SQL Server用错关联方式
SQL Server中不少怪异问题都是由用错关联方式引起的,从2000到2005有所改善,但2005的查询优化引擎还是存在“犯傻”的时候
1. 问题1
现象:一个存储过程,通过一个服务程序调用,长时间不能结束,数据库服务器显示该存储过程执行到某个语句时一直等待在那,数据库服务器内存充足,CPU消耗几乎没有。把这个存储过程拿出来直接在查询分析器中执行,参数跟程序调用时完全类似,立即结束且结果正确
解决方案:排除了阻塞等原因,因为放在查询分析器中执行时一切正常,从执行计划等方面无法看出任何问题,也排除了磁盘IO等方面的原因,实在想不到其他的了。最后怀疑是SQL Server查询引擎JOIN方式选的不对,强制使用HASH JOIN后,程序调用恢复正常
疑点:一直没有发现程序调用与直接使用查询分析器执行,这2者之间存在哪些差别,会影响到SQL Server查询优化决策
2. 问题2
现象:一个不算复杂的查询,用到了row_number函数分页,一执行就会导致服务器8个CPU全部100%,很长时间(好几分钟)不能结束。使用临时表实现同样的效果,几秒钟完成
语句1:
SELECT
ROW_NUMBER() OVER(ORDER BY COLUMNNAME1 ASC) as FC_ROWNUMBER
,COUNT(1) OVER() AS FC_COUNT
,* FROM (
SELECT 产品 as COLUMNNAME1,产品描述 as COLUMNNAME2,入库日期 as COLUMNNAME7,预期数量 as COLUMNNAME8
,入库数量 as COLUMNNAME9,行状态 as COLUMNNAME10,供应商 as COLUMNNAME11,供应商名称 as COLUMNNAME12
FROM V_收货明细查询
where 入库日期 >= '2010-7-1'
) TT_MAINKEY_TMP
执行计划:
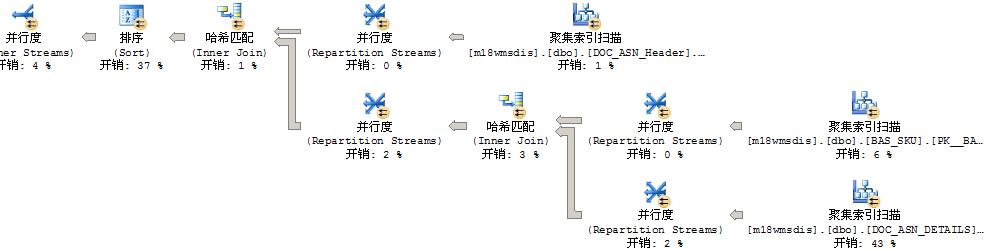
语句2:
SELECT * FROM (
SELECT
ROW_NUMBER() OVER(ORDER BY COLUMNNAME1 ASC) as FC_ROWNUMBER
,COUNT(1) OVER() AS FC_COUNT
,* FROM (
SELECT 产品 as COLUMNNAME1,产品描述 as COLUMNNAME2,入库日期 as COLUMNNAME7,预期数量 as COLUMNNAME8
,入库数量 as COLUMNNAME9,行状态 as COLUMNNAME10,供应商 as COLUMNNAME11,供应商名称 as COLUMNNAME12
FROM V_收货明细查询
where 入库日期 >= '2010-7-1'
) TT_MAINKEY_TMP
) TT_RET_TMP
WHERE FC_ROWNUMBER BETWEEN 1 AND 1000
ORDER BY COLUMNNAME1 ASC
执行计划:
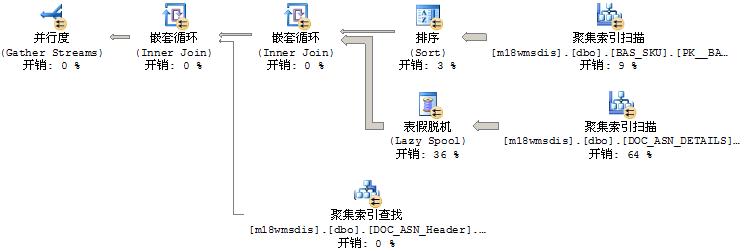
仅仅是把SQL作为一个子查询,在外面多包装了一下,整个查询计划就不一样了。排除了统计信息不准确、索引碎片等状况
2个查询计划中对3个表使用的都是聚集索引扫描,基本上就是关联算法不一样
因为用的并行查询,三个表数据都有几十万和一百多万,嵌套循环需要执行几十万次,所以单个查询导致所有CPU都100%。估计高CPU是由于Lazy Spool操作造成的
解决方案:
强制用HASH JOIN,或者加索引避免SQL Server出错,或者用临时表绕过去
1. 问题1
现象:一个存储过程,通过一个服务程序调用,长时间不能结束,数据库服务器显示该存储过程执行到某个语句时一直等待在那,数据库服务器内存充足,CPU消耗几乎没有。把这个存储过程拿出来直接在查询分析器中执行,参数跟程序调用时完全类似,立即结束且结果正确
解决方案:排除了阻塞等原因,因为放在查询分析器中执行时一切正常,从执行计划等方面无法看出任何问题,也排除了磁盘IO等方面的原因,实在想不到其他的了。最后怀疑是SQL Server查询引擎JOIN方式选的不对,强制使用HASH JOIN后,程序调用恢复正常
疑点:一直没有发现程序调用与直接使用查询分析器执行,这2者之间存在哪些差别,会影响到SQL Server查询优化决策
2. 问题2
现象:一个不算复杂的查询,用到了row_number函数分页,一执行就会导致服务器8个CPU全部100%,很长时间(好几分钟)不能结束。使用临时表实现同样的效果,几秒钟完成
语句1:
SELECT
ROW_NUMBER() OVER(ORDER BY COLUMNNAME1 ASC) as FC_ROWNUMBER
,COUNT(1) OVER() AS FC_COUNT
,* FROM (
SELECT 产品 as COLUMNNAME1,产品描述 as COLUMNNAME2,入库日期 as COLUMNNAME7,预期数量 as COLUMNNAME8
,入库数量 as COLUMNNAME9,行状态 as COLUMNNAME10,供应商 as COLUMNNAME11,供应商名称 as COLUMNNAME12
FROM V_收货明细查询
where 入库日期 >= '2010-7-1'
) TT_MAINKEY_TMP
执行计划:
语句2:
SELECT * FROM (
SELECT
ROW_NUMBER() OVER(ORDER BY COLUMNNAME1 ASC) as FC_ROWNUMBER
,COUNT(1) OVER() AS FC_COUNT
,* FROM (
SELECT 产品 as COLUMNNAME1,产品描述 as COLUMNNAME2,入库日期 as COLUMNNAME7,预期数量 as COLUMNNAME8
,入库数量 as COLUMNNAME9,行状态 as COLUMNNAME10,供应商 as COLUMNNAME11,供应商名称 as COLUMNNAME12
FROM V_收货明细查询
where 入库日期 >= '2010-7-1'
) TT_MAINKEY_TMP
) TT_RET_TMP
WHERE FC_ROWNUMBER BETWEEN 1 AND 1000
ORDER BY COLUMNNAME1 ASC
执行计划:
仅仅是把SQL作为一个子查询,在外面多包装了一下,整个查询计划就不一样了。排除了统计信息不准确、索引碎片等状况
2个查询计划中对3个表使用的都是聚集索引扫描,基本上就是关联算法不一样
因为用的并行查询,三个表数据都有几十万和一百多万,嵌套循环需要执行几十万次,所以单个查询导致所有CPU都100%。估计高CPU是由于Lazy Spool操作造成的
解决方案:
强制用HASH JOIN,或者加索引避免SQL Server出错,或者用临时表绕过去

