
排序算法总结
冒泡排序(BubbleSort)
-
基本思想:两个数比较大小,较大的数下沉,较小的数冒起来。
-
过程:
- 比较相邻的两个数据,如果第二个数小,就交换位置。
- 从后向前两两比较,一直到比较最前两个数据。最终最小数被交换到起始的位置,这样第一个最小数的位置就排好了。
- 继续重复上述过程,依次将第2.3...n-1个最小数排好位置。
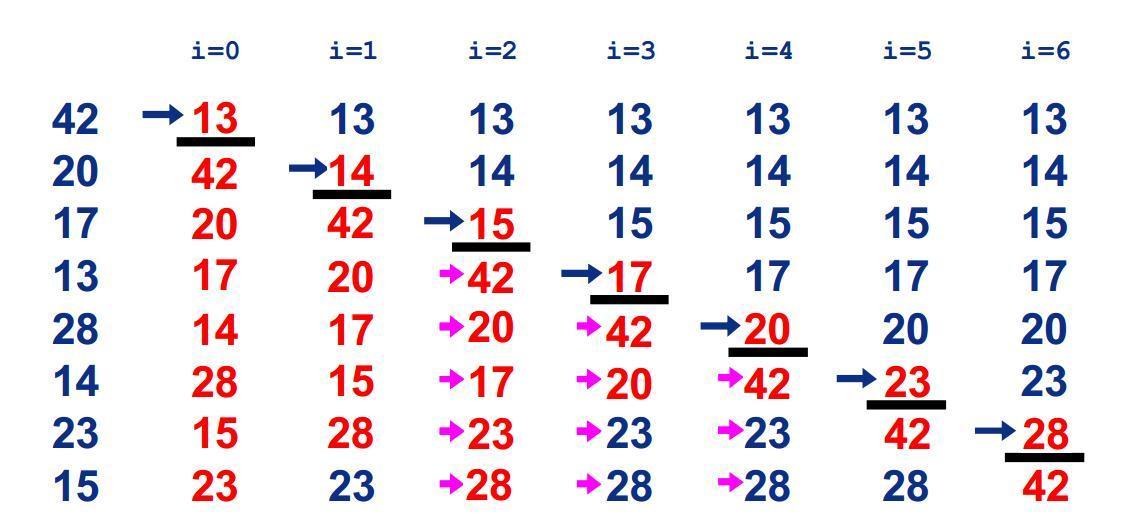
以下图示
 undefinedundefined
undefinedundefined平均时间复杂度:O(n2)
代码实现
void Bubble_Sort(vector<int>& arr, int n) {
if (n == 0)return;
for (int i = 0; i < n - 1; ++i) {
bool flag = true;//flag作为标记,如果仍是true的话说明已经排序了直接结束
for (int j = n - 1; j > i; --j) {
if (arr[j - 1] > arr[j]) {
swap(arr[j - 1], arr[j]);
flag = false;
}
}
if (flag)return;
}
}
插入排序(Insertion Sort)
基本思想:
在要排序的一组数中,假定前n-1个数已经排好序,现在将第n个数插到前面的有序数列中,使得这n个数也是排好顺序的。如此反复循环,直到全部排好顺序。
插入排序很像放入扑克牌
过程:
代码实现:
void insertion_sort(int arr[], int len) {
for (int i = 1; i < len; i++) {
int key = arr[i];
int j = i - 1;
while ((j >= 0) && (key < arr[j])) {
arr[j + 1] = arr[j];
--j;
}
arr[j + 1] = key;
}
}
从第一个元素开始,该元素可以认为已经被排序
取出下一个元素,在已经排序的元素序列中从后向前扫描
如果该元素(已排序)大于新元素,将该元素移到下一位置
重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
将新元素插入到该位置后
重复步骤2~5
可以采用二分查找法来减少“比较操作”的数目,而由于“交换操作”的数目不变,算法的时间复杂度依旧为
优化Code:
void HinsertSort(int nums[], int n) {
int low, high, mid;
for (int i = 0; i < n; ++i) {
int tmp = nums[i];
low = 0;
high = i - 1;
//采用折半查找法判断插入位置,最终变量 left表示插入位置
while (low <= high) {
mid = low + (low + high) >> 1;
if (nums[mid] > tmp)
high = mid - 1;
else
low = mid + 1;
}
//有序表中插入位置后的元素统一后移
for (int j = i - 1; j >= high +1; --j) {
nums[j + 1] = nums[j];
}
nums[high + 1] = tmp;//插入元素
}
}
希尔排序(Shell Sort)
希尔排序(Shell Sort),也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到
线性排序的效率 - 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位

实现代码:
void ShellSort(vector<int>&nums, int n) {
for (int dk = n / 2; dk >= 1; dk>>=1) {
for (int i = dk; i < n; ++i) {
if (nums[i] < nums[i - dk]) {
int temp = nums[i], j;
for (j = i - dk; j >= 0 && temp < nums[j]; j -= dk) {
nums[j + dk] = nums[j];
}
nums[j + dk] = temp;
}
}
}
}
快速排序(Quicksort)
基本思想:(分治)
- 先从数列中取出一个数作为key值(哨点);
- 将比这个数小的数全部放在它的左边,大于或等于它的数全部放在它的右边;
- 对左右两个小数列重复第二步,直至各区间只有1个数。
辅助理解:挖坑填数
举个例子
如无序数组[6 2 4 1 5 9]
a),先把第一项[6]取出来,
用[6]依次与其余项进行比较,
如果比[6]小就放[6]前边,2 4 1 5都比[6]小,所以全部放到[6]前边
如果比[6]大就放[6]后边,9比[6]大,放到[6]后边,//6出列后大喝一声,比我小的站前边,比我大的站后边,行动吧!霸气十足~
一趟排完后变成下边这样:
排序前 6 2 4 1 5 9
排序后 2 4 1 5 6 9
b),对前半拉[2 4 1 5]继续进行快速排序
重复步骤a)后变成下边这样:
排序前 2 4 1 5
排序后 1 2 4 5
前半拉排序完成,总的排序也完成:
排序前:[6 2 4 1 5 9]
排序后:[1 2 4 5 6 9]
排序结束
实现代码:
void quicksort(vector<int>& a,int left, int right)
{
int i, j, t;
if (left > right)
return;//判断是否只剩下1个数字或者输入错误
t = a[left]; //t存储基准数
i = left;
j = right;
while (i != j)
{
//顺序很重要,要先右边开始找
while (a[j] >= t && i < j)
j--;
while (a[i] <= t && i < j)
i++;
if (i < j)//进行i,j两个哨兵对应值的交换
swap(a[i],a[j])
}
//最终将基准数归位
a[left] = a[i];
a[i] = t;
quicksort(left, i - 1);//继续处理左边的,利用递归
quicksort(i + 1, right);//继续处理右边的,利用递归
}
平均时间复杂度:
堆排序(HeapSort)
堆排序是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父节点。

实现代码:
#include<iostream>
using namespace std;
int h[101];//存储堆得数组
int n;//堆得大小
void swap(int x, int y) {
int t = h[x];
h[x] = h[y];
h[y] = t;
}
void sifdown(int i){ //传入一个需要向下调整得节点编号,这里传1,即从堆顶向下调整
int t;
bool flag = false;//flag标记是否需要往下调整
while (i * 2 <= n && flag == false) {
//先判断它和左儿子得关系,并t记录较大节点编号
if (h[i] < h[i * 2])
t = i * 2;
else
t = i;
//如果它有右儿子
if(i*2+1<=n)
if (h[t] < h[2 * i + 1])
t = i * 2 + 1;
//如果发现最大的节点编号不是自己说明子节点中有比父节点更大的
if (t != i) {
swap(t, i);//交换它们
i = t;//更新i为刚刚与它交换的儿子编号,编于下面向下调整
}
else
flag = true;//否则说明当前的父节点以及比两个子节点都大了,不用调整
}
}
void creat_heap() {//建堆函数
int i;
for (i = n / 2; i >= 1; i--)
sifdown(i);
}
void heapsort() {
while (n > 1) {
swap(1, n);
n--;
sifdown(1);
}
}
int main() {
int i, num;
cin >> num;
for (int i = 1; i <= num; ++i)
cin >> h[i];
n = num;
creat_heap();
heapsort();
for (int i = 1; i <= num; ++i)
cout << i << " ";
cout << endl;
return 0;
}
基数排序(RadixSort)
- 基本思想:
BinSort想法非常简单,首先创建数组A[MaxValue];然后将每个数放到相应的位置上(例如17放在下标17的数组位置);最后遍历数组,即为排序后的结果。 - 图示:
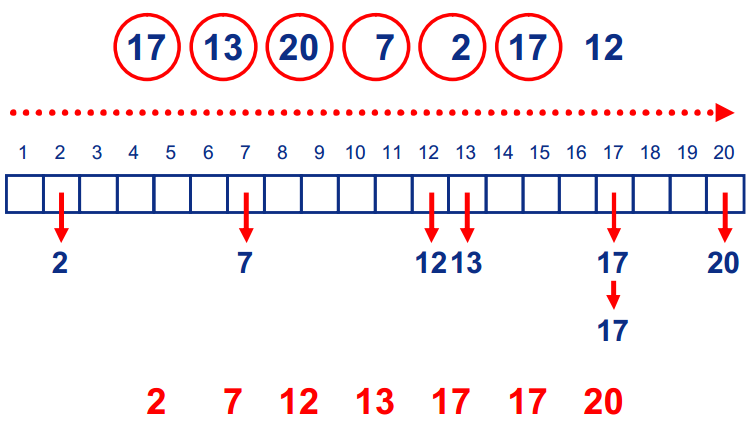
BinSort
- 问题: 当序列中存在较大值时,BinSort 的排序方法会浪费大量的空间开销。
RadixSort
- 基本思想: 基数排序是在BinSort的基础上,通过基数的限制来减少空间的开销。


· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· Obsidian + DeepSeek:免费 AI 助力你的知识管理,让你的笔记飞起来!
· 分享4款.NET开源、免费、实用的商城系统
· 解决跨域问题的这6种方案,真香!
· 一套基于 Material Design 规范实现的 Blazor 和 Razor 通用组件库
· 5. Nginx 负载均衡配置案例(附有详细截图说明++)