【大数据】爬取网易云《大碗宽面》歌评
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
一、爬取对象
4月19日,吴亦凡在网上发布了一首新歌,这首歌的名字非常有意思,叫做《大碗宽面》,这首歌《大碗宽面》其实是之前一直被大家恶搞的梗,是吴亦凡在参加综艺《72层奇楼》是说的“你看着面它又长又宽,就像这碗它又大又圆”之后吴亦凡还被做成了各种各样的表情包。没想到如今竟被本尊拿出来调侃了,时隔两年,吴亦凡将自己的 “黑梗” 写成歌,既娱乐了大众,又表达了自己的立场和态度。


二、数据爬取
2.1 爬取配置
爬虫部分主要是调用官方API,本次用到的API主要有两个:
获取评论:
http://music.163.com/api/v1/resource/comments/R_SO_4_{歌曲ID}?limit={每页限制数量}&offset={评论数总偏移}
获取评论对应用户的信息:
https://music.163.com/api/v1/user/detail/{用户ID}
# -*- coding:utf-8 -*- import re SONGID = '1359595520' SONGNAME = '大碗宽面' LIMIT_NUM = 100 PATTERN = re.compile(r'[\n\t\r\/]') #替换掉评论中的特殊字符以防插入数据库时报错
#数据库配置 DATABASE = 'music' TABLE_COMMENTS = 'comment' TABLE_USERS = 'user' HOST = 'localhost' USER = 'root' PASSWD = '123456' ROOT_USER_URL = 'https://music.163.com/api/v1/user/detail/' ROOT_COMMENT_URL = 'http://music.163.com/api/v1/resource/comments/R_SO_4_'+SONGID+'?limit='+str(LIMIT_NUM)+'&offset=%s' HEADERS = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36', 'Host': 'music.163.com', 'Cookie': '', } #代理ip
PROXIES = [{'http':'119.191.79.46:80'},{'http':'103.40.48.193:82'},{'http':'47.94.173.121:9876'},{'http':'120.78.145.111:80'},
{'http':'47.93.114.82:3128'},{'http':'103.228.142.152:8080'},{'http':'218.89.14.142:8060'},{'http':'117.191.11.71:80'},
{'http':'123.120.193.42:8060'},{'http':'116.209.57.190:9999'},{'http':'110.52.235.248:9999'},{'http':'119.180.139.54:8060'},
{'http':'61.183.233.6:54896'},{'http':'123.117.179.134:8060'},{'http':'39.137.69.7:8080'},{'http':'120.77.170.64:8080'}]
2.2代理地址有效性验证
用于验证代理ip是否能访问目标地址:
import requests import config for ip in config.PROXIES: try: requests.get('https://music.163.com/', proxies=ip) except: print('connect failed') else: print('success')
2.3 评论爬取
# -*- coding=utf-8 -*- import json import random from datetime import datetime import requests import config import pymysql import gevent from gevent import monkey monkey.patch_all() class Crawler(object): def run(self, url): print('crawl ', url) self.parse_page(url) def down(self,url): try: return requests.get(url=url, headers=config.HEADERS,proxies=random.choice(config.PROXIES)).text except Exception as e: print('down err>>>', e) def parse_page(self, url): content = self.down(url) js = json.loads(content) datas = [] for c in js['comments']: data = {} try: data['commentId'] = c['commentId'] data['content'] = config.PATTERN.sub('', c['content']) data['likedCount'] = int(c['likedCount']) data['time'] = datetime.fromtimestamp(c['time']//1000) data['userId'] = c['user']['userId'] datas.append(data) except Exception as e: print('解析js出错>>>', e) self.save(datas) def save(self, datas): conn = pymysql.connect(host=config.HOST, user=config.USER, passwd=config.PASSWD, db=config.DATABASE, charset='utf8mb4') # 注意字符集要设为utf8mb4,以支持存储评论中的emoji表情 cursor = conn.cursor() sql = 'insert into '+config.TABLE_COMMENTS+' (commentId,content,likedCount,time,userId,songId,songName) VALUES (%s,%s,%s,%s,%s,%s,%s)' for data in datas: try: # cursor.execute('SELECT max(id) FROM '+config.TABLE_COMMENTS) # s = cursor.fetchone()[0] # if s: # id_ = s+1 # else: # id_ = 1 cursor.execute(sql, (data['commentId'], data['content'], data['likedCount'], data['time'], data['userId'], config.SONGID,config.SONGNAME)) conn.commit() except Exception as e: print('存储错误>>>', e) cursor.close() conn.close() def main(self, pages): url_list = [config.ROOT_COMMENT_URL%(num*config.LIMIT_NUM) for num in range(0, pages//config.LIMIT_NUM+1)] job_list = [gevent.spawn(self.run, url) for url in url_list] gevent.joinall(job_list) def getTotal(): try: req = requests.get(config.ROOT_COMMENT_URL%(0), headers=config.HEADERS,proxies=random.choice(config.PROXIES)).text js = json.loads(req) return js['total'] except Exception as e: print(e) return None if __name__=="__main__": total = getTotal() spider = Crawler() spider.main(total)
爬取的用户评论数据:
1.4 用户信息爬取
单线程爬取网易云音乐用户信息并存储进数据库。根据获取用户信息的API,请求URL有1个可变部分:用户ID,前一部分已经将每条评论对应的用户ID也存储下来,这里只需要从数据库取用户ID并抓取信息即可:
# -*- coding:utf8 -*- import random import requests import json import pymysql import config import re # 数据表设计如下: ''' id(int) userId(varchar) gender(char) userName(varchar) age(int) level(int) city(varchar) sign(text) eventCount(int) followedCount(int) followsCount(int) recordCount(int) avatar(varchar) ''' PATTERN = re.compile(r'[\n\t\r\/]') # 替换掉签名中的特殊字符以防插入数据库时报错 def getData(url): if not url: return None print('Crawling>>> ' + url) try: # req = request.Request(url, headers=headers) # content = request.urlopen(req).read().decode("utf-8") # js = json.loads(content) req = requests.get(url, headers=config.HEADERS,proxies=random.choice(config.PROXIES)).text js = json.loads(req) data = {} if js['code'] == 200: data['userId'] = js['profile']['userId'] data['userName'] = js['profile']['nickname'] data['avatar'] = js['profile']['avatarUrl'] data['gender'] = js['profile']['gender'] if int(js['profile']['birthday'])<0: data['age'] = 0 else: data['age'] =(2019-1970)-(int(js['profile']['birthday'])//(1000*365*24*3600)) if int(data['age'])<0: data['age'] = 0 data['level'] = js['level'] data['sign'] = PATTERN.sub(' ', js['profile']['signature']) data['eventCount'] = js['profile']['eventCount'] data['followCount'] = js['profile']['follows'] data['fanCount'] = js['profile']['followeds'] data['city'] = js['profile']['city'] data['recordCount'] = js['listenSongs'] except Exception as e: print('Down err>>> ', e) pass return data def saveData(data): if not data: return None conn = pymysql.connect(host='localhost', user=config.USER, passwd=config.PASSWD, db=config.DATABASE, charset='utf8mb4') # 注意字符集要设为utf8mb4,以支持存储签名中的emoji表情 cursor = conn.cursor() sql = 'insert into ' + config.TABLE_USERS + ' (userName,gender,age,level,city,sign,eventCount,followCount,fanCount,recordCount,avatar,userId) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)' try: cursor.execute(sql, (data['userName'],data['gender'],data['age'],data['level'],data['city'],data['sign'],data['eventCount'],data['followCount'],data['fanCount'],data['recordCount'],data['avatar'],data['userId'])) conn.commit() except Exception as e: print('mysql err>>> ',data['userId'],e) pass finally: cursor.close() conn.close() def getID(): conn = pymysql.connect(host='localhost', user=config.USER, passwd=config.PASSWD, db=config.DATABASE, charset='utf8mb4') cursor = conn.cursor() sql = 'SELECT userId FROM '+config.TABLE_COMMENTS try: cursor.execute(sql) res = cursor.fetchall() return res except Exception as e: print('get err>>> ', e) pass finally: cursor.close() conn.close() return None if __name__ == '__main__': usersID = getID() for i in usersID: data = getData(config.ROOT_USER_URL+i[0].strip()) saveData(data)
爬取的用户信息数据:
三、数据分析
3.1 用户信息分析
# -*- coding:utf8 -*-
import pandas as pd
import numpy as np
import pymysql
from pyecharts import Bar, Pie, Line, Scatter, Map
import config
TABLE_COMMENTS = config.TABLE_COMMENTS
TABLE_USERS = config.TABLE_USERS
DATABASE = config.DATABASE
conn = pymysql.connect(host='localhost', user='root', passwd='123456', db=DATABASE, charset='utf8mb4')
sql_users = 'SELECT id,gender,age,city,level FROM ' + TABLE_USERS
sql_comments = 'SELECT id,time FROM ' + TABLE_COMMENTS
comments = pd.read_sql(sql_comments, con=conn)
users = pd.read_sql(sql_users, con=conn)
# 评论时间(按天)分布分析
comments_day = comments['time'].dt.date.to_frame()
comments_day = users['id'].to_frame().join(comments_day)
data = comments_day.id.groupby(comments_day['time']).count()
line = Line('评论时间(按天)分布')
line.use_theme('dark')
line.add(
'',
data.index.values,
data.values,
is_fill=True,
)
line.render(r'./评论时间(按天)分布.html')
# 评论时间(按小时)分布分析
comments_hour = comments['time'].dt.hour.to_frame()
comments_hour = users['id'].to_frame().join(comments_hour)
data = comments_hour.id.groupby(comments_hour['time']).count()
line = Line('评论时间(按小时)分布')
line.use_theme('dark')
line.add(
'',
data.index.values,
data.values,
is_fill=True,
)
line.render(r'./评论时间(按小时)分布.html')
# 用户年龄分布分析
age = users[users['age'] > 0] # 清洗掉年龄小于1的数据
age = age.id.groupby(age['age']).count() # 以年龄值对数据分组
Bar_age = Bar('用户年龄分布')
Bar_age.use_theme('dark')
Bar_age.add(
'',
age.index.values,
age.values,
is_fill=True,
)
Bar_age.render(r'./用户年龄分布图.html') # 生成渲染的html文件
# 用户等级分布分析
level = users[users['level'] > 0] # 清洗掉年龄小于1的数据
level = level.id.groupby(level['level']).count() # 以年龄值对数据分组
Bar_level = Bar('用户等级分布')
Bar_level.use_theme('dark')
Bar_level.add(
'',
level.index.values,
level.values,
is_fill=True,
)
Bar_level.render(r'./用户等级分布图.html') # 生成渲染的html文件
# 用户地区分布分析
# 城市code编码转换
def city_group(cityCode):
city_map = {
'11': '北京',
'12': '天津',
'31': '上海',
'50': '重庆',
'5e': '重庆',
'81': '香港',
'82': '澳门',
'13': '河北',
'14': '山西',
'15': '内蒙古',
'21': '辽宁',
'22': '吉林',
'23': '黑龙江',
'32': '江苏',
'33': '浙江',
'34': '安徽',
'35': '福建',
'36': '江西',
'37': '山东',
'41': '河南',
'42': '湖北',
'43': '湖南',
'44': '广东',
'45': '广西',
'46': '海南',
'51': '四川',
'52': '贵州',
'53': '云南',
'54': '西藏',
'61': '陕西',
'62': '甘肃',
'63': '青海',
'64': '宁夏',
'65': '新疆',
'71': '台湾',
'10': '其他',
}
return city_map[cityCode[:2]]
city = users['city'].apply(city_group).to_frame()
city = users['id'].to_frame().join(city)
city = city.id.groupby(city['city']).count()
map_ = Map('用户地区分布图')
map_.add(
'',
city.index.values,
city.values,
maptype='china',
is_visualmap=True,
visual_text_color='#000',
is_map_symbol_show=False,
is_label_show=True,
)
map_.render(r'./用户地区分布图.html')
评论数时间(按天)分布:
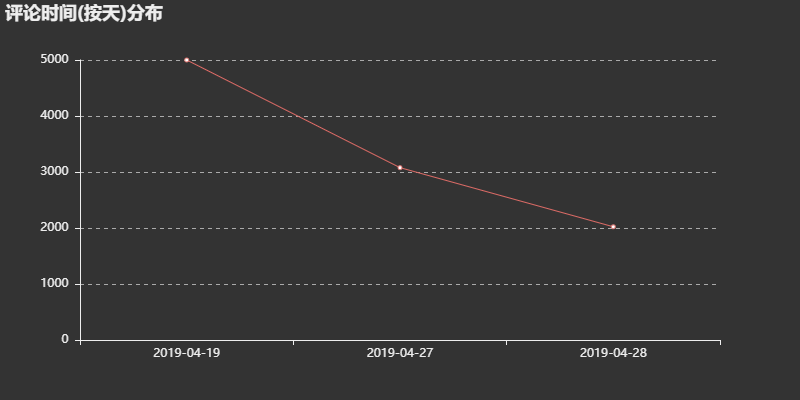
这首歌从2019年4月19号发布,当天的评论数最多,随着时间的递增评论数逐渐减少,但是评论数仍然大于两千,说明这首歌引起了网友们的热议。
评论数时间(按小时)分布:
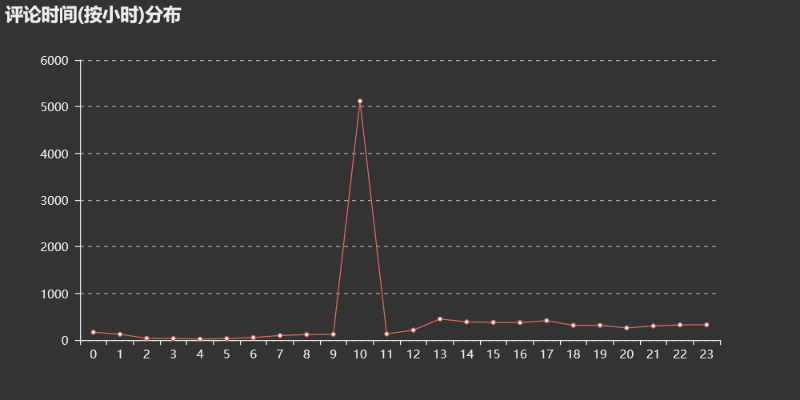
评论数在10点钟突增,据了解,歌手在微博上发布这首歌同样是十点,与4月19号当天的评论数相近,所以大部分评论都集中在歌手刚发布这首歌的时候,通过网络传播极其迅速。
用户年龄分布:
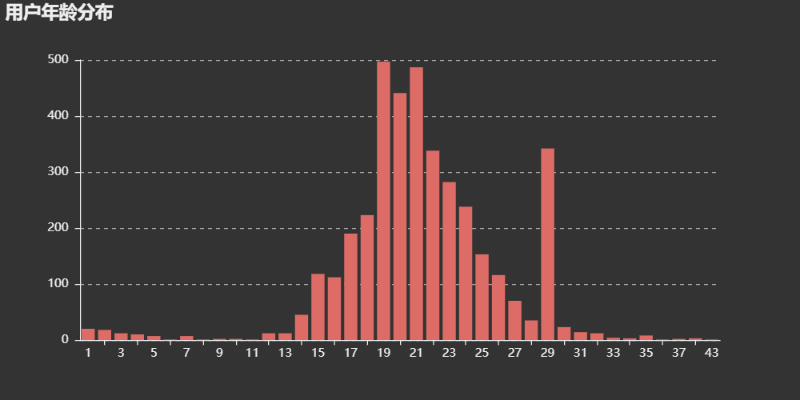
用户年龄分布图可以看出,用户大多集中在14-30岁之间,以20岁左右居多,除去虚假年龄之外,这个年龄分布也符合网易云用户的年龄段。评论这首歌的用户以年轻人居多。
用户地区分布:
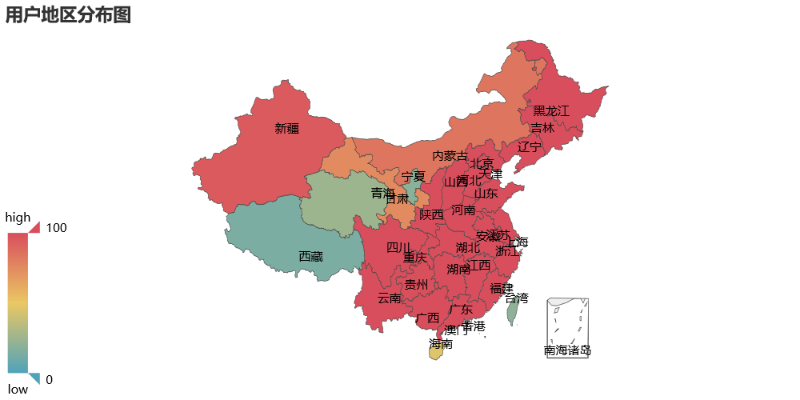
除了西藏、青海、台湾等省份较少,评论用户涵盖了全国各大省份,可以看出这首歌曲已发布就传遍各个地方了。
3.2 用户评论分析
# -*- coding:utf8 -*-
import jieba
import pandas as pd
import pymysql
from wordcloud import WordCloud
import matplotlib.pyplot as plt
TABLE_COMMENTS = 'comment'
DATABASE = 'music'
SONGNAME = '大碗宽面'
def getText():
conn = pymysql.connect(host='localhost', user='root', passwd='123456', db=DATABASE, charset='utf8')
sql = 'SELECT id,content FROM '+ TABLE_COMMENTS
text = pd.read_sql(sql, con=conn)
return text
def getWordcloud(text):
text = ''.join(str(s) for s in text['content'] if s)
word_list = jieba.cut(text, cut_all=False)
stopwords = [line.strip() for line in open(r'./StopWords.txt', 'r',encoding='UTF-8').readlines()] # 导入停用词
clean_list = [seg for seg in word_list if seg not in stopwords] # 去除停用词
clean_text = ''.join(clean_list)
# 生成词云
cloud = WordCloud(
font_path=r'C:/Windows/Fonts/msyh.ttc',
background_color='white',
max_words=800,
max_font_size=64
)
word_cloud = cloud.generate(clean_text)
# 绘制词云
plt.figure(figsize=(12, 12))
plt.imshow(word_cloud)
plt.axis('off')
plt.show()
if __name__ == '__main__':
text = getText()
getWordcloud(text)
生成的词云如下:

在词云图中可以看到,除了一些表情例如呲牙、憨笑等之外,出现比较多的是蔡徐坤、吴亦凡、公鸡、太美、好听等字眼,网友喜欢通过这首歌对两位明星进行对比;从对不起、加油等字眼可以看出对这位歌手的态度有所转变了;从碗又大又圆、看面、吃饭来看,咱也不敢说,咱也不敢问,宽面确实挺好吃!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号