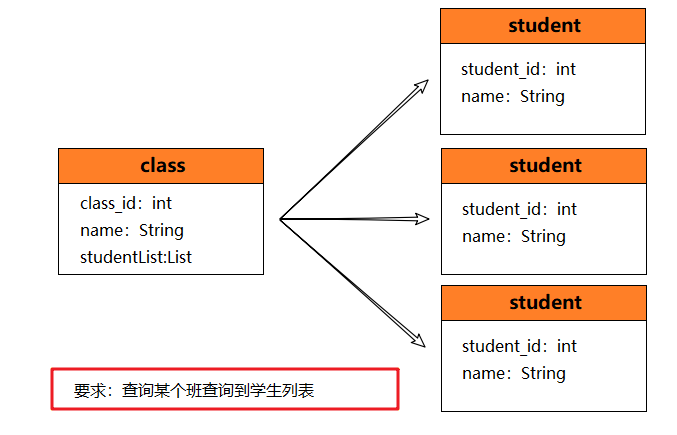
还是先来建立数据模型,删掉之前的:
use mybatis;
CREATE TABLE student (
student_id int(11) NOT NULL AUTO_INCREMENT,
name varchar(255) DEFAULT NULL,
PRIMARY KEY (student_id)
)AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE class (
class_id int(11) NOT NULL AUTO_INCREMENT,
name varchar(255) NOT NULL,
student_id int(11) NOT NULL,
PRIMARY KEY (class_id)
)AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO student VALUES (1,'student1');
INSERT INTO student VALUES (2,'student2');
INSERT INTO class VALUES (1,'Java课',1);
INSERT INTO class VALUES (2,'Java课',2);
- 其中 class 的
name字段表示课程的名称。
然后我们来编写我们的 SQL 语句:
SELECT
student.*
FROM
student, class
WHERE student.student_id = class.student_id AND class.class_id = #{value}
我们执行的结果如下:
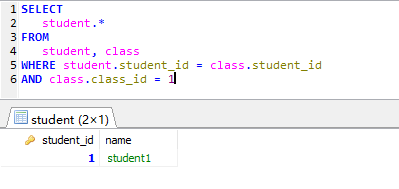
我们再来创建对应的实体类:
public class Student {
private int id;
private String name;
/* getter and setter */
}
public class Class {
private int id;
private String name;
private List<Student> students;
/* getter and setter */
}
在 Package【pojo】下新建一个【class.xml】文件完成配置:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="class">
<resultMap id="Students" type="pojo.Student">
<id column="student_id" property="id"/>
<result column="name" property="name"/>
</resultMap>
<select id="listStudentByClassName" parameterType="String" resultMap="Students">
SELECT
student.*
FROM
student, class
WHERE student.student_id = class.student_id AND class.name= #{value}
</select>
</mapper>
编写测试类:
@Test
public void test() throws IOException {
// 根据 mybatis-config.xml 配置的信息得到 sqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
// 然后根据 sqlSessionFactory 得到 session
SqlSession session = sqlSessionFactory.openSession();
// 查询上Java课的全部学生
List<Student> students = session.selectList("listStudentByClassName", "Java课");
for (Student student : students) {
System.out.println("ID:" + student.getId() + ",NAME:" + student.getName());
}
}
运行测试结果,成功:
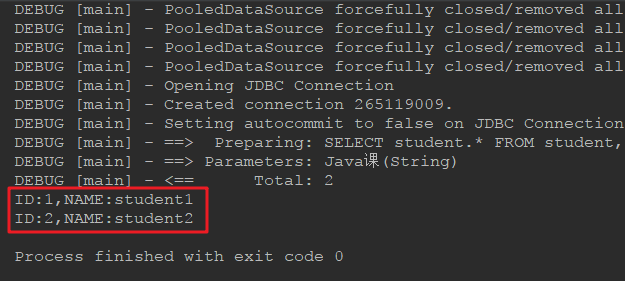
多对多查询
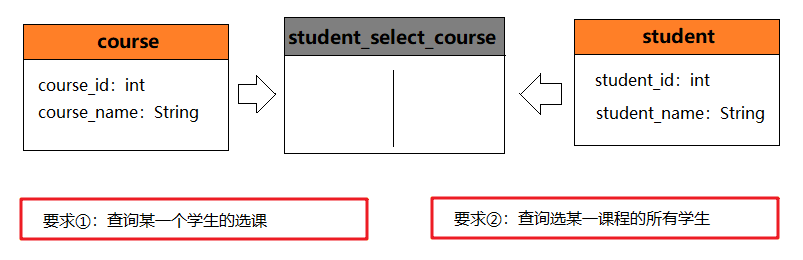
建立数据模型:
use mybatis;
CREATE TABLE students (
student_id int(11) NOT NULL AUTO_INCREMENT,
student_name varchar(255) DEFAULT NULL,
PRIMARY KEY (student_id)
)AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE courses (
course_id int(11) NOT NULL AUTO_INCREMENT,
course_name varchar(255) NOT NULL,
PRIMARY KEY (course_id)
)AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE student_select_course(
s_id int(11) NOT NULL,
c_id int(11) NOT NULL,
PRIMARY KEY(s_id,c_id)
) DEFAULT CHARSET=utf8;
INSERT INTO students VALUES (1,'student1');
INSERT INTO students VALUES (2,'student2');
INSERT INTO courses VALUES (1,'Java课');
INSERT INTO courses VALUES (2,'Java Web课');
INSERT INTO student_select_course VALUES(1,1);
INSERT INTO student_select_course VALUES(1,2);
INSERT INTO student_select_course VALUES(2,1);
INSERT INTO student_select_course VALUES(2,2);
根据要求我们来设计一下 SQL 语言:
SELECT
s.student_id,s.student_name
FROM
students s,student_select_course ssc,courses c
WHERE s.student_id = ssc.s_id
AND ssc.c_id = c.course_id
AND c.course_name = #{value}
执行 SQL 结果如下:
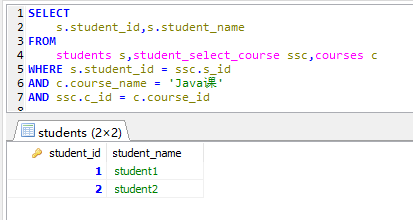
实体类雷同,就不再赘述,我们直接来配置映射文件【Student.xml】:
<resultMap id="Students" type="pojo.Student">
<id property="id" column="student_id"/>
<result column="student_name" property="name"/>
</resultMap>
<select id="findStudentsByCourseName" parameterType="String" resultMap="Students">
SELECT
s.student_id,s.student_name
FROM
students s,student_select_course ssc,courses c
WHERE s.student_id = ssc.s_id
AND ssc.c_id = c.course_id
AND c.course_name = #{value}
</select>
测试类也雷同,只需要修改一下调用的 id (改为findStudentsByCourseName)就好了,直接上测试结果:
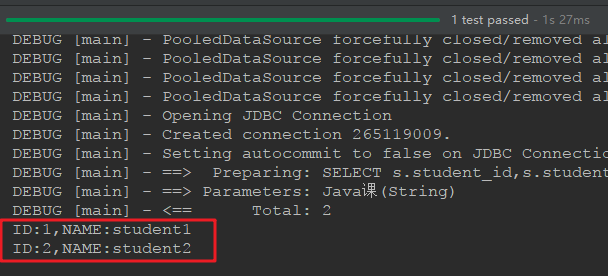
相反也是一样的,重要的是 SQL 语句和映射。
总结:
-
自己写的 SQL 语句看着虽然没有很恶心(至少思路清晰),但感觉很烂!
-
结合 SQL 语言和映射文件,能够很方便的操作数据库
-
数据库还是建立外键得好….(啪啪打脸,根据《阿里Java开发手册》里提到,最好不要建外键,而让程序的Service层去做判断)
-
MyBatis多表配置方式:
一对一配置:使用 <resultMap>做配置
一对多配置:使用 <resultMap>+<collection>做配置
多对多配置:使用<resultMap>+<collection>做配置
延迟加载
什么是延迟加载?从字面上理解,就是对某一类信息的加载之前需要延迟一会儿。在 MyBatis 中,通常会进行多表联合查询,但是有的时候不会立即用到所有的联合查询结果,这时候就可以采用延迟加载的功能。
- 功能: 延迟加载可以做到,先从单表查询,需要时再从关联表关联查询,这样就大大提高了数据库的性能,因为查询单表要比关联查询多张表速度快。
- 实例: 如果查询订单并且关联查询用户信息。如果先查询订单信息即可满足要求,当我们需要查询用户信息时再查询用户信息。把对用户信息的按需去查询就是延迟加载。
关联查询:
SELECT
orders.*, user.username
FROM orders, user
WHERE orders.user_id = user.id
延迟加载相当于:
SELECT
orders.*,
(SELECT username FROM USER WHERE orders.user_id = user.id)
username
FROM orders
所以这就比较直观了,也就是说,我把关联查询分两次来做,而不是一次性查出所有的。第一步只查询单表orders,必然会查出orders中的一个user_id字段,然后我再根据这个user_id查user表,也是单表查询。
Mapper 映射配置编写
首先在 Mapper 映射文件中定义只查询所有订单信息的 SQL :
<select id="findOrdersUserLazyLoading" resultMap="OrdersUserLazyLoadingResultMap">
SELECT * FROM orders
</select>
上面的 SQL 语句查询所有的订单信息,而每个订单信息中会关联查询用户,但由于希望延迟加载用户信息,所以会在 id 为 “OrdersUserLazyLoadingResultMap“ 的 resultMap 对应的结果集配置中进行配置:
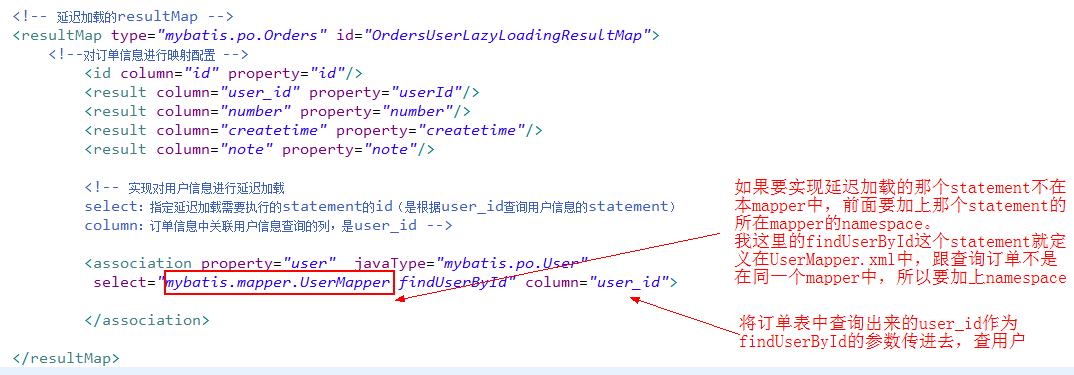
最后配置延迟加载要执行的获取用户信息的 SQL:
<select id="findUserById" parameterType="int" resultType="user">
select * from user where id = #{id}
</select>
上面的配置会被用来延迟加载的 resultMap 中的 association 调用,输入参数就是 association 中 column 中定义的字段信息。
在编写测试方法之前,首先需要开启延迟加载功能(这在 MyBatis 中默认是禁用掉的)。这需要在 MyBatis 的全局配置文件 mybatis-config.xml 中配置 setting 属性,将延迟加载(lazyLoadingEnable)的开关设置成 “ture” ,并且由于是按需加载,所以还需要将积极加载改为消极加载:
<settings>
<!-- 打开延迟加载的开关 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 将积极加载改为消极加载,即延迟加载 -->
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
- 注意: 在 configuration 中配置是有一定顺序的,具体可以按住【Ctrl】不放点击 configuration 属性,能看到如下信息(即定义的顺序):
<!ELEMENT configuration (properties?, settings?, typeAliases?, typeHandlers?, objectFactory?, objectWrapperFactory?, reflectorFactory?, plugins?, environments?, databaseIdProvider?, mappers?)>
Mapper 动态代理
什么是 Mapper 动态代理?一般创建 Web 工程时,从数据库取数据的逻辑会放置在 DAO 层(Date Access Object,数据访问对象)。使用 MyBatis 开发 Web 工程时,通过 Mapper 动态代理机制,可以只编写数据交互的接口及方法定义,和对应的 Mapper 映射文件,具体的交互方法实现由 MyBatis 来完成。这样大大节省了开发 DAO 层的时间。
实现 Mapper 代理的方法并不难,只需要遵循一定的开发规范即可。
Mapper 代理实例编写
我们编写一个使用 Mapper 代理查询学生信息的示例,首先还是在【pojo】下新建一个名为 StudentMapper.xml 的 Mapper 配置文件,其中包含了对 Student 的增删改查的 SQL 配置:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="mapper.StudentMapper">
<!-- 查询学生 -->
<select id="findStudentById" parameterType="_int" resultType="pojo.Student">
SELECT * FROM student WHERE student_id = #{id}
</select>
<!-- 增加用户 -->
<insert id="insertStudent" parameterType="pojo.Student">
INSERT INTO student(student_id, name) VALUES(#{id}, #{name})
</insert>
<!-- 删除用户 -->
<delete id="deleteStudent" parameterType="_int">
DELETE FROM student WHERE student_id = #{id}
</delete>
<!-- 修改用户 -->
<update id="updateStudent" parameterType="pojo.Student">
UPDATE student SET name = #{name} WHERE student_id = #{id}
</update>
</mapper>
如果需要使用 StudentMapper.xml 的 Mapper 代理,首先需要定义一个接口,名为 StudentMapper。然后在里面新建四个方法定义,分别对应 StudentMapper.xml 中的 Student 的增删改查的 SQL 配置,然后将 StudentMapper 中的 namespace 改为 StudentMapper 接口定义的地方(也就是 mapper 包下的 StudentMapper),这样就可以在业务类中使用 Mapper 代理了,接口代码如下:
package mapper;
import pojo.Student;
public interface StudentMapper {
// 根据 id 查询学生信息
public Student findStudentById(int id) throws Exception;
// 添加学生信息
public void insertStudent(Student student) throws Exception;
// 删除学生信息
public void deleteStudent(int id) throws Exception;
// 修改学生信息
public void updateStudent(Student student) throws Exception;
}
- 注意: 别忘了在 mybatis-config.xml 中配置一下 Mapper 映射文件
测试动态代理
在测试方法中,使用 SqlSession 类的 getMapper 方法,并将要加载的 Mapper 代理的接口类传递进去,就可以获得相关的 Mapper 代理对象,使用 Mapper 代理对象去对学生信息进行增删改查:
@Test
public void test() throws Exception {
// 根据 mybatis-config.xml 配置的信息得到 sqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
// 然后根据 sqlSessionFactory 得到 session
SqlSession session = sqlSessionFactory.openSession();
// 获取 Mapper 代理
StudentMapper studentMapper = session.getMapper(StudentMapper.class);
// 执行 Mapper 代理独享的查询方法
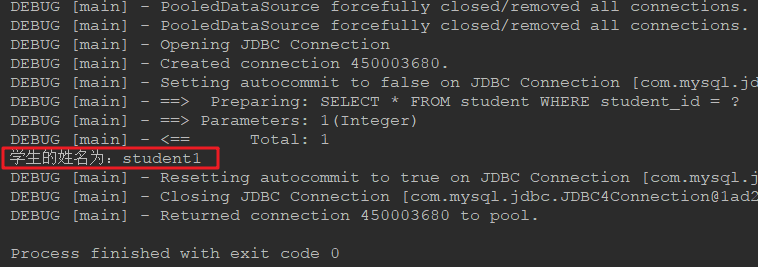
Student student = studentMapper.findStudentById(1);
System.out.println("学生的姓名为:" + student.getName());
session.close();
}
运行测试方法,看到正确的结果:
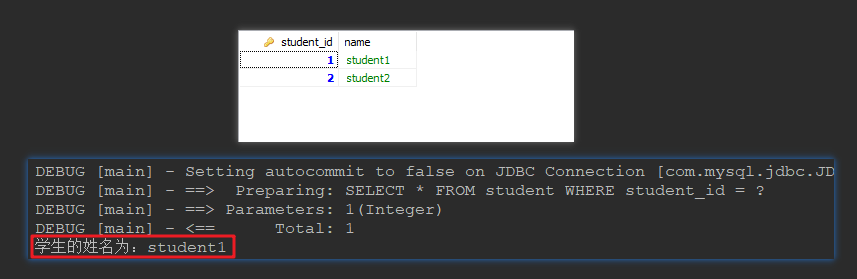
使用 Mapper 代理可以让开发更加简洁,使查询结构更加清晰,工程结构更加规范。
使用注解开发 MyBatis
在上面的例子中,我们已经有了方便的 Mapper 代理对象,我们可以进一步省掉 XML 的配置信息,进而使用方便的注解来开发 MyBatis ,让我们实际来操练一下:
@Insert:实现新增
@Update:实现更新
@Delete:实现删除
@Select:实现查询
@Result:实现结果集封装
@Results:可以与@Result 一起使用,封装多个结果集
@One:实现一对一结果集封装
@Many:实现一对多结果集封装
第一步:为 Mapper 增加注解
我们把 StudentMapper.xml 下配置的 SQL 语句通过注解的方式原封不动的配置在 StudentMapper 接口中:
public interface StudentMapper {
// 根据 id 查询学生信息
@Select("SELECT * FROM student WHERE student_id = #{id}")
public Student findStudentById(int id) throws Exception;
// 添加学生信息
@Insert("INSERT INTO student(student_id, name) VALUES(#{id}, #{name})")
public void insertStudent(Student student) throws Exception;
// 删除学生信息
@Delete("DELETE FROM student WHERE student_id = #{id}")
public void deleteStudent(int id) throws Exception;
// 修改学生信息
@Update("UPDATE student SET name = #{name} WHERE student_id = #{id}")
public void updateStudent(Student student) throws Exception;
}
第二步:修改 mybatis-config.xml
将之前配置的映射注释掉,新建一条:
<!-- 映射文件 -->
<mappers>
<!--<mapper resource="pojo/StudentMapper.xml"/>-->
<mapper class="mapper.StudentMapper"/>
<!-- 直接包扫描也可以 -->
<!-- <package name="com.riotian.mapper"></package> -->
</mappers>
- 注意: 这次映射的并不是文件(使用
resource属性),而是类(使用class属性)
第三步:运行测试代码
上面的测试代码不用修改,直接运行,也能得到正确结果:
MyBatis的注解实现复杂映射开发
实现复杂关系映射之前我们可以在映射文件中通过配置 <resultMap>来实现,使用注解开发后,我们可以使用@Results注解,@Result注解,@One注解,@Many注解组合完成复杂关系的配置


更多的注解:戳这里
MyBatis 缓存结构
在 Web 系统中,最重要的操作就是查询数据库中的数据。但是有些时候查询数据的频率非常高,这是很耗费数据库资源的,往往会导致数据库查询效率极低,影响客户的操作体验。于是我们可以将一些变动不大且访问频率高的数据,放置在一个缓存容器中,用户下一次查询时就从缓存容器中获取结果。
- MyBatis 拥有自己的缓存结构,可以用来缓解数据库压力,加快查询速度。
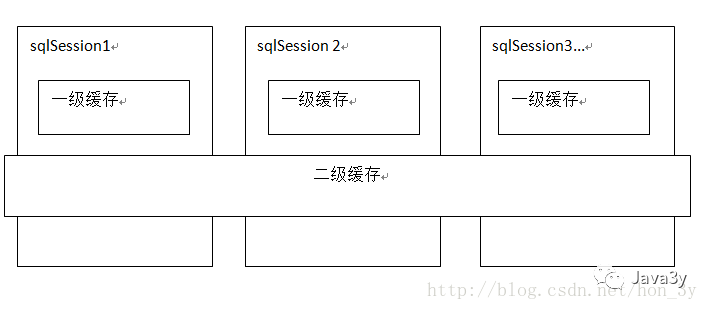
- mybatis一级缓存是一个SqlSession级别,sqlsession只能访问自己的一级缓存的数据
- 二级缓存是跨sqlSession,是mapper级别的缓存,对于mapper级别的缓存不同的sqlsession是可以共享的。
一级查询缓存
一级查询存在于每一个 SqlSession 类的实例对象中,当第一次查询某一个数据时,SqlSession 类的实例对象会将该数据存入一级缓存区域,在没有收到改变该数据的请求之前,用户再次查询该数据,都会从缓存中获取该数据,而不是再次连接数据库进行查询。
- MyBatis 的一级缓存原理:
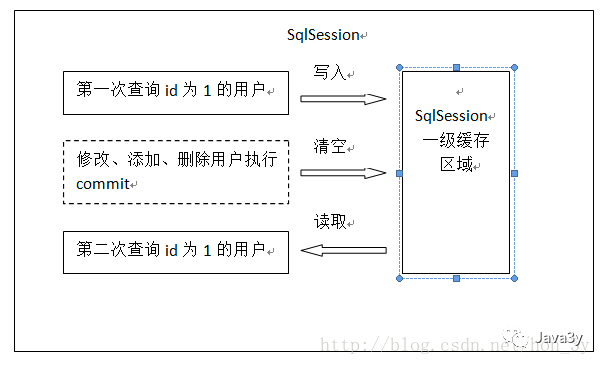
第一次发出一个查询 sql,sql 查询结果写入 sqlsession 的一级缓存中,缓存使用的数据结构是一个 map
- key:hashcode+sql+sql输入参数+输出参数(sql的唯一标识)
- value:用户信息
同一个 sqlsession 再次发出相同的 sql,就从缓存中取不走数据库。如果两次中间出现 commit 操作(修改、添加、删除),本 sqlsession 中的一级缓存区域全部清空,下次再去缓存中查询不到所以要从数据库查询,从数据库查询到再写入缓存。
一级缓存示例
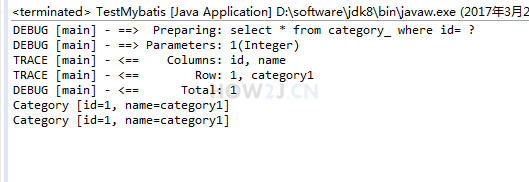
- 我们在同一个 session 中查询两次 id = 1 的 Category 对象试一试:
public static void main(String[] args) throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession session1 = sqlSessionFactory.openSession();
Category c1 = session1.selectOne("getCategory", 1);
System.out.println(c1);
Category c2 = session1.selectOne("getCategory", 1);
System.out.println(c2);
session1.commit();
session1.close();
}
运行,可以看到第一次会去数据库中取数据,但是第二次就不会访问数据库了,而是直接从session中取出来:
- 我们再来测试一下在不同 session 里查询相同的 id 数据
public static void main(String[] args) throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession session1 = sqlSessionFactory.openSession();
Category c1 = session1.selectOne("getCategory", 1);
System.out.println(c1);
Category c2 = session1.selectOne("getCategory", 1);
System.out.println(c2);
session1.commit();
session1.close();
SqlSession session2 = sqlSessionFactory.openSession();
Category c3 = session2.selectOne("getCategory", 1);
System.out.println(c3);
session2.commit();
session2.close();
}
这一次,另外打开一个 session , 取同样 id 的数据,就会发现需要执行 sql 语句,证实了一级缓存是在 session 里的:
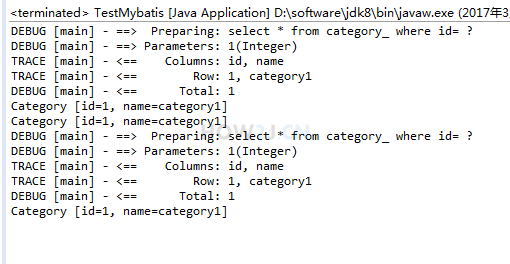
MyBatis 一级缓存值得注意的地方:
- MyBatis 默认就是支持一级缓存的,并不需要我们配置.
- MyBatis 和 spring 整合后进行 mapper 代理开发,不支持一级缓存,mybatis和 spring 整合,spring 按照 mapper 的模板去生成 mapper 代理对象,模板中在最后统一关闭 sqlsession。
二级查询缓存
-
问题: 有些时候,在 Web 工程中会将执行查询操作的方法封装在某个 Service 方法中,当查询完一次后,Service 方法结束,此时 SqlSession 类的实例对象就会关闭,一级缓存就会被清空。
-
二级缓存原理:
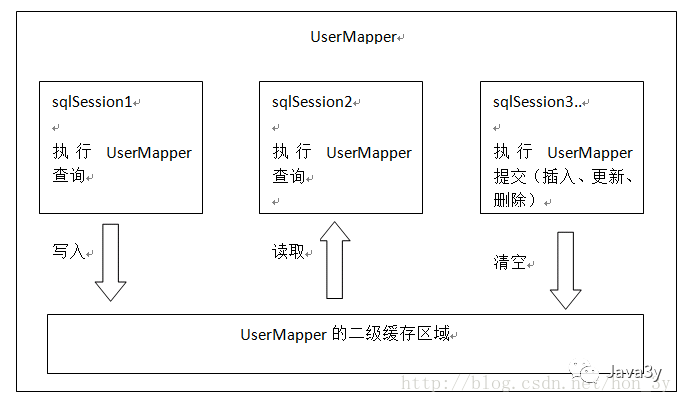
二级缓存的范围是 mapper 级别(mapper即同一个命名空间),mapper 以命名空间为单位创建缓存数据结构,结构是 map。
要开启二级缓存,需要进行两步操作。
第一步:在 MyBatis 的全局配置文件 mybatis-config.xml 中配置 setting 属性,设置名为 “cacheEnable” 的属性值为 “true” 即可:
<settings>
<!-- 开启二级缓存 -->
<setting name="cacheEnabled" value="true"/>
</settings>
- 注意: settings 配置的位置一定是在 properties 后面,typeAliases前面!
第二步:然后由于二级缓存是 Mapper 级别的,还要在需要开启二级缓存的具体 mapper.xml 文件中开启二级缓存,只需要在相应的 mapper.xml 中添加一个 cache 标签即可:
<!-- 开启本 Mapper 的 namespace 下的二级缓存 -->
<cache />
开启二级缓存之后,我们需要为查询结果映射的 POJO 类实现 java.io.serializable 接口,二级缓存可以将内存的数据写到磁盘,存在对象的序列化和反序列化,所以要实现java.io.serializable接口。
二级缓存示例
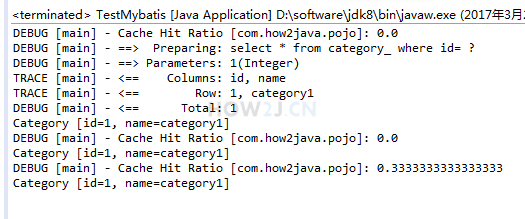
我们在同一个 SessionFactory 下查询 id = 1 的数据,只有第一次需要执行 SQL 语句,从后都是从缓存中取出来的:
参考资料:
- 《Java EE 互联网轻量级框架整合开发》
- 《Spring MVC + MyBatis开发从入门到项目实战》
- How2j-MyBatis 系列教程
- 全能的百度和万能的大脑

 浙公网安备 33010602011771号
浙公网安备 33010602011771号