第一次个人编程作业
Github地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 100 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 30 |
| Development | 开发 | 600 | 550 |
| · Analysis | · 需求分析 (包括学习新技术) | 150 | 120 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 20 | 15 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 25 |
| · Design | · 具体设计 | 100 | 90 |
| · Coding | · 具体编码 | 300 | 350 |
| · Code Review | · 代码复审 | 20 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 100 |
| Reporting | 报告 | 60 | 120 |
| · Test Repor | · 测试报告 | 30 | 40 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 30 |
| · 合计 | 1510 | 1640 |
计算模块接口的设计与实现过程
设计
- 看到题目要求首先想法应该有“省”,“市”,“县”,“路”类。
- 同时“省”,“市”,“县”类中应该各有一个List属性用来表示它们对应的下一级的地址集
- 考虑到会有缺少地名的情况,因此需要有一个类可以存放所有的地址,以便上一级地名缺少的时候可以在所有地址中检索。
- 除此之外,应有一个Result类用来存放每一行的结果,Result类中应该有“姓名”,“手机”,“地址”三个属性。
实现
- 代码的实现主要难点在于地址级别的分割,由于有些测试样例不会出现“省”“市”“县”这样的可以易区分地址等级的字眼,因此需要导入一个有全国地址的JSON文件用于检索。
- 主要的实现是先把JSON文件导入到代码中的一个个级别类中,然后把题目的地址从左往右的顺序按照级别的高低进行检索,如果上一级缺失则往更上一级进行遍历查找,最坏的情况是要查找全部的数据。
附上查找县和路的部分代码,其他级别的检索同理:
Town town = new Town();
town.setName("");
//市和省级地址都缺失的情况
if(("").equals(city.getName())&&("").equals(province.getName())){
for(Town t: Address.getTownList()){
//取前两个或一个字进行匹配
if(t.getName().length()>=2)
townName = t.getName().substring(0,2);
else townName = t.getName().substring(0,1);
if(address.contains(townName)){
town = t;
details = subTwoString(t.getName(),address);
townName = details[0];
address = details[1];
break;
}
}
}else if (("").equals(city.getName())&&!("").equals(province.getName())){
//省级地址不缺失
List<Town> townList = new ArrayList<>();
for(City c : province.getCityList()){
townList.addAll(c.getTownList());
}
for(Town t: townList){
if(t.getName().length()>=2)
townName = t.getName().substring(0,2);
else townName = t.getName().substring(0,1);
if(address.contains(townName)){
town = t;
details = subTwoString(t.getName(),address);
townName = details[0];
address = details[1];
break;
}
}
}else{
for(Town t: city.getTownList()){
if(t.getName().length()>=2)
townName = t.getName().substring(0,2);
else townName = t.getName().substring(0,1);
if(address.contains(townName)){
town = t;
details = subTwoString(t.getName(),address);
townName = details[0];
address = details[1];
break;
}
}
}
计算模块接口部分的性能改进
性能的改进主要是对于地址缺失的情况的处理,一开始我处理缺失的方法是直接从全部数据中检索。后来进行了改进,遇到地址缺失的情况,并不盲目的检索全部地址,而是从低级往高级,找到不缺失的最低的地址级,从此级别开始检索,这样就大大增加了效率。
性能分析图:
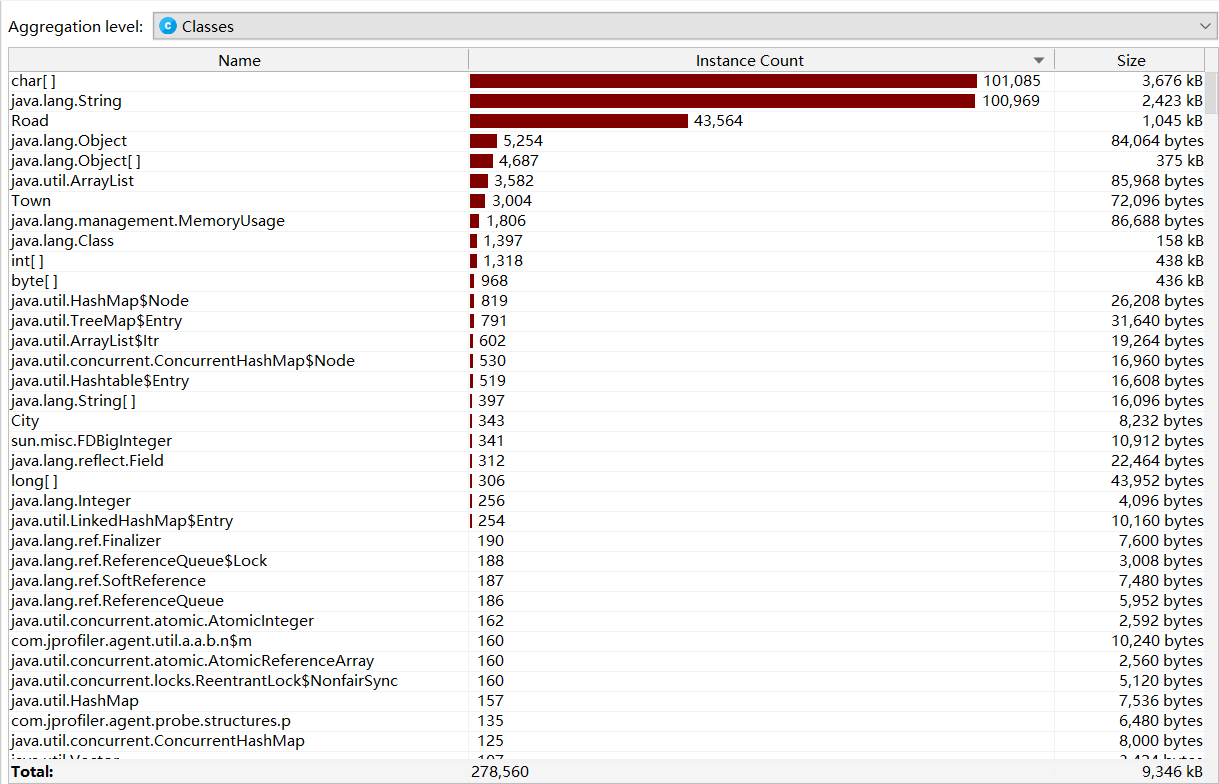
程序中消耗最大的函数是检索地址的函数,有很多的for循环语句。
计算模块部分单元测试展示
单元测试部分代码
@Test
public void splitData() throws IOException {
//测试数据文件的路径
String inputPath = "C:\\Users\\Richer\\Desktop\\test.txt";
//标准答案文件的路径
String answerPath = "C:\\Users\\Richer\\Desktop\\answer.txt";
BufferedReader inputReader = new BufferedReader(new InputStreamReader(new
FileInputStream(inputPath), "utf-8"));
BufferedReader answerReader = new BufferedReader(new InputStreamReader(new
FileInputStream(answerPath), "utf-8"));
String in;
String answer;
Input input = new Input();
while ((in = inputReader.readLine())!=null&&(answer = answerReader.readLine())!=null)
{
String[] out = input.splitData(in);
//标准答案中的各项用“,”隔开
String[] aSet = answer.split(",");
for(int i=0;i<out.length;i++){
//比较输出和答案
System.out.println(aSet[i].equals(out[i]));
}
}
}
splitData函数的主要用途就是把各条输入中的题目类型,姓名,手机号码,地址分割开来。
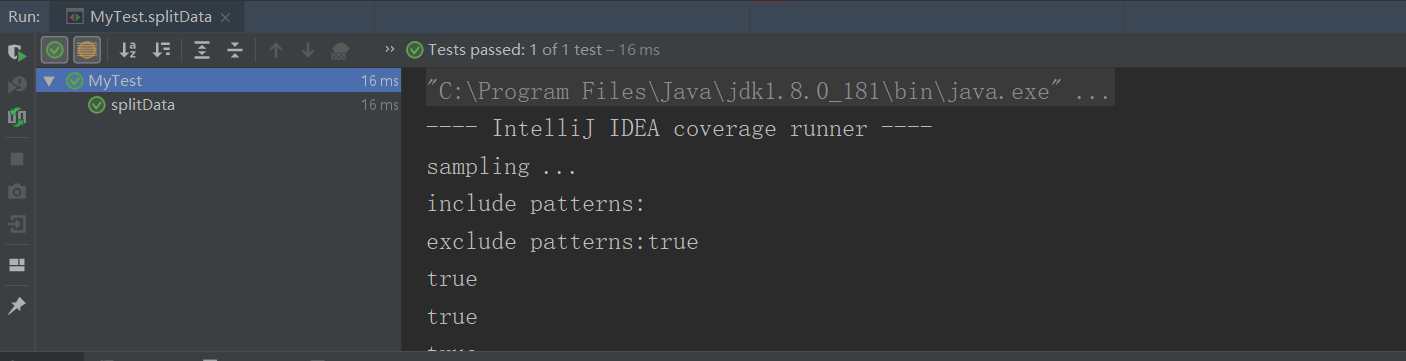
打印结果:
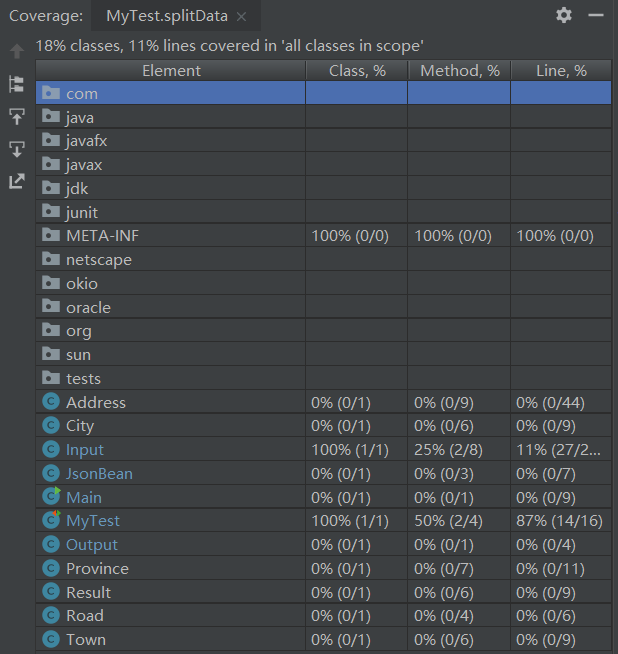
单元测试覆盖率:
计算模块部分异常处理说明
异常处理主要是IOException的处理
例如读取文件的时候文件路径错误,导致无法找到对应的文件等。

总结
地址簿的设计还存在很多不足,代码也不够规范,希望后面可以找机会再完善一点(前提是有时间...)。
that's all.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号