深入理解TCP协议及其源代码
TCP三次握手理论
三次握手过程

第一次握手
客户端A向服务端B发出连接请求,同步位SYN=1,初始序列seq=x,连接请求报文段不能携带数据,但是要消耗一个序号,这时客户端A进入SYN-SENT(同步已发送状态)
第二次握手
服务端B收到请求报文段之后,向A发送后确认。将同部位SYN和确认位都置为1,确认序号ack=x+1,同时自己选择一个初始序号seq=y。连接接收报文也不能携带数据,但是也要消耗一个序号,这时服务端进入SYN-RCVD(同步收到状态)
第三次握手
A收到B的确认时候要给B一个确认。确认报文段的确认位ACK=1,确认号ack=y+1,自己的序号seq=x+1。这时,TCP连接已经建立,客户端进入ESTABLISHED(已建立连接状态)。B收到A发出的确认报文之后也进入已建立连接状态
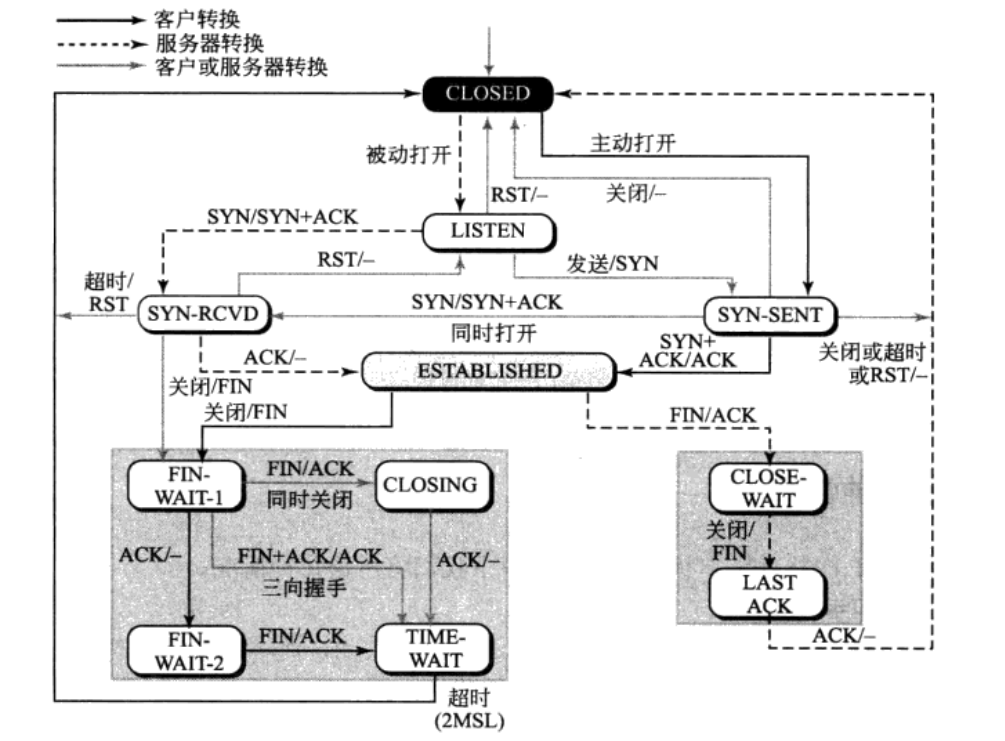
状态转换
在TCP连接建立的过程中会涉及到状态的转换,下面以有限状态机的形式给出在连接建立、数据传送和连接终止时所发生事件之间是如何转换的。
三次握手源代码分析
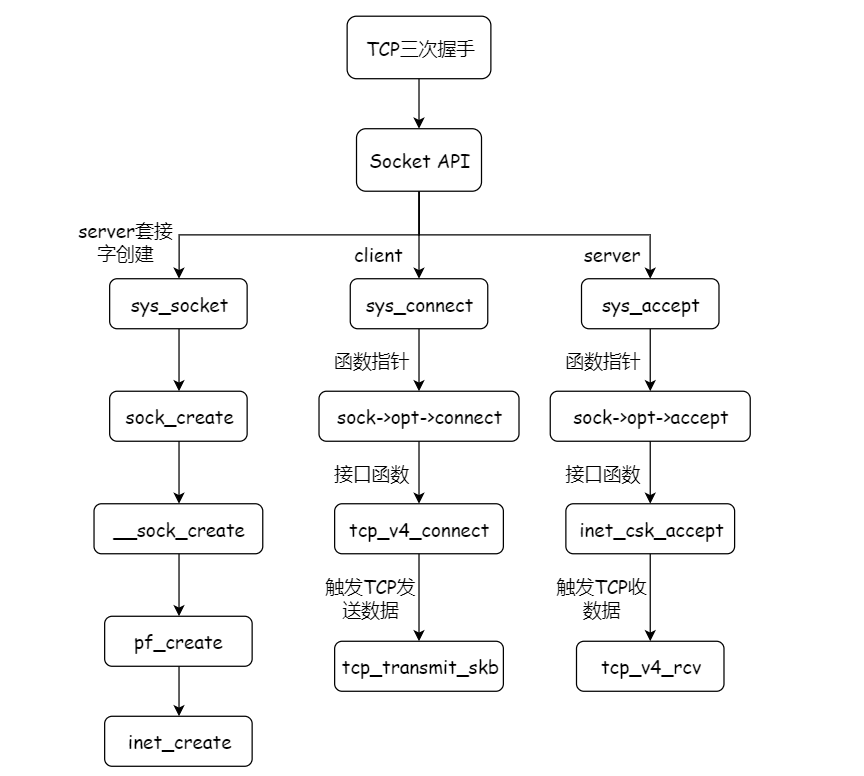
经过前一次实验,我们调研了socket相关的系统调用,了解了在服务器端与客户端socket建立、连接、通信以及终止过程中所涉及到的系统调用。
其中,在服务器端相继调用__sys_socket、__sys_bind和__sys_listen内核函数后,服务器进入监听状态,即打开端口被动地等待客户端连接。当客户端调用__sys_connect发出连接时,这就是我们今天所探讨地tcp三次握手过程的开始了。
那么,在TCP三次握手这个过程中所涉及到的调用过程是怎样的呢?
创建Socket
socket(AF_INET, SOCK_DGRAM, IPPROTO_TCP)
其中涉及两步关键操作:sock_create()与sock_map_fd()。
retval = sock_create(family, type, protocol, &sock);
if (retval < 0)
goto out;
retval = sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
if (retval < 0)
goto out_release;
sock_create()用于创建socket,sock_map_fd()将之映射到文件描述符,使socket能通过fd进行访问。
在sock_create()中,与我们之前所分析的socket其他API处理逻辑一样,它直接调用了相对应的内核处理函数。
sock_create() -> __sock_create()
而我们从__sock_create()代码可以看到创建包含两步:sock_alloc()和pf->create()。
sock_alloc()分配了sock内存空间并初始化inode;pf->create()初始化了sk。
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
{
int err;
struct socket *sock;
const struct net_proto_family *pf;
/*
* Check protocol is in range
*/
if (family < 0 || family >= NPROTO)
return -EAFNOSUPPORT;
if (type < 0 || type >= SOCK_MAX)
return -EINVAL;
/* Compatibility.
This uglymoron is moved from INET layer to here to avoid
deadlock in module load.
*/
if (family == PF_INET && type == SOCK_PACKET) {
pr_info_once("%s uses obsolete (PF_INET,SOCK_PACKET)\n",
current->comm);
family = PF_PACKET;
}
err = security_socket_create(family, type, protocol, kern);
if (err)
return err;
/*
* Allocate the socket and allow the family to set things up. if
* the protocol is 0, the family is instructed to select an appropriate
* default.
*/
sock = sock_alloc();
if (!sock) {
net_warn_ratelimited("socket: no more sockets\n");
return -ENFILE; /* Not exactly a match, but its the
closest posix thing */
}
sock->type = type;
#ifdef CONFIG_MODULES
/* Attempt to load a protocol module if the find failed.
*
* 12/09/1996 Marcin: But! this makes REALLY only sense, if the user
* requested real, full-featured networking support upon configuration.
* Otherwise module support will break!
*/
if (rcu_access_pointer(net_families[family]) == NULL)
request_module("net-pf-%d", family);
#endif
rcu_read_lock();
pf = rcu_dereference(net_families[family]);
err = -EAFNOSUPPORT;
if (!pf)
goto out_release;
/*
* We will call the ->create function, that possibly is in a loadable
* module, so we have to bump that loadable module refcnt first.
*/
if (!try_module_get(pf->owner))
goto out_release;
/* Now protected by module ref count */
rcu_read_unlock();
err = pf->create(net, sock, protocol, kern);
if (err < 0)
goto out_module_put;
/*
* Now to bump the refcnt of the [loadable] module that owns this
* socket at sock_release time we decrement its refcnt.
*/
if (!try_module_get(sock->ops->owner))
goto out_module_busy;
/*
* Now that we're done with the ->create function, the [loadable]
* module can have its refcnt decremented
*/
module_put(pf->owner);
err = security_socket_post_create(sock, family, type, protocol, kern);
if (err)
goto out_sock_release;
*res = sock;
return 0;
out_module_busy:
err = -EAFNOSUPPORT;
out_module_put:
sock->ops = NULL;
module_put(pf->owner);
out_sock_release:
sock_release(sock);
return err;
out_release:
rcu_read_unlock();
goto out_sock_release;
}
EXPORT_SYMBOL(__sock_create);
这里,关于sock_alloc的过程我们不再过多涉及,重点内容是分析TCP三次握手的过程。
客户端流程
经过上一次实验中对客户端hello函数的分析,我们最终得出结论:
执行hello命令时,客户端所经历的流程为connect() -> send() -> recv()。
那么,按照这一过程我们对源码进行分析。
发送SYN报文,向服务器发起tcp连接
connect(fd, servaddr, addrlen);
-> SYSCALL_DEFINE3()
-> sock->ops->connect() == inet_stream_connect (sock->ops即inet_stream_ops)
-> tcp_v4_connect()
其中,tcp_v4_connect()的结构图如下:
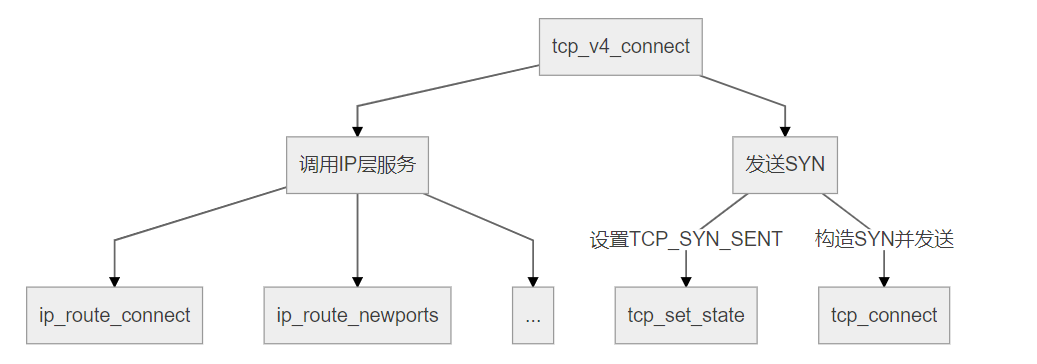
在该函数中,首先查找到达[daddr, dport]的路由项。
要注意的是由于是作为客户端调用,创建socket后调用connect,因而saddr, sport都是0,同样在未查找路由前,要走的出接口oif也是不知道的,因此也是0。在查找完路由表后(注意不是路由缓存),可以得知出接口,但并未存储到sk中。
因此插入的路由缓存是特别要注意的:它的键值与实际值是不相同的,这个不同点就在于oif与saddr,键值是[saddr=0, sport=0, daddr, dport, oif=0],而缓存项值是[saddr, sport=0, daddr, dport, oif]。
tmp = ip_route_connect(&rt, nexthop, inet->inet_saddr,
RT_CONN_FLAGS(sk), sk->sk_bound_dev_if,
IPPROTO_TCP,
inet->inet_sport, usin->sin_port, sk, 1);
if (tmp < 0) {
if (tmp == -ENETUNREACH)
IP_INC_STATS_BH(sock_net(sk), IPSTATS_MIB_OUTNOROUTES);
return tmp;
}
通过查找到的路由项,对inet进行赋值,可以看到,除了sport,都赋予了值,sport的选择复杂点,因为它要随机从未使用的本地端口中选择一个。
if (!inet->inet_saddr)
inet->inet_saddr = rt_rt_src;
inet->inet_rcv_addr = inet->inet_saddr;
……
inet->inet_dport = usin->sin_port;
inet->inet_daddr = daddr;
状态从CLOSING转到TCP_SYN_SENT,这个在之前的TCP的状态转移图中阐述过了。
tcp_set_state(sk, TCP_SYN_SENT);
插入到bind链表中。
err = inet_hash_connect(&tcp_death_row, sk); //== > __inet_hash_connect()
当snum==0时,表明此时源端口没有指定,此时会随机选择一个空闲端口作为此次连接的源端口。low和high分别表示可用端口的下限和上限,remaining表示可用端口的数。
注意这里的可用只是指端口可以用作源端口,其中部分端口可能已经作为其它socket的端口号在使用了,所以要循环1~remaining,直到查找到空闲的源端口。
if (!snum) {
inet_get_local_port_range(&low, &high);
remaining = (high - low) + 1;
……
for (i = 1; i <= remaining; i++) {
……// choose a valid port
}
}
下面来看下对每个端口的检查,即//choose a valid port部分的代码。
这里要先了解下tcp的内核表组成,udp的表内核表udptable只是一张hash表,tcp的表则稍复杂,它的名字是tcp_hashinfo,在tcp_init()中被初始化,这个数据结构定义如下(省略了不相关的数据):
struct inet_hashinfo {
struct inet_ehash_bucket *ehash;
……
struct inet_bind_hashbucket *bhash;
……
struct inet_listen_hashbucket listening_hash[INET_LHTABLE_SIZE]
____cacheline_aligned_in_smp;
};
从定义可以看出,tcp表又分成了三张表ehash, bhash, listening_hash。
其中ehash, listening_hash对应于socket处在TCP的ESTABLISHED, LISTEN状态,bhash对应于socket已绑定了本地地址。
三者间并不互斥,如一个socket可同时在bhash和ehash中,由于TIME_WAIT是一个比较特殊的状态,所以ehash又分成了chain和twchain,为TIME_WAIT的socket单独形成一张表。
回到刚才的代码,现在还只是建立socket连接,使用的就应该是tcp表中的bhash。首先取得内核tcp表的bind表 – bhash,查看是否已有socket占用:
- 如果没有,则调用inet_bind_bucket_create()创建一个bind表项tb,并插入到bind表中,跳转至goto ok代码段;
- 如果有,则跳转至goto ok代码段。
进入ok代码段表明已找到合适的bind表项(无论是创建的还是查找到的),调用inet_bind_hash()赋值源端口inet_num。
for (i = 1; i <= remaining; i++) {
port = low + (i + offset) % remaining;
head = &hinfo->bhash[inet_bhashfn(net, port, hinfo->bhash_size)];
……
inet_bind_bucket_for_each(tb, node, &head->chain) {
if (net_eq(ib_net(tb), net) && tb->port == port) {
if (tb->fastreuse >= 0)
goto next_port;
WARN_ON(hlist_empty(&tb->owners));
if (!check_established(death_row, sk, port, &tw))
goto ok;
goto next_port;
}
}
tb = inet_bind_bucket_create(hinfo->bind_bucket_cachep, net, head, port);
……
next_port:
spin_unlock(&head->lock);
}
ok:
……
inet_bind_hash(sk, tb, port);
……
goto out;
在获取到合适的源端口号后,会重建路由项来进行更新:
err = ip_route_newports(&rt, IPPROTO_TCP, inet->inet_sport, inet->inet_dport, sk);
函数比较简单,在获取sport前已经查找过一次路由表,并插入了key=[saddr=0, sport=0, daddr, dport, oif=0]的路由缓存项;现在获取到了sport,调用ip_route_output_flow()再次更新路由缓存表,它会添加key=[saddr=0, sport, daddr, dport, oif=0]的路由缓存项。这里可以看出一个策略选择,查询路由表->获取sport->查询路由表,为什么不是获取sport->查询路由表的原因可能是效率的问题。
if (sport != (*rp)->fl.fl_ip_sport ||
dport != (*rp)->fl.fl_ip_dport) {
struct flowi fl;
memcpy(&fl, &(*rp)->fl, sizeof(fl));
fl.fl_ip_sport = sport;
fl.fl_ip_dport = dport;
fl.proto = protocol;
ip_rt_put(*rp);
*rp = NULL;
security_sk_classify_flow(sk, &fl);
return ip_route_output_flow(sock_net(sk), rp, &fl, sk, 0);
}
write_seq相当于第一次发送TCP报文的ISN,如果为0,则通过计算获取初始值,否则延用上次的值。在获取完源端口号,并查询过路由表后,TCP正式发送SYN报文,注意在这之前TCP状态已经更新成了TCP_SYN_SENT,而在函数最后才调用tcp_connect(sk)发送SYN报文,这中间是有时差的。
if (!tp->write_seq)
tp->write_seq = secure_tcp_sequence_number(inet->inet_saddr,
inet->inet_daddr,
inet->inet_sport,
usin->sin_port);
inet->inet_id = tp->write_seq ^ jiffies;
err = tcp_connect(sk);
客户端调用tcp_connect()发送SYN报文。
该函数的结构如下图所示。
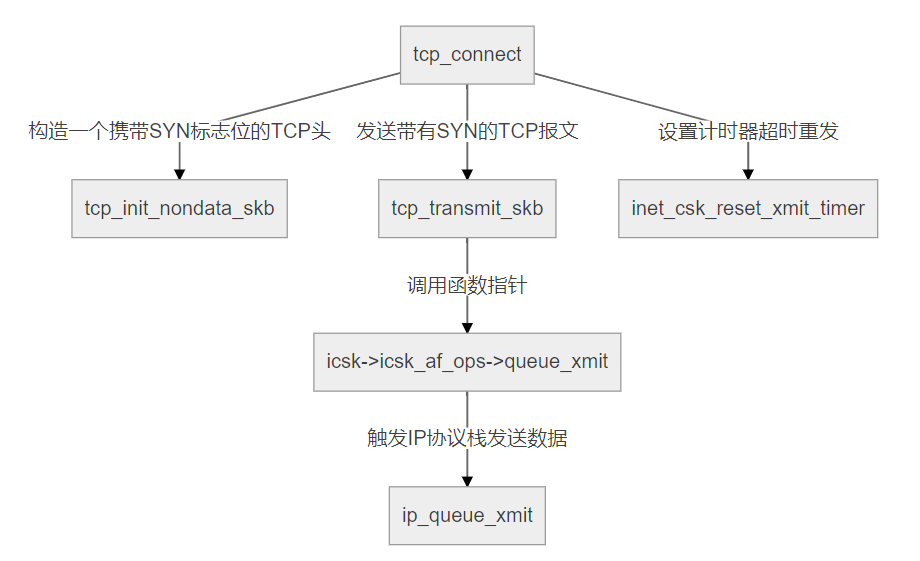
几步重要的代码如下:
tcp_connect_init()中设置了tp->rcv_nxt=0,tcp_transmit_skb()负责发送报文,其中seq=tcb->seq=tp->write_seq,ack_seq=tp->rcv_nxt。
tcp_connect_init(sk);
tp->snd_nxt = tp->write_seq;
……
tcp_transmit_skb(sk, buff, 1, sk->sk_allocation);
收到服务端的SYN+ACK,发送ACK
tcp_rcv_synsent_state_process()
此时已接收到对方的ACK,状态变迁到TCP_ESTABLISHED。最后发送对方SYN的ACK报文。
tcp_set_state(sk, TCP_ESTABLISHED);
tcp_send_ack(sk);
服务器端流程
如之前replyhi命令执行时分析的一样,我们了解到服务端所经历的流程如下:
bind() -> listen() -> accept() -> recv() -> send()。
bind() -> inet_bind()
bind操作的主要作用是将创建的socket与给定的地址相绑定,这样创建的服务才能公开的让外部调用。当然对于socket服务器的创建来说,这一步不是必须的,在listen()时如果没有绑定地址,系统会选择一个随机可用地址作为服务器地址。
一个socket地址分为ip和port,inet->inet_saddr赋值了传入的ip,snum是传入的port,对于端口,要检查它是否已被占用,这是由sk->sk_prot->get_port()完成的(这个函数前面已经分析过,在传入port时它检查是否被占用;传入port=0时它选择未用的端口)。如果没有被占用,inet->inet_sport被赋值port,因为是服务监听端,不需要远端地址,inet_daddr和inet_dport都置0。
注意bind操作不会改变socket的状态,仍为创建时的TCP_CLOSE。
snum = ntohs(addr->sin_port);
……
inet->inet_rcv_saddr = inet->inet_saddr = addr->sin_addr.s_addr;
if (sk->sk_prot->get_port(sk, snum)) {
inet->inet_saddr = inet->inet_rcv_saddr = 0;
err = -EADDRINUSE;
goto out_release_sock;
}
……
inet->inet_sport = htons(inet->inet_num);
inet->inet_daddr = 0;
inet->inet_dport = 0;
listen() -> inet_listen()
listen操作开始服务器的监听,此时服务就可以接受到外部连接了。在开始监听前,要检查状态是否正确,sock->state == SS_UNCONNECTED确保仍是未连接的socket,sock->type == SOCK_STREAM确保是TCP协议,old_state确保此时状态是TCP_CLOSE或TCP_LISTEN,在其它状态下进行listen都是错误的。
if (sock->state != SS_UNCONNECTED || sock->type != SOCK_STREAM)
goto out;
old_state = sk->sk_state;
if (!((1 << old_state) & (TCPF_CLOSE | TCPF_LISTEN)))
goto out;
如果已是TCP_LISTEN态,则直接跳过,不用再执行listen了,而只是重新设置listen队列长度sk_max_ack_backlog,改变listen队列长也是多次执行listen的作用。如果还没有执行listen,则还要调用inet_csk_listen_start()开始监听。
inet_csk_listen_start()变迁状态至TCP_LISTEN,分配监听队列,如果之前没有调用bind()绑定地址,则这里会分配一个随机地址。
if (old_state != TCP_LISTEN) {
err = inet_csk_listen_start(sk, backlog);
if (err)
goto out;
}
sk->sk_max_ack_backlog = backlog;
accept()
accept所涉及的调用栈比较深:accept() -> sys_accept4() -> inet_accept() -> inet_csk_accept()。
但accept()实际要做的事件并不多,它的作用是返回一个已经建立连接的socket(即经过了三次握手)。
这个过程是异步的,accept()并不亲自去处理三次握手过程,而只是监听icsk_accept_queue队列,当有socket经过了三次握手,它就会被加到icsk_accept_queue中,所以accept要做的就是等待队列中插入socket,然后被唤醒并返回这个socket。
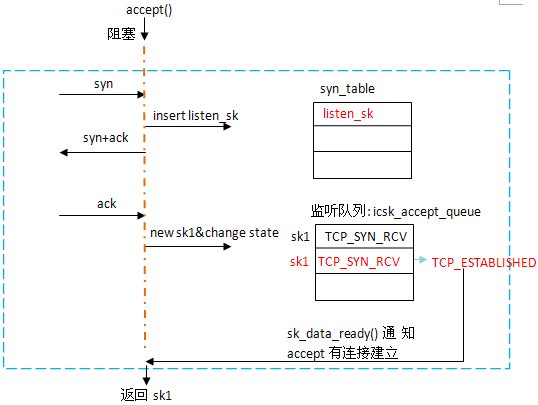
而三次握手的过程完全是协议栈本身去完成的。换句话说,协议栈相当于写者,将socket写入队列,accept()相当于读者,将socket从队列读出。这个过程从listen就已开始,所以即使不调用accept(),客户仍可以和服务器建立连接,但由于没有处理,队列很快会被占满。
if (reqsk_queue_empty(&icsk->icsk_accept_queue)) {
long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK);
……
error = inet_csk_wait_for_connect(sk, timeo);
……
}
newsk = reqsk_queue_get_child(&icsk->icsk_accept_queue, sk);
协议栈向队列中加入socket的过程就是完成三次握手的过程,客户端通过向已知的listen fd发起连接请求,对于到来的每个连接,都会创建一个新的sock,当它经历了TCP_SYN_RCV -> TCP_ESTABLISHED后,就会被添加到icsk_accept_queue中。
而监听的socket状态始终为TCP_LISTEN,保证连接的建立不会影响socket的接收。
接收客户端发来的SYN,发送SYN+ACK
所涉及到的内核函数为:tcp_v4_do_rcv()
tcp_v4_do_rcv()是TCP模块接收的入口函数。其主要结构如下图所示。
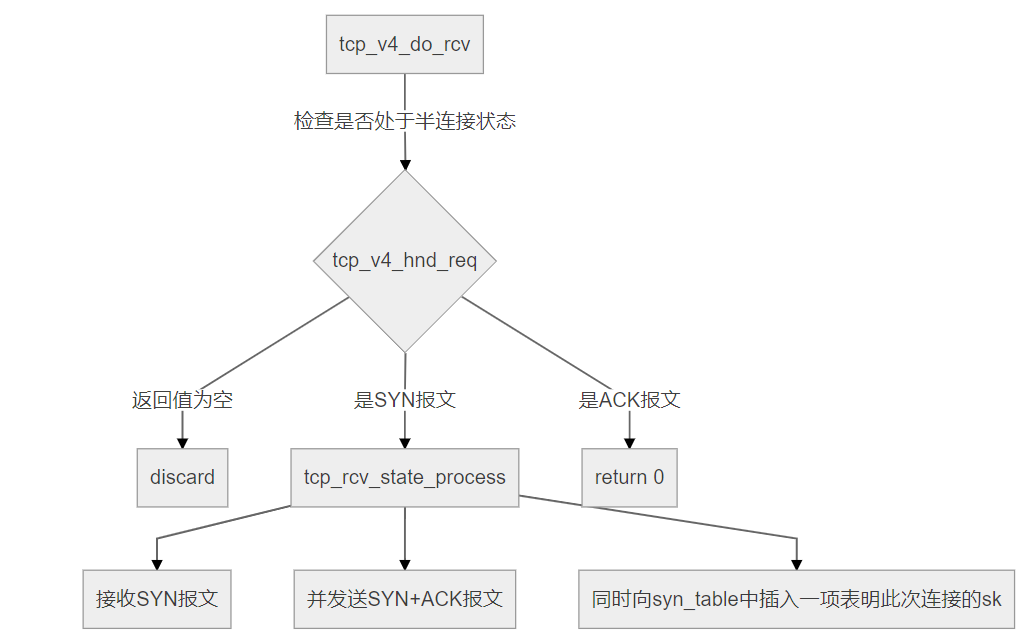
客户端发起请求的对象是listen fd,所以sk->sk_state == TCP_LISTEN,调用tcp_v4_hnd_req()来检查是否处于半连接,只要三次握手没有完成,这样的连接就称为半连接,具体而言就是收到了SYN,但还没有收到ACK的连接。
所以对于这个查找函数,如果是SYN报文,则会返回listen的socket(连接尚未创建);如果是ACK报文,则会返回SYN报文处理中插入的半连接socket。其中存储这些半连接的数据结构是syn_table,它在listen()调用时被创建,大小由sys_ctl_max_syn_backlog和listen()传入的队列长度决定。
此时是收到SYN报文,tcp_v4_hnd_req()返回的仍是sk,调用tcp_rcv_state_process()来接收SYN报文,并发送SYN+ACK报文,同时向syn_table中插入一项表明此次连接的sk。
if (sk->sk_state == TCP_LISTEN) {
struct sock *nsk = tcp_v4_hnd_req(sk, skb);
if (!nsk)
goto discard;
if (nsk != sk) {
if (tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
}
TCP_CHECK_TIMER(sk);
if (tcp_rcv_state_process(sk, skb, tcp_hdr(skb), skb->len)) {
rsk = sk;
goto reset;
}
tcp_rcv_state_process()处理各个状态上socket的情况。下面是处于TCP_LISTEN的代码段,处于TCP_LISTEN的socket不会再向其它状态变迁,它负责监听,并在连接建立时创建新的socket。实际上,当收到第一个SYN报文时,会执行这段代码,conn_request() => tcp_v4_conn_request。
case TCP_LISTEN:
……
if (th->syn) {
if (icsk->icsk_af_ops->conn_request(sk, skb) < 0)
return 1;
kfree_skb(skb);
return 0;
}
tcp_v4_conn_request()中注意两个函数就可以了:tcp_v4_send_synack()向客户端发送了SYN+ACK报文,inet_csk_reqsk_queue_hash_add()将sk添加到了syn_table中,填充了该客户端相关的信息。这样,再次收到客户端的ACK报文时,就可以在syn_table中找到相应项了。
if (tcp_v4_send_synack(sk, dst, req, (struct request_values *)&tmp_ext) || want_cookie)
goto drop_and_free;
inet_csk_reqsk_queue_hash_add(sk, req, TCP_TIMEOUT_INIT);
接收客户端发来的ACK
tcp_v4_do_rcv()
具体过程与收到SYN报文相同,不同点在于syn_table中已经插入了有关该连接的条目,tcp_v4_hnd_req()会返回一个新的sock: nsk,然后会调用tcp_child_process()来进行处理。在tcp_v4_hnd_req()中会创建新的sock,下面详细看下这个函数。
if (sk->sk_state == TCP_LISTEN) {
struct sock *nsk = tcp_v4_hnd_req(sk, skb);
if (!nsk)
goto discard;
if (nsk != sk) {
if (tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
}
tcp_v4_hnd_req()
之前已经分析过,inet_csk_search_req()会在syn_table中找到req,此时进入tcp_check_req()
struct request_sock *req = inet_csk_search_req(sk, &prev, th->source, iph->saddr, iph->daddr);
if (req)
return tcp_check_req(sk, skb, req, prev);
tcp_check_req()
syn_recv_sock() -> tcp_v4_syn_recv_sock()会创建一个新的sock并返回,创建的sock状态被直接设置为TCP_SYN_RECV,然后因为此时socket已经建立,将它添加到icsk_accept_queue中。
状态TCP_SYN_RECV的设置可能比较奇怪,按照TCP的状态转移图,在服务端收到SYN报文后变迁为TCP_SYN_RECV,但看到在实现中收到ACK后才有了状态TCP_SYN_RECV,并且马上会变为TCP_ESTABLISHED,所以这个状态变得无足轻重。
实际上,这样做的原因是因为listen和accept返回的socket是不同的,而只有真正连接建立时才会创建这个新的socket,在收到SYN报文时新的socket还没有建立,就无从谈状态变迁了。这里同样是一个平衡的存在,你也可以在收到SYN时创建一个新的socket,代价就是无用的socket大大增加了。
child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL);
if (child == NULL)
goto listen_overflow;
inet_csk_reqsk_queue_unlink(sk, req, prev);
inet_csk_reqsk_queue_removed(sk, req);
inet_csk_reqsk_queue_add(sk, req, child);
tcp_child_process()
如果此时sock: child被用户进程锁住了,那么就先添加到backlog中__sk_add_backlog(),待解锁时再处理backlog上的sock;如果此时没有被锁住,则先调用tcp_rcv_state_process()进行处理,处理完后,如果child状态到达TCP_ESTABLISHED,则表明其已就绪,调用sk_data_ready()唤醒等待在isck_accept_queue上的函数accept()。
if (!sock_owned_by_user(child)) {
ret = tcp_rcv_state_process(child, skb, tcp_hdr(skb), skb->len);
if (state == TCP_SYN_RECV && child->sk_state != state)
parent->sk_data_ready(parent, 0);
} else {
__sk_add_backlog(child, skb);
}
tcp_rcv_state_process()处理各个状态上socket的情况。
下面是处于TCP_SYN_RECV的代码段,注意此时传入函数的sk已经是新创建的sock了(在tcp_v4_hnd_req()中),并且状态是TCP_SYN_RECV,而不再是listen socket,在收到ACK后,sk状态变迁为TCP_ESTABLISHED,而在tcp_v4_hnd_req()中也已将sk插入到了icsk_accept_queue上,此时它就已经完全就绪了,回到tcp_child_process()便可执行sk_data_ready()。
case TCP_SYN_RECV:
if (acceptable) {
……
tcp_set_state(sk, TCP_ESTABLISHED);
sk->sk_state_change(sk);
……
tp->snd_una = TCP_SKB_CB(skb)->ack_seq;
tp->snd_wnd = ntohs(th->window) << tp->rx_opt.snd_wscale;
tcp_init_wl(tp, TCP_SKB_CB(skb)->seq);
……
}
总结
最后,以图示来展示TCP三次握手涉及的过程。
运行追踪分析
首先,启动MenuOS系统,并使用gdb连接进行调试。
命令
break inet_init
break sock_create
break __sys_connect
break __sys_accept4
break tcp_v4_connect
break tcp_connect_init
break tcp_connect
break tcp_transmit_skb
break tcp_v4_do_rcv
break tcp_rcv_state_process

设置完断点,我们使用continue命令来看看是否可以捕获到这些断点。
continue
我们首先捕获到的是inet_init断点。如我们之前分析的一样,该函数所完成的功能是TCP/IP协议栈的初始化,将所有的基础协议添加进来,因此在socket初始化之前需要先运行加载该函数。
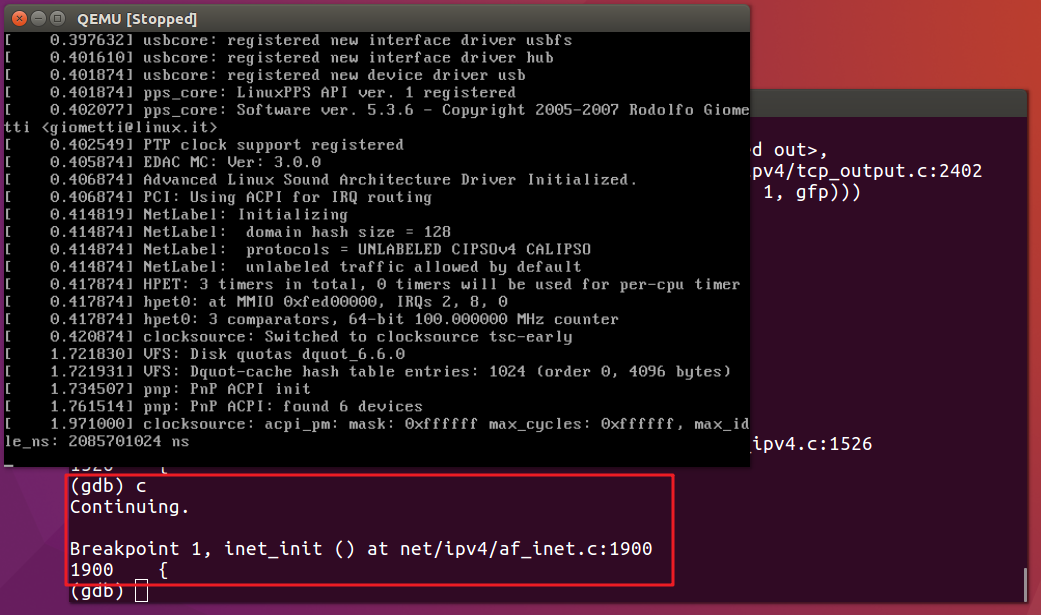
继续向下运行。
这一次我们所捕获到三次__sys_socket,关于这一点我在上一篇博客中已经分析过这种情况了,此时进行的是socket的初始化过程,完成的是对网卡的配置与启动。
另外,由于sys_socketcall()是内核为socket设置的总入口,这里我们没有对__sys_socket设置断点,因此只捕获到sys_socketcall()。
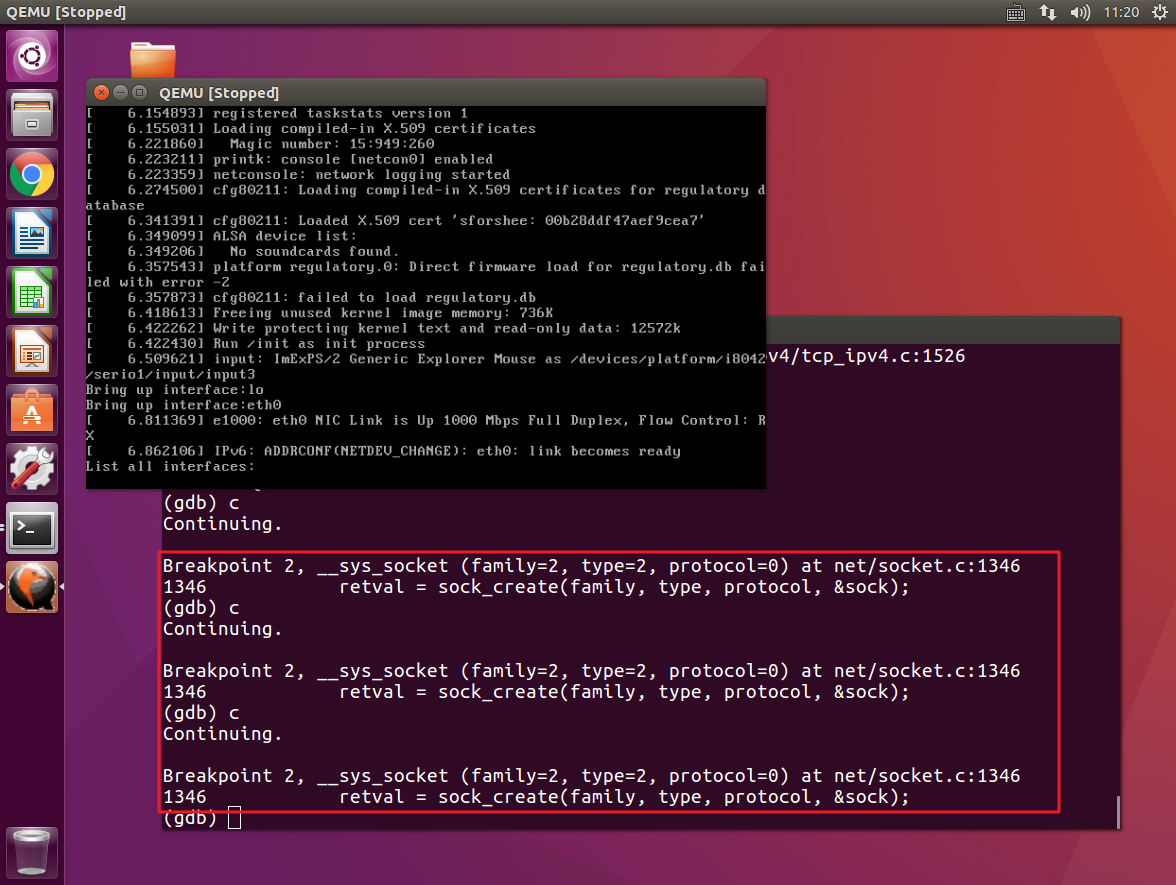
接着,与我们之前的实验一样,在第一次gdb调试界面停止时我们输入replyhi命令,输入命令之后,gdb调试继续。并且再次捕获断点时可以看到我们捕获到了__sys_socket,即调用了该内核处理函数完成了我们服务器端socket的创建。
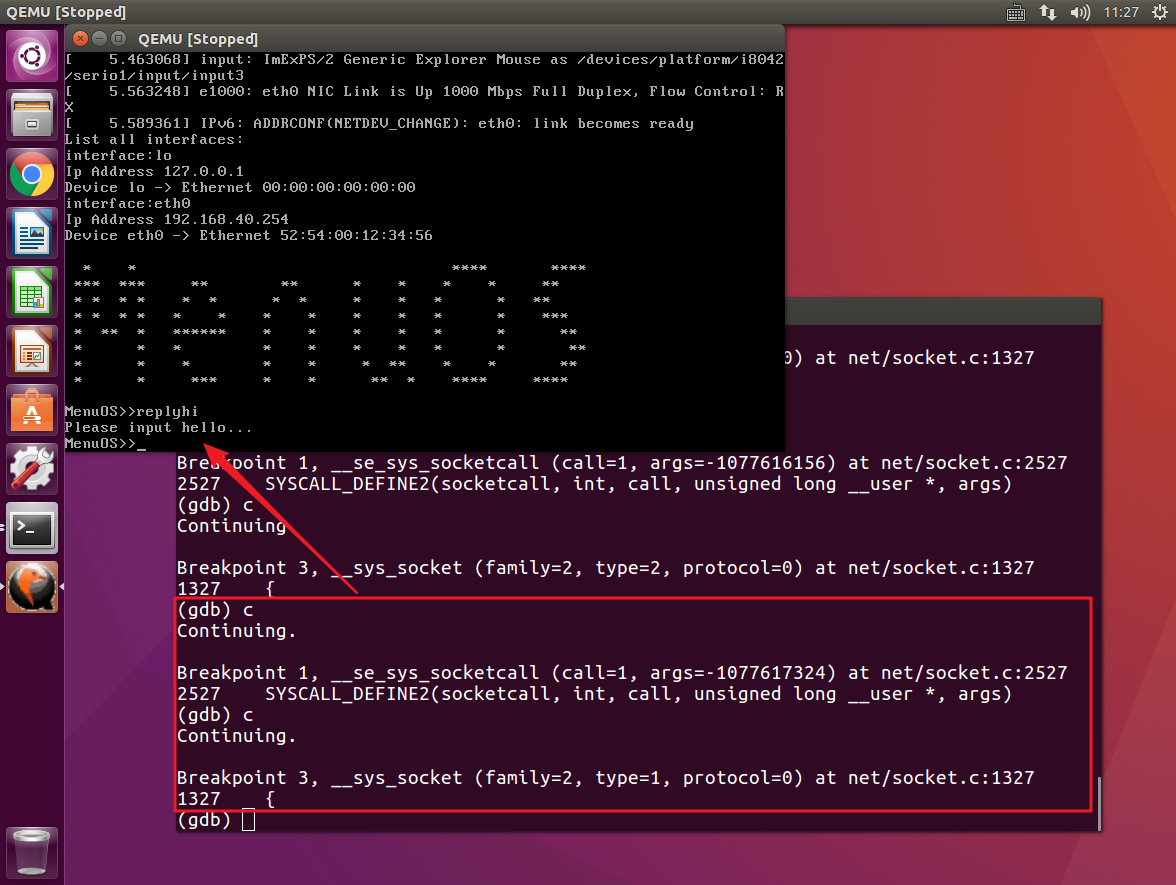
接着往下执行,我们捕获到了__sys_accept4,在qemu虚拟机中输入hello命令,来创建客户端socket。

好了,之前所捕获的系统调用都是连接建立之前所使用到的。
下面我们将捕获TCP三次连接相关的系统调用。
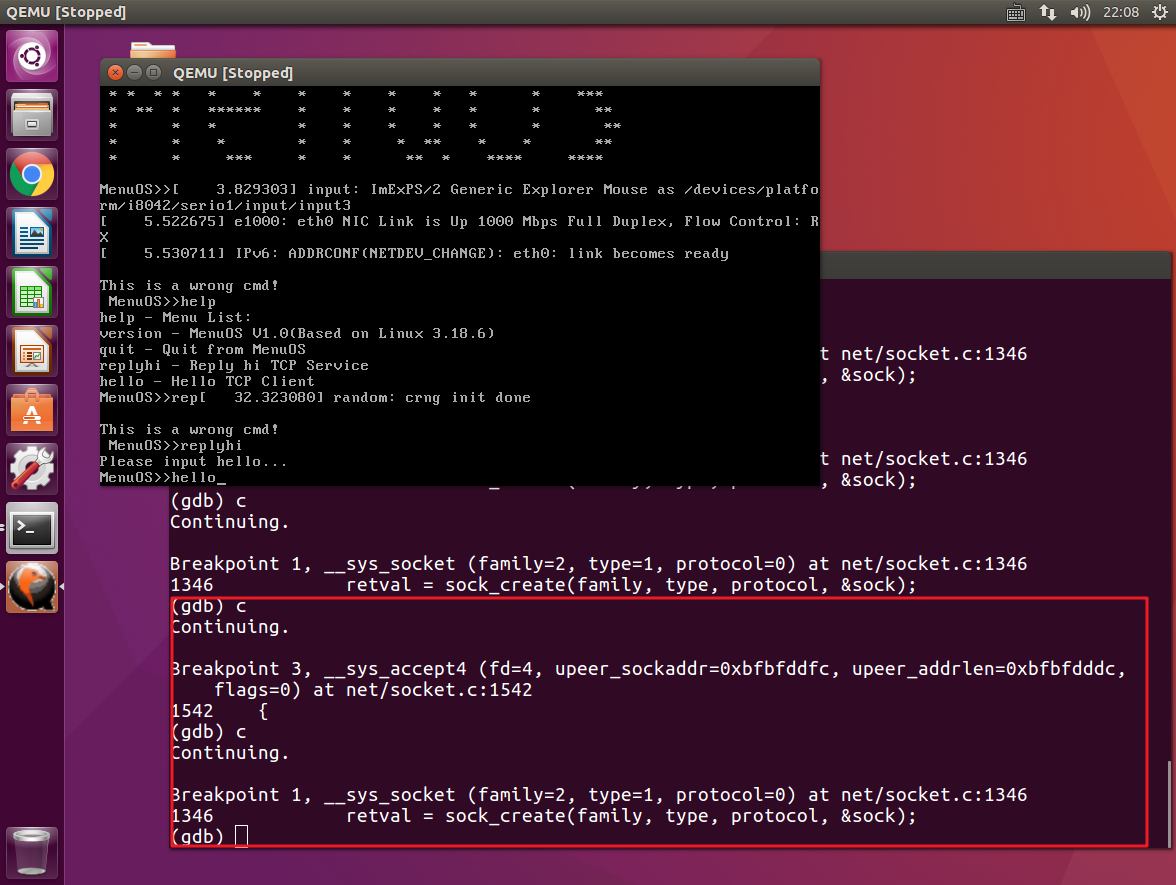
首先,我们捕获到__sys_connect,这一函数我们在之前的实验中已经提到过,它表示客户端已经准备好与服务器连接,将要发出连接请求。
我们所捕获到的下一个是tcp_v4_connect,这就是我们今天所分析的TCP三次握手相关的内容。经过之前的分析,我们知道它所做的工作是调用IP层的服务并构造SYN,准备发送SYN的事宜。
接着,我们捕获到了三次tcp_connect断点,经过之前的分析内容,我们知道该函数所做的是构建一个新的SYN并将其发送出去。
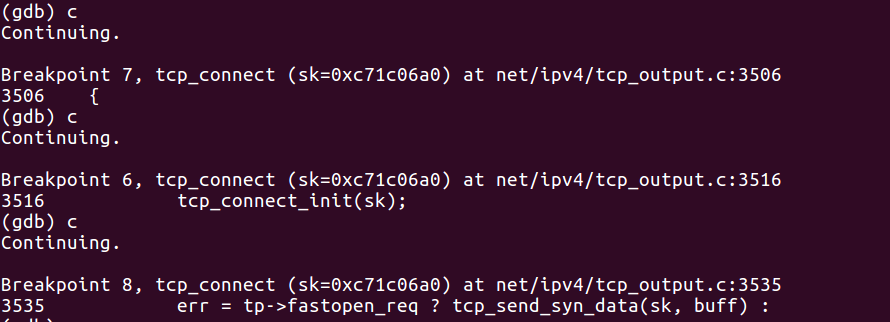
那么,为什么这里会出现三次调用呢?
仔细看gdb调试中所给出断点的详细信息,可以发现这三次调用具体所做的内容都不同。为了搞清它们具体做了什么,我们可以查看一下tcp_connect源码。
/* Build a SYN and send it off. */
int tcp_connect(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *buff;
int err;
tcp_call_bpf(sk, BPF_SOCK_OPS_TCP_CONNECT_CB, 0, NULL);
if (inet_csk(sk)->icsk_af_ops->rebuild_header(sk))
return -EHOSTUNREACH; /* Routing failure or similar. */
tcp_connect_init(sk);
if (unlikely(tp->repair)) {
tcp_finish_connect(sk, NULL);
return 0;
}
buff = sk_stream_alloc_skb(sk, 0, sk->sk_allocation, true);
if (unlikely(!buff))
return -ENOBUFS;
tcp_init_nondata_skb(buff, tp->write_seq++, TCPHDR_SYN);
tcp_mstamp_refresh(tp);
tp->retrans_stamp = tcp_time_stamp(tp);
tcp_connect_queue_skb(sk, buff);
tcp_ecn_send_syn(sk, buff);
tcp_rbtree_insert(&sk->tcp_rtx_queue, buff);
/* Send off SYN; include data in Fast Open. */
err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) :
tcp_transmit_skb(sk, buff, 1, sk->sk_allocation);
if (err == -ECONNREFUSED)
return err;
/* We change tp->snd_nxt after the tcp_transmit_skb() call
* in order to make this packet get counted in tcpOutSegs.
*/
WRITE_ONCE(tp->snd_nxt, tp->write_seq);
tp->pushed_seq = tp->write_seq;
buff = tcp_send_head(sk);
if (unlikely(buff)) {
WRITE_ONCE(tp->snd_nxt, TCP_SKB_CB(buff)->seq);
tp->pushed_seq = TCP_SKB_CB(buff)->seq;
}
TCP_INC_STATS(sock_net(sk), TCP_MIB_ACTIVEOPENS);
/* Timer for repeating the SYN until an answer. */
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
inet_csk(sk)->icsk_rto, TCP_RTO_MAX);
return 0;
}
EXPORT_SYMBOL(tcp_connect);
嗯,这下我们就明白了。
原来,第一次调用我们进入tcp_connect这个函数,表示我们将使用该内核函数来完成客户端SYN的发送;
在第二次调用中,我们所执行的是tcp_connect_init(sk)这段代码,即完成初始化的工作,构建我们将要发送的SYN。
最后一次调用中,我们将构造好的SYN发送给服务器,向服务器发出TCP连接请求,而这里所使用的系统调用就是tcp_transmit_skb(),也就是我们之前没有捕获到的断点。
继续。
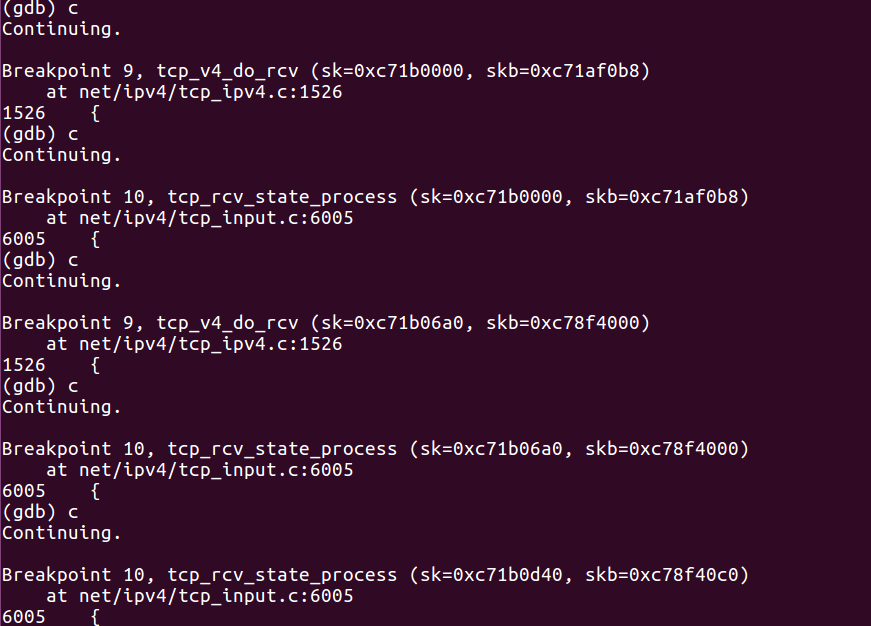
这次我们捕获到了tcp_v4_do_rcv和tcp_rcv_state_process这两个函数。
在之前的服务器端流程分析中,我们知道tcp_v4_do_rcv所完成的工作是接收客户端发来的SYN并发送SYN+ACK。后一个内核函数则是按照TCP状态机将此时服务器的状态修改为SYN-RCVD。
同样的,客户端在收到该消息之后,调用该内核函数来发送ACK消息,并修改客户端的状态。
最后,服务器接收到来自客户端的ACK消息,完成三次握手过程,修改状态为ESTABLISHED
至于如何区分这些操作,我们的依据就是调试信息中的套接字指针sk以及skb信息,根据这些信息我们就能够分辨出哪些是客户端的操作,哪些是服务器的操作。
此后,服务器端就准备开始与客户端之间的数据收发过程。
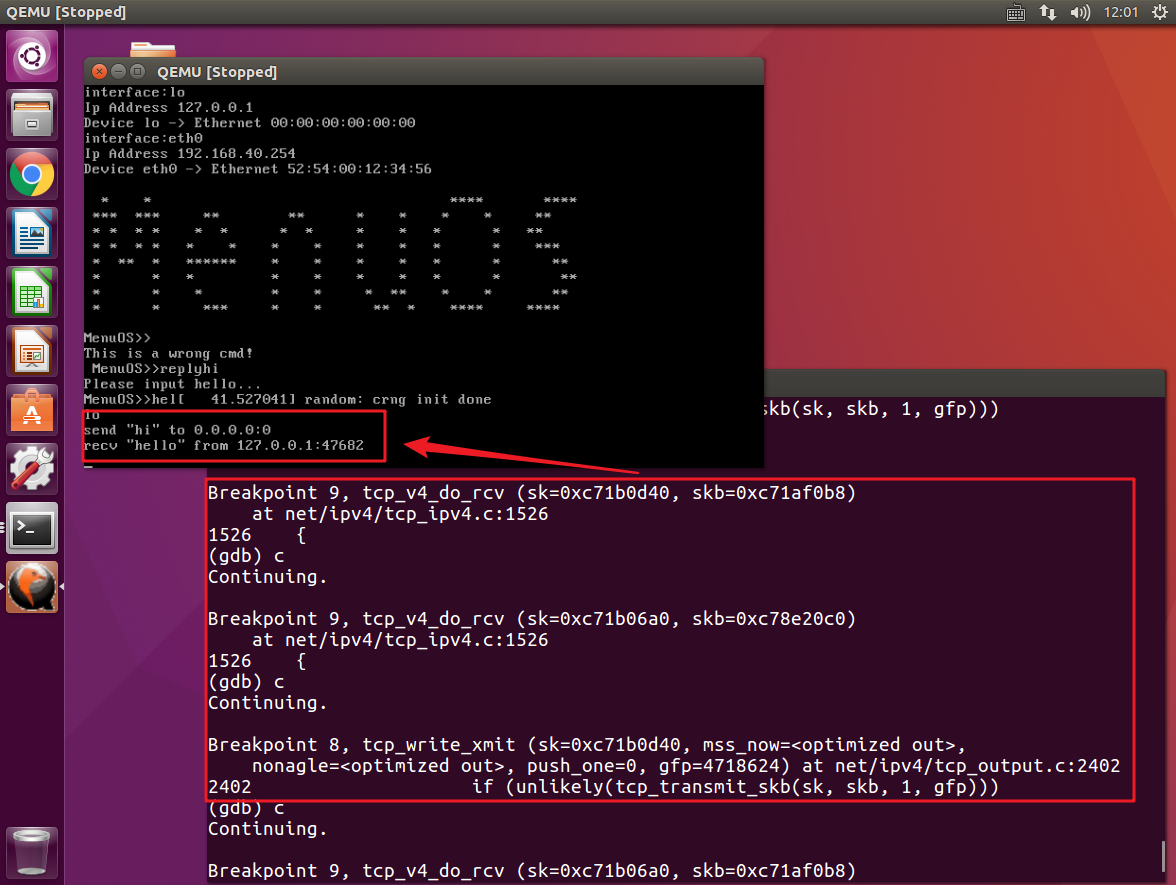
继续向下,这次我们捕获到tcp_write_xmit,它所完成的是将消息传递出去,而此时在Menuos系统中可以看到收发消息的列表,同样证明此时客户端与服务器完成了TCP三次连接,开始与服务器进行消息的发送与接收。
Ok,以上内容就是本次博客分享的全部了,如果有帮助到你,请给我点个推荐吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号