《机器学习实战》 | 第1章 机器学习基础
系列文章:《机器学习实战》学习笔记
这是《机器学习实战》的第一章,本章简要介绍了下什么是机器学习、机器学习的主要任务和本书中将要用到的Python语言。现在机器学习(Machine learning)与人工智能(Artificial intelligence)这么火,介绍机器学习的文章网上有很多,有很多已经写得相当好了,比如这篇:从机器学习谈起,值得好好看看。本文肯定不会介绍得那样全,只是讨论《机器学习实战》这本书中提到的一些机器学习基础知识。
机器学习能让我们自数据集中受到启发,换句话说,我们会利用计算机来彰显数据背后的真实含义。它既不是只会徒然模仿的机器人,也不是具有人类感情的仿生人。
现今,机器学习已应用于多个领域,远超出大多数人的想象——
- 搜索引擎结果排序
- 垃圾邮件过滤器
- 商品推荐
- 手写识别软件
- 贷款信用判定
- ……
一、何谓机器学习
简单来说,机器学习是一个从无序数据中提取有用信息的过程。它横跨计算机科学、工程技术和统计学等多个学科,需要多学科的知识。
互联网时代,人们制造、收集了大量的数据,如何从这些数据中抽取出有价值的信息是一个非常值得研究的课题。现在也是个“数据为王”的年代,各个公司都在疯狂得搜集用户数据,个人信息、使用习惯、搜索记录、观看记录甚至电子邮件内容……希望能从中发现用户的喜好,挖掘用户的需求。可谓谁拥有数据,谁就有下一个机会。然而光有这些数据是不够的,海量的数据已经超出了直接计算的可行性,想要从中高效地提取信息就需要专门的学习算法,这就是机器学习的作用所在。我们需要机器学习算法,避免我们“迷失”在数据中,而找到更多的可用信息。
1.机器学习与统计学
顺便说一句,机器学习同统计学有着很深的渊源。在计算机出现以前,统计学家早就做着分析、预测的工作。机器学习可以说是计算机科学同统计学的一个结合点,利用计算机工具将统计学理论转化为代码,应用在了更多领域。而机器学习和统计学现在也有一些区别,这也不单是理论与应用的问题,还有一些不同的关注点和侧重点。关于这方面的讨论也有很多可读的文章:
- 机器学习专家与统计学家观点上有哪些不同? - 知乎
- 人工智能机器学习统计学数据挖掘之间有什么区别? - 博客 - 伯乐在线
- Data Science, Machine Learning, and Statistics: what is in a name? | Win-Vector Blog
- What is the difference between statistics and machine learning? - Quora
2.关键术语
书中使用了一个简单的“鸟类分类系统”作为切入点,介绍了机器学习算法中常用到的基本术语。这个系统用到的鸟物种分类表如下:
| 序号 | 体重(克) | 翼展(厘米) | 脚蹼 | 后背颜色 | 种属 |
|---|---|---|---|---|---|
| 1 | 1000.1 | 125.0 | 无 | 棕色 | 红尾鵟 |
| 2 | 3000.7 | 200.0 | 无 | 灰色 | 鹭鹰 |
| 3 | 3300.0 | 220.3 | 无 | 灰色 | 鹭鹰 |
| 4 | 4100.0 | 136.0 | 有 | 黑色 | 普通潜鸟 |
| 5 | 3.0 | 11.0 | 无 | 绿色 | 瑰丽蜂鸟 |
| 6 | 570.0 | 75.0 | 无 | 黑色 | 象牙喙啄木鸟 |
我们称其为一个专家系统,因为它可以像一个研究鸟类的专家一样识别鸟类的种属。表中使用了四种不同的属性值来区分不同鸟类。现实中,你可能会想测量更多的值。通常的做法是测量所有可测属性,而后再挑选出重要部分。我们称使用的这四种属性为特征。 表中的每一行都是一个具有相关特征的实例或称样本。
-
特征数值的类型
表中的前两种特征是连续型(数值型)的,即它的取值是连续的实数;第三种特征是二值型的,只可以取是或否;第四种特征是基于有限颜色范围的枚举型。我们称二值型、枚举型这样只可以取有限个值的特征为离散型(标称型)的。
-
机器学习的任务——分类
鸟类分类系统完成的是一个分类任务。这很好理解,因为这个系统要做的事是分给未知的(鸟类)样本一个已知的种类。
-
机器学习算法的流程
我们首先要做的是算法训练,即学习如何分类。即为算法输入大量已分类数据作为算法的训练集。训练集是用于训练机器学习算法的数据样本集合。表中即包含六个训练样本的训练集。每个训练样本有若干个特征(本例为4个)和一个目标变量(表示样本所属的类别)。目标变量是机器学习算法的预测结果,在分类算法中目标变量的类型通常是标称型的。我们通常将分类问题中的目标变量称为类别,并假定分类问题只存在有限个数的类别。
为了测试机器学习算法的效果,通常将现有数据分为两套独立的数据集:训练数据和测试数据。当机器学习程序开始运行时,使用训练样本作为算法的输入,训练完成之后输入测试样本。输入测试样本时并不提供测试样本的目标变量,而是由程序决定样本的类别。通过比较程序预测的样本类别与实际样本类别(目标变量)之间的差异,就可以得出算法的实际精确度。
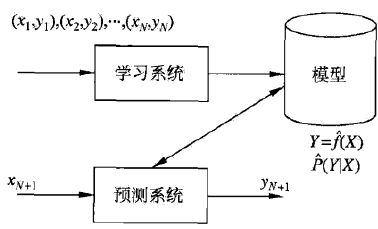
我们称算法输出的结果为模型。经过训练、测试准确率良好的模型就可以被保存下来,用于对未知的鸟类样本分类。
废了半天话,是时候祭出这张经典的流程图了(图自李航《统计学习方法》):
-
机器学习的其他任务
机器学习的另一项任务是回归,它主要用于预测数值型数据。一个很经典的例子就是统计学中的数据拟合曲线:给定数据点,计算最优拟合曲线,目标变量即这条曲线的参数。
分类和回归均属于监督学习(Supervised learning),即这类算法知道预测什么(存在目标变量)。
与之对应的是无监督学习(Unsupervised learning),此时数据没有类别信息,也不会给定目标值。在无监督学习中,将数据集合分成由类似的对象组成的多个类的过程被称为聚类;将寻找描述数据统计值的过程称之为密度估计。此外,还包括减少数据特征的维度的算法,被称为降维。
二、寻找合适的机器学习算法
为一个实际问题应用机器学习算法时,可以从如下方面分别考虑:
-
使用机器学习算法的目的(目标任务)。如果已有部分样本和目标变量,想要预测未知样本的目标变量的值,则可以选择监督学习算法——根据目标变量的类型可以进一步分为分类算法(对离散型目标变量)和回归算法(对连续型目标变量)。如果没有或不存在样本类型信息,则可以选择无监督学习算法——使用聚类算法将数据划分为若干类;使用密度估计算法估计数据与每个分类的相似度(匹配度)。
-
其次需要考虑的是数据问题。我们应该充分了解数据的特性,没有统一的学习算法,(任何问题)都需要根据具体的数据做相应处理。需要考虑的问题有——数据的特征数量,特征值是离线型变量还是连续型变量,特征值的取值范围,特征值的分布(是否分布不均、有些值很少出现),特征值中是否存在缺失的值,造成缺失的原因,数据中是否存在异常的值(数据是否完全可信),等等。
-
多次试验。一般并不存在最好的算法,尝试不同算法的执行效果,比较其准确率、计算时间,综合决定最终使用的机器学习算法。
三、开发机器学习应用程序的步骤
- 收集数据。有很多方法收集样本数据,如:制作网络爬虫从网站上抽取数据、从API中得到信息、设备传感器发来的实测数据等等。
- 准备输入数据。将数据转换为计算机可处理的格式,如将离散数据转换为整数值、填充缺失数据为特定的值。
- 分析输入数据。如果数据的特征值低于三维,可以将这些数据点绘制出来,人工分析数据的特征,看是否有明显的分布模式、是否存在明显的异常值。对于大于三维的数据,可以使用降维的方法压缩到三维以下,方便我们图形化展示数据。这一步的主要作用是确保没有垃圾数据,否则将降低算法性能。
- 训练算法。机器学习算法从这一步才真正开始学习。对于无监督学习,因为不存在目标变量值,故不需要训练算法,所有的算法集中在第五步。
- 测试算法。对于监督学习,在测试的步骤使用测试数据检测算法的准确率(性能);对于无监督学习,运行机器学习算法,并使用其它方式检验算法性能。
- 使用算法。将机器学习算法转换为应用程序,执行实际任务,以检验上述步骤是否可以在实际环境中正常工作。
四、使用Python语言实现机器学习算法
本书中使用Python语言编写实际代码。Python语言具有很多优点(清晰的语法结构、可读性、丰富的函数库、高级的语法特性……),使其很适合用来实现机器学习算法。但是性能问题始终是Python语言最大的问题。由于它是一门解释性语言,始终过不了性能这道坎儿。对此,可以使用PyPy这类带有JIT的Python发行版,但是追求性能的场合终究还是逃不掉C和C++的。
——没关系,把Python作为机器学习的教学语言还是足够的。
书中的附录部分有简单介绍Python的语法,在本文中再写这些就没意思了。Python的入门门槛很低,网上有很多优秀的教程可供参考(比如这个:简明Python教程)。
书中广泛使用了Python的一个函数库:NumPy,这个可谓Python做线性代数运算的必备函数库,广泛应用于不仅机器学习的各个数学计算领域。
在这里假设已经安装了Python开发环境和NumPy函数库。
在Python shell中输入下列命令,将NumPy函数库中的所有模块导入当前的命名空间:
from numpy import *
生成一个4x4的随机数组(array):
random.rand(4,4)
可见其数据类型为array,这是NumPy中的两大主要类型之一。
将数组转换为矩阵:
randMat = mat(random.rand(4,4))
可见其数据类型为mat,这是NumPy中的另一个主要类型。
矩阵求逆:
invRandMat = randMat.I
矩阵乘法:
randMat * invRandMat
获得一个4x4单位矩阵:
myEye = eye(4)
学习资源汇总
博客文章:《从机器学习谈起》、《Brief History of Machine Learning》
书籍:李航《统计学习方法》
在线学习资源:Coursera公开课 - Machine Learning、Coursera公开课 - 機器學習基石 (Machine Learning Foundations)(中文的哦),这两个课程的老师分别是Andrew Ng和林軒田,也都是这个领域的大牛。
Python在线学习资源:简明Python教程
以及隆重推荐这位大神的博客:
