
【网络爬虫学习】Python 爬虫初步
本系列基于 C语言中文网的 Python爬虫教程(从入门到精通)来进行学习的,
部分转载的文章内容仅作学习使用!
前言
网络爬虫又称网络蜘蛛、网络机器人,它是一种按照一定的规则自动浏览、检索网页信息的程序或者脚本。网络爬虫能够自动请求网页,并将所需要的数据抓取下来。通过对抓取的数据进行处理,从而提取出有价值的信息。
但要注意:爬虫是一把双刃剑
爬虫是一把双刃剑,它给我们带来便利的同时,也给网络安全带来了隐患。有些不法分子利用爬虫在网络上非法搜集网民信息,或者利用爬虫恶意攻击他人网站,从而导致网站瘫痪的严重后果。关于爬虫的如何合法使用,推荐阅读《中华人民共和国网络安全法》。

并且为了限制爬虫带来的危险,大多数网站都有良好的反爬措施,并通过 robots.txt 协议做了进一步说明,下面是淘宝网 robots.txt 的内容:
User-agent: Baiduspider
Disallow: /baidu Disallow: /s?
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
.....
User-agent: *
Disallow: /
从协议内容可以看出,淘宝网对不能被抓取的页面做了规定。因此大家在使用爬虫的时候,要自觉遵守 robots 协议,不要非法获取他人信息,或者做一些危害他人网站的事情。
为什么用Python做爬虫
首先应该明确,不止 Python 这一种语言可以做爬虫,诸如 PHP、Java、C/C++ 都可以用来写爬虫程序,但是相比较而言 Python 做爬虫是最简单的(开发效率较高并且支持多个爬虫模块)。
所以推荐学习 “网络爬虫” 时使用 Python。
编写爬虫的流程
爬虫程序与其他程序不同,它的的思维逻辑一般都是相似的, 所以无需我们在逻辑方面花费大量的时间。下面对 Python 编写爬虫程序的流程做简单地说明:
- 先由
urllib模块的request方法打开 URL 得到网页 HTML 对象。 - 使用浏览器打开网页源代码分析网页结构以及元素节点。
- 通过
Beautiful Soup或则正则表达式提取数据。 - 存储数据到本地磁盘或数据库。
当然也不局限于上述一种流程。编写爬虫程序,需要您具备较好的 Python 编程功底,这样在编写的过程中您才会得心应手。爬虫程序需要尽量伪装成人访问网站的样子,而非机器访问,否则就会被网站的反爬策略限制,甚至直接封杀 IP,相关知识会在后续内容介绍。
学习Python爬虫前的准备工作(知识准备)
在使用 Python 编写爬虫程序之前,建议需要提前做一些准备工作,这样在后续学习过程中才会得心应手。
1) Python语言
Python 爬虫作为 Python 编程的进阶知识,要求学习者具备较好的 Python 编程基础。
同时,了解 Python 语言的多进程与多线程(参考《Python并发编程》),并熟悉正则表达式语法,也有助于您编写爬虫程序。
注意:关于正则表达式,Python 提供了专门的 re 模块。
2) Web前端
了解 Web 前端的基本知识,比如 HTML、CSS、JavaScript,这能够帮助你分析网页结构,提炼出有效信息。推荐阅读《HTML入门教程》、《CSS教程》、《JS入门教程》。
3) HTTP协议
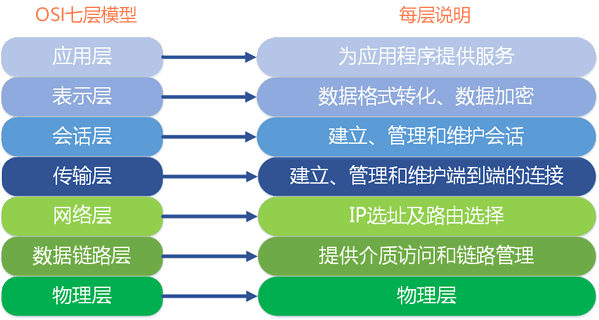
掌握 OSI 七层网络模型,了解 TCP/IP 协议、HTTP 协议,这些知识将帮助您了解网络请求(GET 请求、POST 请求)和网络传输的基本原理。同时,也有助您了解爬虫程序的编写逻辑,这里推荐阅读《TCP/IP协议入门教程》。
4)环境准备
编写 Python 爬虫程序前,需要准备相应的开发环境,这非常的简单。首先您需要在您的电脑上安装 Python,然后下载安装 Pycharm IDE(集成开发环境)工具。
建议使用 Python 3.5 后的版本(含 3.5 版本)


· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· Obsidian + DeepSeek:免费 AI 助力你的知识管理,让你的笔记飞起来!
· 分享4款.NET开源、免费、实用的商城系统
· 解决跨域问题的这6种方案,真香!
· 一套基于 Material Design 规范实现的 Blazor 和 Razor 通用组件库
· 5. Nginx 负载均衡配置案例(附有详细截图说明++)