Spark入门系列教程一 —— Spark2.3.1 集群安装
2018-11-27 00:43 RingWu 阅读(1055) 评论(0) 收藏 举报有朋友希望我能教他们学大数据,其实我自己也很一般,所以计划写几篇博文,希望能够帮助到初学者
1.机器准备
1.1准备三台以上Linux服务器,安装好jdk,安装过程自行百度。
1.2 安装open-ssh并配置免密登录,安装过程自行百度。
1.3 执行 vi /etc/hosts 指令,修改/etc/hosts 文件,将服务器做如下的域名映射,方便后续的操作。
192.168.179.132 hdp-01
192.168.179.133 hdp-02
192.168.179.134 hdp-03
192.168.179.135 hdp-04
2. 下载Spark安装包
2.1 在spark官网下载spark2.3.1的安装包
通过securecrt、xshell或其他工具上传spark-安装包到服务器上
解压安装包到/usr/local目录
tar -zxvf spark-2.3.1-bin-hadoop2.8.tgz -C /usr/local

3. 配置Spark
3.1进入到Spark安装目录
cd /usr/local/spark-2.3.1
3.2进入conf目录并重命名并修改spark-env.sh.template文件
cd conf/
mv spark-env.sh.template spark-env.sh
vi spark-env.sh
在该配置文件中添加如下配置
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_111 #根据个人的jdk路径具体配置
保存退出
3.3重命名并修改slaves.template文件
mv slaves.template slaves
vi slaves
在该文件中添加子节点所在的位置(Worker节点)

保存退出
3.4将配置好的Spark拷贝到其他节点上
scp -r spark-2.3.1/ hdp-01:/usr/local/
scp -r spark-2.3.1/ hdp-02:/usr/local/
scp -r spark-2.3.1/ hdp-03:/usr/local/
3.5 Spark集群配置完毕,目前是1个Master,3个Work,master位于hdp-02,worker位于hdp-01,hdp-03,hdp-04
执行spark目录下 /sbin/start-all.sh 脚本启动集群
/usr/local/spark-2.3.1/sbin/start-all.sh
启动成功后,使用jps查看进程,如master节点上有master进程,worker
节点上有worker进程,则表明集群启动成功,可以通过8080端口查看集群运行状态
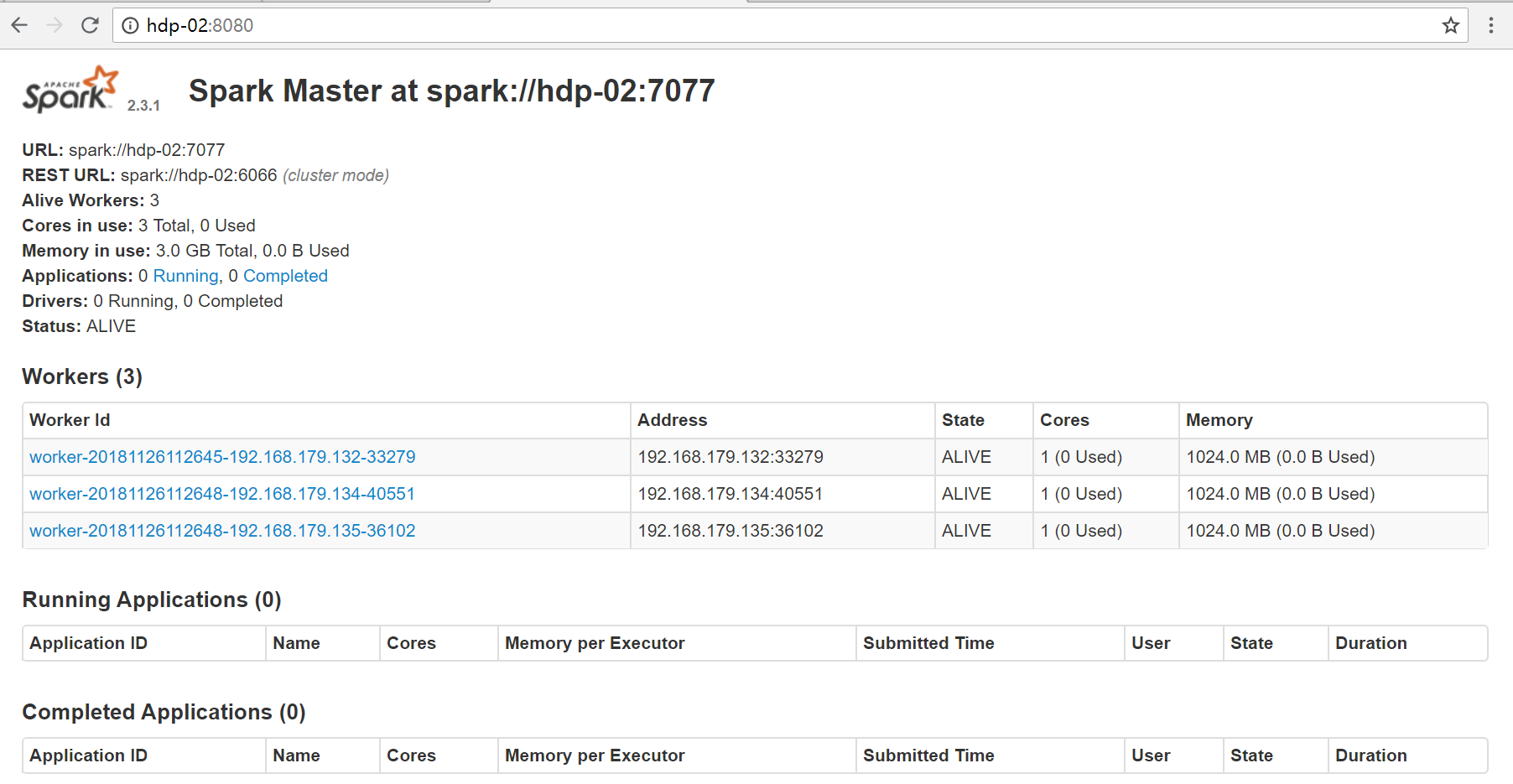
3.6 到此为止,Spark集群安装完毕,但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借助zookeeper,并且启动至少两个Master节点来实现高可用,实际生产环境中,多使用CDH或HDP来构建集群,学习阶段搭建普通集群足够使用,有兴趣的可以去做高可用配置,配置如下:
Spark集群规划:hdp-02,hdp-01是Master;hdp-03,hdp-04,hdp-05是Worker
安装配置zk集群,并启动zk集群
停止spark所有服务,修改配置文件spark-env.sh,在该配置文件中删掉SPARK_MASTER_IP并添加如下配置
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=zk1,zk2,zk3 -Dspark.deploy.zookeeper.dir=/spark"
1.在hdp-02节点上修改slaves配置文件内容指定worker节点
2.在hdp-02上执行sbin/start-all.sh脚本,然后在hdp-01上执行sbin/start-master.sh启动第二个Master
由于内存不足,无法在本地安装CDH或HDP集群;内存条已购买,电脑内存升级完成后,将出一篇CDH或HDP的安装教程。
下一篇将简单地开发一个spark程序,感谢阅读。
如有疑问,请留言。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号