
Codeforces Round #739 (Div. 3) 个人题解(A~F2)
比赛链接:Here
1560A. Dislike of Threes
Description
找出第
直接枚举出前 1000 个符合条件的数,然后输出
int main() {
cin.tie(nullptr)->sync_with_stdio(false);
vector<int>a;
int i = 1;
while (a.size() != 1000) {
if (i % 3 != 0 && i % 10 != 3) a.push_back(i);
i += 1;
}
int _; for (cin >> _; _--;) {
int n; cin >> n;
cout << a[n - 1] << "\n";
}
}
1560B. Who's Opposite?
Description
一些人均匀站成一圈,每人的编号从
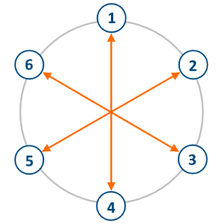
通过样图容易发现对位的编号差的两倍即
当然注意边界
int main() {
cin.tie(nullptr)->sync_with_stdio(false);
int _; for (cin >> _; _--;) {
int a, b, c; cin >> a >> b >> c;
int n = 2 * abs(a - b);
if (a > n || b > n || c > n) {cout << "-1\n"; continue;}
cout << (n / 2 + c - 1) % n + 1 << "\n";
}
}
1560C. Infinity Table
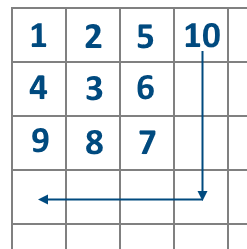
题意:给定
好明显的规律题?但赛时没想太多,跑了暴力
- 先找到第
- 因为
TLE
void solve() {
ll x; cin >> x;
ll i = 1;
while (i * i < x) i++;
ll j = i - 1;
ll tmp = x - j * j;
if (tmp <= i) cout << tmp << " " << i << endl;
else {
int t = i * i - x;
cout << i << " " << t + 1 << endl;
}
}
1560D. Make a Power of Two
D题开始搞自己了,
给定一个整数
- 删除
- 在最右边加一位(可以是
请问最少的操作数使得
这很明显
相同类型:AcWing 3796. 凑平方
来自群友的详细思路,From 群友d3ac
题目关键信息: 随便删除,只能在右边加,前导零不自动删除
- 因为要看看到底操作几次就可以变得和
相等,拿到题我们就先想暴力一点的做法,判断时间复杂度,再考虑优化.所以最暴力的就是直接枚举 ,再与 来作比较,看看需要操作几次 - 计算时间复杂度:
< ,所以行. - 然后再来考虑怎么把
与 进行比较,来计算需要几个操作,这个其实就是字符串匹配,将 来匹配原来的 ,因为只能从左边添加字符,假设 所以 中必须是有从 到 连续且有顺序排列的才行,举个例子: ,匹配成功了 个, ,匹配成功 个,因为必须要删除完所有的才能加入 . - 再考虑一点小小的优化和怎么写才好写
- 将
预处理出来,放在一个数组里面方便每次用,减少时间复杂度. - 将
和 都转换为字符串,方便处理. - 设
的字符串下长度为 ,匹配成功了 个(注意, 指向的是下一个位置,所以要 ),当前 的长度是 .最终的答案就是 ,其中 是 需要添加的, 是需要删除的. 注意:需要枚举到
才行
int main() {
cin.tie(nullptr)->sync_with_stdio(false);
int _; for (cin >> _; _--;) {
string s; cin >> s;
int ans = 1e9;
for (int i = 0; i < 64; ++i) {
string t = to_string(1ull << i);
int k = 0;
for (int j = 0; j < int(s.size()); ++j)
if (k < int(t.size()) && s[j] == t[k]) k += 1;
ans = min(ans, int(s.size() + int(t.size()) - 2 * k));
}
cout << ans << '\n';
}
}
1560E. Polycarp and String Transformation
From 群友d3ac
首先思考一下给出的字符串那么长,到底该怎么去分割开,要是分割开,那就爽歪歪.
- 以
为例子 - 正常分割
所以不难看到,要想把他分出来还是有点难度的,但是每次会删除一个字符,我们再倒过来看看,先是只有一种字母,然后再是只有两种字符……有全部的字母,所以我们倒序枚举,从字符串的末尾开始向头开始枚举的话,就可以找到删除的顺序,因为后删除的字符肯定在后面还会出现的,而先删除的字符就只会在前面,会后被枚举到,因此,我们找到了删除的顺序
再来考虑原字符串是什么,先这样,我们统计一下每个字母在大字符串出现了多少次,结果是这样的:
, , , , , . 每个字符在每次轮回的时候出现次数都是一样的,在删除了它之前是一个特定值
,删除后就是 ,所以我们将所有的字符出现次数除上它是第几个被删除掉的,结果就是这样了
, , , , , 然而母串,也就是原字符串中,每个字母出现次数也是也么多次.
至此,我们已经求出了字符串和顺序,要考虑
就简单了,就是模拟题目所说过程,用我们得到的字符串去看,行不行就好了 注意:要memset 反例:aaabbb
int main() {
cin.tie(nullptr)->sync_with_stdio(false);
int _; for (cin >> _; _--;) {
string t; cin >> t;
reverse(t.begin(), t.end());
map<char, int> freq;
string ord;
for (char c : t) {
if (!freq[c]) ord += c;
freq[c] += 1;
}
int n = int(ord.length());
int len = 0;
for (int i = 0; i < n; ++i) len += freq[ord[i]] / (n - i);
reverse(t.begin(), t.end());
if (len > t.size()) {
cout << "-1\n";
continue;
}
string s = t.substr(0, len);
reverse(ord.begin(), ord.end());
string reals = s;
string fin = "";
for (char c : ord) {
fin += s;
string news ;
for (char d : s)
if (d != c) news += d;
s = news;
}
if (fin == t) cout << reals << " " << ord << "\n";
else cout << "-1\n";
}
}
1560F2. Nearest Beautiful Number (hard version)
翻译一下官方题解(官方题解解释的很清楚,好评)
假设数字 1-beautiful,而任何 1-beautiful 数字同时是 k-beautiful,所以
因为我们要寻找最小的
我们找出包含不超过 k-beautiful 的了,直接输出即可。 否则,让我们像数字一样将前缀增加
具体可以再参考代码理解
- 时间复杂度:
void solve() {
string s;
int k;
cin >> s >> k;
while (true) {
set<char> cs;
for (auto c : s) cs.insert(c);
if (cs.size() <= k) {cout << s << "\n"; return ;}
cs.clear();
int lst = 0;
for (;; lst++) {
cs.insert(s[lst]);
if (cs.size() > k) {
while (s[lst] == '9') lst -= 1;
s[lst]++;
for (int i = lst + 1; i < s.size(); ++i) s[i] = '0';
break;
}
}
}
}
JLY 关于F1的代码:Here


· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· Obsidian + DeepSeek:免费 AI 助力你的知识管理,让你的笔记飞起来!
· 分享4款.NET开源、免费、实用的商城系统
· 解决跨域问题的这6种方案,真香!
· 一套基于 Material Design 规范实现的 Blazor 和 Razor 通用组件库
· 5. Nginx 负载均衡配置案例(附有详细截图说明++)
2020-08-19 A*(A star)搜索总结
2020-08-19 Codeforces Round #629 (Div. 3) & 19级暑假第六场训练赛
2020-08-19 线性代数(1):矩阵以及运用
2020-08-19 __builtin_popcount() 函数
2020-08-19 【洛谷日报#26】GCC自带位运算系列函数