
【矩阵性质】矩阵加速递推
本文介绍线性代数中一个非常重要的内容——矩阵(Matrix)的一个重要性质:矩阵加速递推
同时本文已经更新至:矩阵(Matrix)系统介绍篇
斐波那契数列(Fibonacci Sequence)大家应该都非常的熟悉了。在斐波那契数列当中,
如果有一道题目让你求斐波那契数列第
设
试推导一个矩阵
怎么推呢?因为
综上所述:
转化为代码,应该怎么求呢?
定义初始矩阵
注意,矩阵乘法不满足交换律,所以一定不能写成
为什么要乘上
下面是求斐波那契数列第
const int mod = 1000000007;
struct Matrix {
int a[3][3];
Matrix() { memset(a, 0, sizeof a); }
Matrix operator*(const Matrix &b) const {
Matrix res;
for (int i = 1; i <= 2; ++i)
for (int j = 1; j <= 2; ++j)
for (int k = 1; k <= 2; ++k)
res.a[i][j] = (res.a[i][j] + a[i][k] * b.a[k][j]) % mod;
return res;
}
} ans, base;
void init() {
base.a[1][1] = base.a[1][2] = base.a[2][1] = 1;
ans.a[1][1] = ans.a[1][2] = 1;
}
void qpow(int b) {
while (b) {
if (b & 1) ans = ans * base;
base = base * base;
b >>= 1;
}
}
int main() {
int n = read();
if (n <= 2) return puts("1"), 0;
init();
qpow(n - 2);
println(ans.a[1][1] % mod);
}
这是一个稍微复杂一些的例子。
我们发现,
但是发现如果矩阵仅有这三个元素
于是考虑构造一个更大的矩阵。
我们希望构造一个递推矩阵可以转移到
转移矩阵即为
有了上面的基础能很快做出 又见斐波那契
图源来自网络上一位博主
这个相比普通的斐波那契数列多了后面四项,看一眼数据范围,使用普通的
因此这里需要使用矩阵快速幂(斐波那契数列的项数n一旦过大,就要考虑快速幂,普通算法时间空间都开销太大)。
使用矩阵快速幂的一个关键问题就是矩阵递推式。
参考普通快速幂那一片博客最后面的那个扩展式,就可以得到下面这个递推式了:
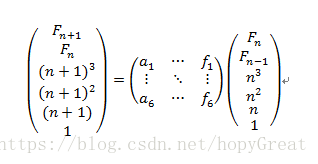
然后通过计算等价替换可得出该矩阵A:

下面只需要把普通斐波那契数列的构造由2*2的矩阵换为6*6的即可。
using ll = long long;
const int mod = 1e9 + 7;
const int N = 6;
ll tmp[N][N], res[N][N];
ll n;
void mul(ll a[][N], ll b[][N]) {
memset(tmp, 0, sizeof(tmp));
for (int i = 0; i < N; ++i)
for (int j = 0; j < N; ++j)
for (int k = 0; k < N; ++k) {
tmp[i][j] += a[i][k] * b[k][j] % mod;
if (tmp[i][j] >= mod) tmp[i][j] -= mod;
}
for (int i = 0; i < N; ++i)
for (int j = 0; j < N; ++j)a[i][j] = tmp[i][j];
}
void pow(ll a[][N]) {
memset(res, 0, sizeof(res));
for (int i = 0; i < N; ++i)res[i][i] = 1;
for (; n; n >>= 1) {
if (n & 1)mul(res, a);
mul(a, a);
}
}
void solve() {
cin >> n, n--;
ll ans[N][N] = { 1, 1, 1, 1, 1, 1,
1, 0, 0, 0, 0, 0,
0, 0, 1, 3, 3, 1,
0, 0, 0, 1, 2, 1,
0, 0, 0, 0, 1, 1,
0, 0, 0, 0, 0, 1
};
pow(ans);
ll sum = 0;
ll x[N] = {1, 0, 8, 4, 2, 1};
for (int i = 0; i < N; ++i) {
sum += (res[0][i] * x[i]) % mod;
if (sum >= mod) sum -= mod;
}
cout << sum << "\n";
}


· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· Obsidian + DeepSeek:免费 AI 助力你的知识管理,让你的笔记飞起来!
· 分享4款.NET开源、免费、实用的商城系统
· 解决跨域问题的这6种方案,真香!
· 一套基于 Material Design 规范实现的 Blazor 和 Razor 通用组件库
· 5. Nginx 负载均衡配置案例(附有详细截图说明++)