
AtCoder Beginner Contest 214 (D并查集,E反悔贪心,F公共子序列DP)
题目链接:Here
ABC水题,
D - Sum of Maximum Weights
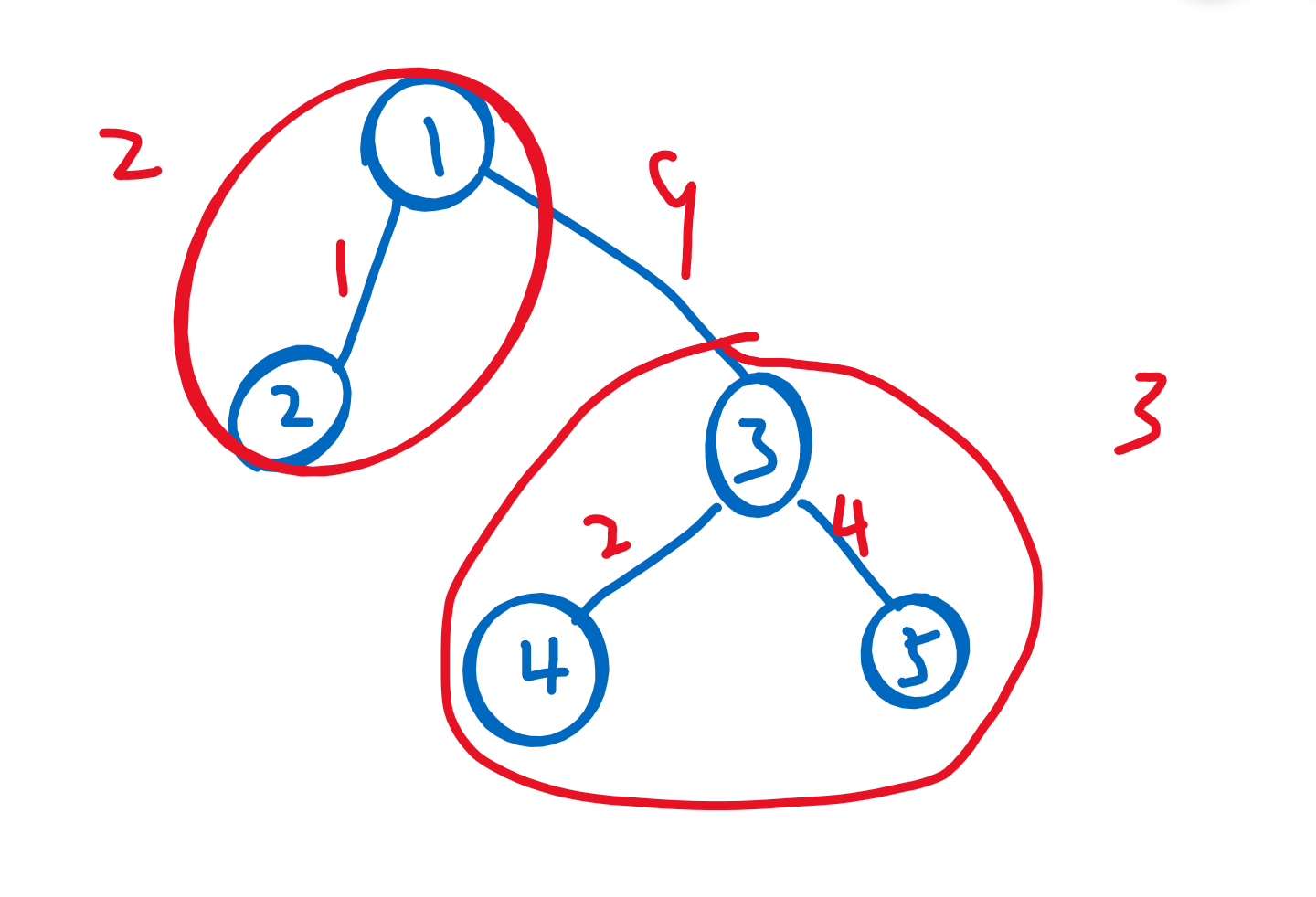
上图中最大权
受到上面的启发,我们可以把每条边按边权大小从小到大排序。对于每条边(边权记为
这里偷懒用一下 atcoder 的库函数写。
#include <bits/stdc++.h>
#include <atcoder/all>
using namespace std;
using namespace atcoder;
int main() {
int n;
cin >> n;
vector<tuple<long long, int, int>> p(n - 1);
for (auto &[w, u, v] : p) {
cin >> u >> v >> w;
u--; v--;
}
sort(p.begin(), p.end());
long long ans = 0;
dsu uf(n);
for (auto [w, u, v] : p) {
if (!uf.same(u, v)) {
ans += w * uf.size(u) * uf.size(v);
uf.merge(u, v);
}
}
cout << ans << endl;
return 0;
}
E - Packing Under Range Regulations
题意理解来自 Ncik桑
本题显然是区间调度问题(反悔贪心问题),和以下问题等价:
- 有
显而易见的,我们应该从最紧急的工作开始,即把任务按
const int inf = 1001001001;
void solve() {
int n; cin >> n;
vector<pair<int, int>> a(n);
for (auto &[u, v] : a) cin >> u >> v;
sort(a.begin(), a.end());
priority_queue<int, vector<int>, greater<int>>q;
int x = 1;
a.push_back({inf, inf});
for (auto [l, r] : a) {
while (x < l && q.size()) {
if (q.top() < x) {
cout << "No\n";
return ;
}
q.pop(); x += 1;
}
x = l; q.push(r);
}
cout << "Yes\n";
}
F - Substrings
首先,让我们考虑不受相邻字符不同时选择的约束的问题。
查找S的非空子字符串的数目。在这里,子字符串是在删除0个或更多字符的情况下不重新排序原始字符串的串联。
在这里,重要的是不同的删除方式可能会导致相同的子字符串。这里会用“公共子序列DP”的方法解决问题,在该方法中,子字符串的计数不包含那些重复项。
考虑下面的DP。
考虑下面的DP
定义
但可能会多次计算相同子字符串,所以稍微修改一下
直观地说,如果
乍一看,复杂度看起来像
这个想法也可以应用于原始问题。设
递归关系可以写成:
const int mod = 1e9 + 7;
int main() {
cin.tie(nullptr)->sync_with_stdio(false);
string s; cin >> s;
int n = s.size();
vector<ll> f(n + 2); f[0] = 1;
for (int i = 0; i < n; ++i)
for (int j = i - 1;; j--) {
f[i + 2] = (f[i + 2] + f[j + 1]) % mod;
if (j == -1 || s[j] == s[i]) break;
}
ll ans = 0;
for (int i = 2; i < n + 2; i++) ans += f[i];
cout << ans % mod << "\n";
}
分类:
刷题笔记: AtCoder


· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· Obsidian + DeepSeek:免费 AI 助力你的知识管理,让你的笔记飞起来!
· 分享4款.NET开源、免费、实用的商城系统
· 解决跨域问题的这6种方案,真香!
· 一套基于 Material Design 规范实现的 Blazor 和 Razor 通用组件库
· 5. Nginx 负载均衡配置案例(附有详细截图说明++)
2020-08-15 网络流(2):最大流
2020-08-15 网络流 24 题
2020-08-15 CH#17C 舞动的夜晚(最大流+强连通分量)
2020-08-15 acwing算法提高课程笔记—数字三角形模型,最长上升子序列模型
2020-08-15 Educational Codeforces Round 93 (Rated for Div. 2)