
6_Dataloader使用
1. Dataloader使用
① Dataset只是去告诉我们程序,我们的数据集在什么位置,数据集第一个数据给它一个索引0,它对应的是哪一个数据。
② Dataloader就是把数据加载到神经网络当中,Dataloader所做的事就是每次从Dataset中取数据,至于怎么取,是由Dataloader中的参数决定的。
import torchvision
from torch.utils.data import DataLoader
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape) # 单张图片的shape[3,32,32]
print(img)
# DataLoader()说明
# def __init__(self, dataset: Dataset[T_co], batch_size: Optional[int] = 1,
# shuffle: Optional[bool] = None, sampler: Union[Sampler, Iterable, None] = None,
# batch_sampler: Union[Sampler[List], Iterable[List], None] = None,
# num_workers: int = 0, collate_fn: Optional[_collate_fn_t] = None,
# pin_memory: bool = False, drop_last: bool = False,
# timeout: float = 0, worker_init_fn: Optional[_worker_init_fn_t] = None,
# multiprocessing_context=None, generator=None,
# *, prefetch_factor: Optional[int] = None,
# persistent_workers: bool = False,
# pin_memory_device: str = ""):
# batch_size:每次取数据的个数。默认为1
# shuffle:是否打乱数据顺序,true:顺序打乱,false:顺序不打乱。默认为false
# num_workers:加载数据的进程个数。默认为0,表示主进程加载。num_workers>0,在windows下可能报BrokenPipeError错
# drop_last:是否扔掉最后的
# batch_size=4 使得 img0, target0 = dataset[0]、img1, target1 = dataset[1]、img2, target2 = dataset[2]、img3, target3 = dataset[3],然后这四个数据作为Dataloader的一个返回
test_loader = DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
# 用for循环取出DataLoader打包好的四个数据
for data in test_loader:
# 每个data都是由4张图片组成,imgs.size 为 [4,3,32,32],四张32×32的三通道图片,targets是四张图片标签组合而成
imgs, targets = data
print(imgs.shape)
torch.Size([3, 32, 32])
tensor([[[0.6196, 0.6235, 0.6471, ..., 0.5373, 0.4941, 0.4549],
[0.5961, 0.5922, 0.6235, ..., 0.5333, 0.4902, 0.4667],
[0.5922, 0.5922, 0.6196, ..., 0.5451, 0.5098, 0.4706],
...,
[0.2667, 0.1647, 0.1216, ..., 0.1490, 0.0510, 0.1569],
[0.2392, 0.1922, 0.1373, ..., 0.1020, 0.1137, 0.0784],
[0.2118, 0.2196, 0.1765, ..., 0.0941, 0.1333, 0.0824]],
[[0.4392, 0.4353, 0.4549, ..., 0.3725, 0.3569, 0.3333],
[0.4392, 0.4314, 0.4471, ..., 0.3725, 0.3569, 0.3451],
[0.4314, 0.4275, 0.4353, ..., 0.3843, 0.3725, 0.3490],
...,
[0.4863, 0.3922, 0.3451, ..., 0.3804, 0.2510, 0.3333],
[0.4549, 0.4000, 0.3333, ..., 0.3216, 0.3216, 0.2510],
[0.4196, 0.4118, 0.3490, ..., 0.3020, 0.3294, 0.2627]],
[[0.1922, 0.1843, 0.2000, ..., 0.1412, 0.1412, 0.1294],
[0.2000, 0.1569, 0.1765, ..., 0.1216, 0.1255, 0.1333],
[0.1843, 0.1294, 0.1412, ..., 0.1333, 0.1333, 0.1294],
...,
[0.6941, 0.5804, 0.5373, ..., 0.5725, 0.4235, 0.4980],
[0.6588, 0.5804, 0.5176, ..., 0.5098, 0.4941, 0.4196],
[0.6275, 0.5843, 0.5176, ..., 0.4863, 0.5059, 0.4314]]])
2. Tensorboard展示
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
# batch_size=4 使得 img0, target0 = dataset[0]、img1, target1 = dataset[1]、img2, target2 = dataset[2]、img3, target3 = dataset[3],然后这四个数据作为Dataloader的一个返回
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
# 用for循环取出DataLoader打包好的四个数据
writer = SummaryWriter("logs")
step = 0
for data in test_loader:
# 每个data都是由64张图片组成,imgs.size 为 [4,3,32,32],四张32×32的三通道图片,targets是四张图片标签组合而成
imgs, targets = data
writer.add_images("test_data",imgs,step)
step = step + 1
writer.close()
① 在 Anaconda 终端里面,激活py3.6.3环境,再输入 tensorboard --logdir=C:\Users\wangy\Desktop\03CV\logs 命令,将网址赋值浏览器的网址栏,回车,即可查看tensorboard显示日志情况。

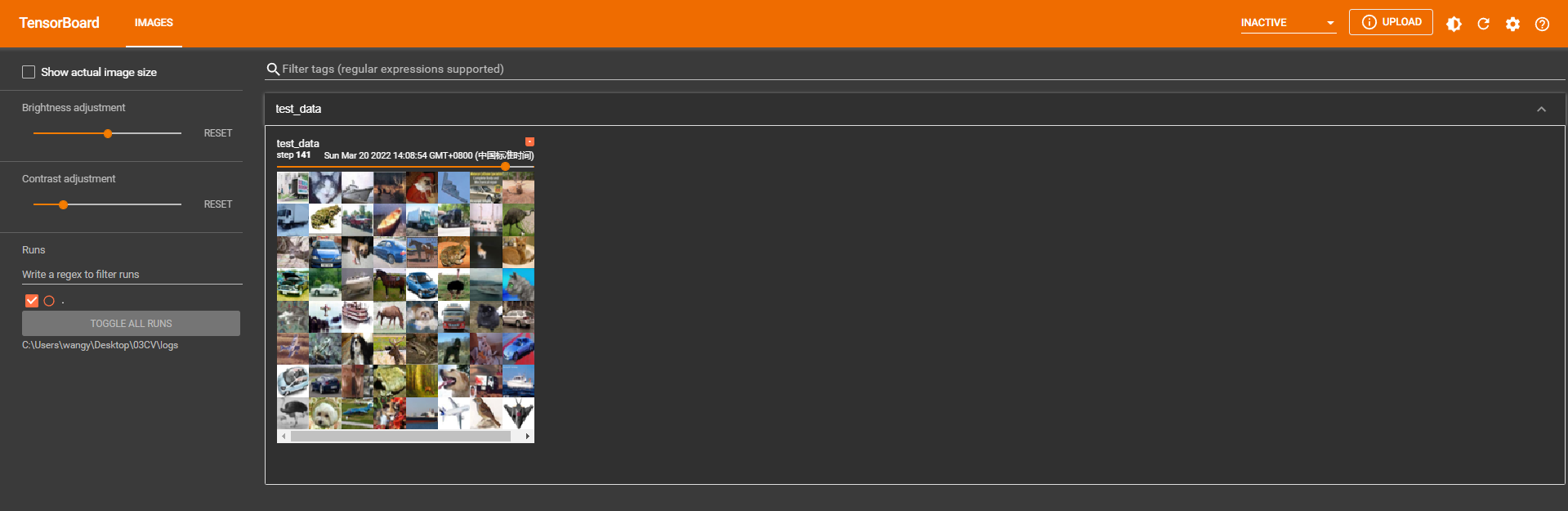
3. Dataloader多轮次
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
# batch_size=4 使得 img0, target0 = dataset[0]、img1, target1 = dataset[1]、img2, target2 = dataset[2]、img3, target3 = dataset[3],然后这四个数据作为Dataloader的一个返回
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=True)
# 用for循环取出DataLoader打包好的四个数据
writer = SummaryWriter("logs")
# 进行两轮取数据
for epoch in range(2):
step = 0
for data in test_loader:
# 每个data都是由64张图片组成,imgs.size 为 [4,3,32,32],四张32×32的三通道图片,targets是四张图片标签组合而成
imgs, targets = data
writer.add_images("Epoch:{}".format(epoch),imgs,step)
step = step + 1
writer.close()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号