事务信息系统-并发控制与恢复的理论, 算法与实践-计算模型, 并发控制部分
事务信息系统-并发控制与恢复的理论, 算法与实践
页的存储结构
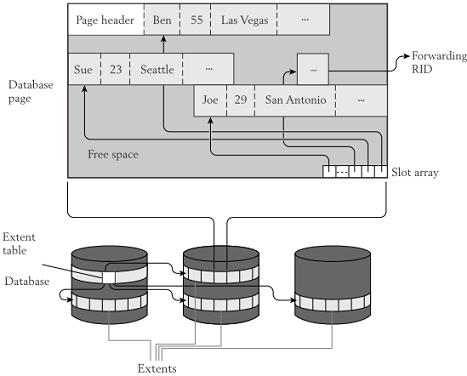
图:数据库页的存储布局页是磁盘与主存间传输数据的最小单元,也是内存中进行缓存的单元
页头(page header)包含页内空间管理的一些信息,比如空闲空间字节数、最大空闲区域大小等
页槽Slot Array的作用:
varchar等变长类型字段的更新操作等,可能导致记录在页内移动,如果外部直接以数据记录的物理地址进行引用,记录移动时处理非常复杂,所以在中间添加一个隔离层Slot Array。Slot Array中存放页内数据的实际地址,以页号+槽号形成RID,外部均以RID引用数据记录
数据在页内移动时只需要更新Slot Array中的实际地址即可,页间移动可以使用一个Forwarding RID实现,例如上图中的示例
对于包含BLOB等长字段类型的记录,简单技巧可以将列的实际数据存储在其他多个页中,而在记录实际数据位置存储页号列表
一次磁盘IO可以读取一个或多个连续的页,可以一次读取的固定数目的页称作块(block),在数据库理论中块和页等同对待
数据库系统通常以区间(extent)为单位预先分配磁盘空间(一次预先分配一个或多个区间),区间是多个连续页。注意区间和块的区别
存储层需要保存必要的元数据,例如将页号转换成物理磁盘地址、空闲空间管理等。通常使用区间表(extent table)来完成页号与物理磁盘地址的转换
计算模型 Computational Models
页模型page model
也称作读写模型read/write model,是一种简单模型。例如事务t使用页模型定义类似如下:t=r(x)w(x)r(y)r(u)w(y),其中r表示读取数据页,w表示写数据页,对于存储层而言一个事务就是这样一个读写序列或偏序
页模型通过简明优雅的方式抓住并发控制与恢复的实质,可以描述很多系统实现中的重要问题,局限在于仅以低层页的读写操为元素,没有表达数据访问操作的语义
对象模型object model
对象模型在页模型的基础上考虑高层操作,在对象模型中事务由ADT(abstract data type)操作构成,最终仍归于低层页的读写
下面是一个对象模型示例图:

图:对象模型示例示例场景说明如下:
* 事务t1中先执行一个select语句,找出住在城市Austin的人员,然后执行一条insert语句,插入一条住在城市Austin的人员信息
* 假设表中只有一个索引,位于城市这个字段,使用的B+ tree结构,索引结构只有2层
ADT操作以及页的读写说明如下:
1. Search('Austin'): select语句使用城市的索引查找符合Austin的索引项,得到RID列表
* r(r): 读取B+ tree索引根节点页
* r(l): 读取B+ tree索引叶节点页
2. Fetch(x), Fetch(y): 根据RID列表加载数据x、y所在的数据页,得到数据记录x、y
* r(p), r(q): 分别读取RID x和y所在的数据页p和q
3. Store(z): 插入记录z
* r(f): 读取存储层的元数据页f,其中记录了空闲空间信息
* r(p): 从页f上得到页p具有足够空间插入记录z,这里读取这个页p
* w(p): 把记录z写入页p,并将页p写回磁盘
* r(r), r(l), w(l): 更新城市字段的索引,读取索引根节点页r、叶节点页l,更新叶节点页l并写回磁盘
对象模型事务t是一棵树,用事务标识符标记根节点,用被调用的操作名称、参数标记非叶节点,用页模型的读写操作标记叶节点
如果将事务的操作序列看成全序,则这个事务只能串行执行;如果将其看作偏序,则其中某些操作可以并行执行
经典并发问题
脏读dirty-read、不一致读inconsistent-read、幻象读phantom-read参考Transaction, Lock, Isolation Level
更新丢失lost-update:

图:丢失更新问题
页模型上的并发控制 - 调度协议
页模型的可串行性理论有终态可串行性、视图可串行性、冲突可串行性等,由于判定终态可串行性和视图可串行性的复杂度太高,因此商业数据库基本都采用冲突可串行性CSR类进行判定
概念:
历史history:指一个完整、已经结束的事务,即事务要么使用commit提交了,要么使用abort终止了
调度schedule:指未完成的事务,即历史的一个前缀
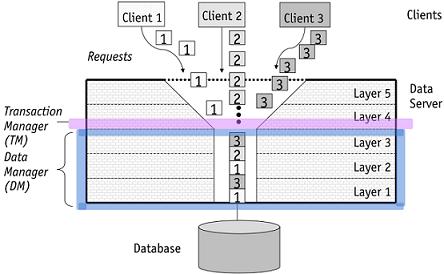
图:Transaction Scheduler图:事物调度器 Transaction Scheduler
client 1、client 2等代表不同事物的操作序列
事务管理器TM主要任务是事物登记,管理trans、commit、abort、active列表,维护ready-to-execute列表等
调度器从TM接收输入调度,将其转化为可串行化的输出调度
调度器分为乐观的、悲观的
死锁处理
一般基于等待图waits-for graph WFG概念,WFG中存在环路时即发生死锁
死锁检测:持续检测continuous detection、周期检测periodic detection
死锁处理方法一:允许发生死锁,从死锁中选出牺牲者消除WFG环路;处理方法二:死锁预防,即不允许死锁情况发生
两阶段封锁协议 - two-phase locking protocol - 2PL
对每个事物,加锁阶段严格区别于紧接着的释放阶段,该封锁协议就是两阶段的
即可以明确的将事务分成前后两个部分,在前面部分只存在加锁,不存在锁释放,而在后面部分则只存在锁释放操作,没有加锁操作。商业数据库考虑性能问题不会严格按照2PL协议实现。SQL92不同的隔离级别本身就是性能与可串行性之间的一个取舍平衡,另外页模型并没有考虑到语义方面,商业数据库部分结合语义方面之后也能对封锁协议进行改造优化以换取性能
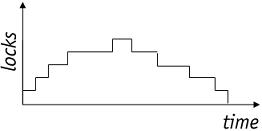
图:2PL下锁增长和缩减阶段示意图图:2PL下锁增长和缩减阶段示意图
2PL协议具有C2PL、S2PL、SS2PL几种变体
下面是一个2PL调度器的调度示例:
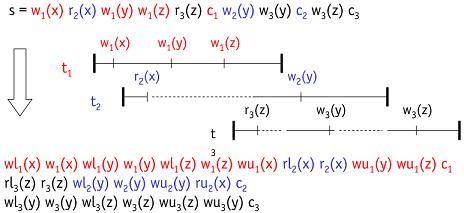
图:调度示例图:2PL调度器调度示例
顶部的s是输入,底部3行是经过2PL调度器的一种可行的输出
下表1、2、3等表示不同的事物t1、t2、t3等,wl表示加写锁,wu表示释放写锁,rl表示加读锁,ru表示释放读锁,c表示事物结束(commit)
中间部分锁的持有时序图中,虚线部分表示锁冲突时的等待时间
保守2PL - Conservative 2PL - C2PL
在事物开始时对所有需要访问的数据获取锁。这个协议只能在有限的应用场景下使用,他不存在死锁问题,因为事物要么等待不能开始,要么就已经得到了全部所需的锁了
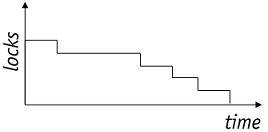
图:C2PL下锁增长和缩减阶段示意图图:C2PL下锁增长和缩减阶段示意图
严格2PL - Strict 2PL - S2PL
事物一直持有已经获得的所有写锁,直到事物终止
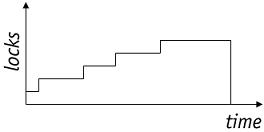
图:S2PL下锁增长和缩减阶段示意图图:S2PL下锁增长和缩减阶段示意图(假设事物中的锁都是写锁)
强2PL - Strong 2PL - SS2PL
事物获得的所有锁(包括读锁和写锁)被一直保持直到事物终止。这种情况下锁的增长和缩减阶段与S2PL相同,不过不局限于写锁
有序共享2PL - Ordered Sharing 2PL - O2PL
在2PL中,如果对同一个数据项申请的锁,与这个数据项上面已经存在的锁不相容时,就只能等待
有序共享相容性规则:同一个数据项上的两个锁无论是否冲突,只要锁操作与相应的数据操作均以相同的顺序执行就可以被不同事物同时持有。这个规则以固定的顺序对数据项进行操作为前提,从而放宽了锁相容性规则,理论上证明是可行的,但他必须强制数据访问的顺序,需要额外的数据结构和运行时代价,实际中比较少采用
利他锁 - Altruistic Locking - AL
是2PL的一种扩展协议。某些事物时间可能很长,持有大量的锁,这样可能阻塞大量其他短事物。如果短事物访问的仅仅是长事物已经处理过的数据项的子集,则长事物将这部分数据项捐赠给其他事物访问
非两阶段封锁协议
有只写封锁树 write-only tree locking WTL、读写封锁树read/write tree locking RWTL等,他们只能在对数据项的访问遵从特定的顺序的情况下使用,比如对数据项的访问呈树状方式
WTL在封锁规则的基础上添加了两条附加规则:只有在持有父项数据写锁的情况下,才能获取子项数据的写锁;事物对释放某个数据项的写锁之后,不能在获得该数据项的写锁。这确保了数据更新处理将沿着树的某一路径从根节点向叶节点进行,锁的范围可以限制在某个子树范围内。锁的申请和释放并不是两阶段的,沿着数的路径向子树进行时,父项的锁可以释放,即锁的申请和释放可以交替进行
WTL协议是无死锁的,对RWTL协议规则稍作修改可以导出DAG封锁协议DAG locking protocol
时间戳排序协议 - timestamp ordering protocol - TO
不使用封锁,基本规则是对不同事物冲突的操作,严格按照事物开始时间的先后关系进行调度
在封锁协议中通过锁机制检测冲突,在TO中也需要有额外的信息用于检测冲突。例如Ti在Tj之前开始,调度器先对Tj输出了一个调度qj(x),但后来 Ti发送过来一个pi(x)的操作,与qj(x)冲突(即按照TO规则,pi(x)必须在qj(x)之前执行,但在pi(x)之前qj(x)已经被调度输出了),所以调度器需要记录信息以检测这种冲突并作出相应处理(例如阻塞Ti,等待Tj结束后再开始)
SGT协议 - Serialization Graph Tester - 可串行化图检测器
维护一张SGT图,图中并发的每个事物拥有一个节点,事物Ti的操作与Tj冲突,如果Tj中发生冲突的操作已经输出了,则由Tj向Ti添加一条有向边,Ti进入等待状态。如果事物Ti的某个操作导致SGT图中存在环路,则输出是不可串行化的,事物Ti需要取消
实际中SGT协议需要维护的额外数据量以及运算量都比较大,对于调度器而言无法接收,所以很少采用
对象模型上的并发控制,搜索结构上的并发控制
......
多版本并发控制 - multiversion concurrency control
单版本时数据库中的每个数据项只有一个副本,而多版本时则会为数据项同时维护多个版本,而多版本对于client是透明的,对client而言数据库仍然只维护了数据项的一个副本。通过对并发控制算法的扩展调整,多版本同样可以达到可串行性目标,他仅仅是并发控制的另一种处理方式。他的优点是可以降低封锁协议中锁的使用,极大的提高并发处理性能,并给数据恢复等方面带来好处
多版本时间戳排序协议 - multiversion timestamp ordering protocol - MVTO
本质上类似FIFO方式处理并发操作。每个事物按照事物开始时的时间戳排序,基于这个顺序处理调度和冲突
下面对的规则描述中,Ti表示第i个事物;ts(Ti)表示第i个事物的时间戳;Ri(X)表示Ti读取数据项X;Xk则表示数据项X的某一个版本,他是由事物Tk写入的;ts(Xk)表示数据项的Xk这个版本的时间戳,他就是事物Tk的时间戳,即ts(Xk)=ts(Tk)。下面是MVTO规则:
1. Ri(X)将被转化为Ri(Xk),即需要明确读取数据项X的哪一个版本,其中Xk应该为ts(Xk)<ts(Ti)的一个最新版本。另外Xk可能是已提交的版本,也可能是未提交的版本
2. 处理Wi(X)时,如果已经存在一个Rj(Xk)操作,并且时间戳关系为ts(Xk)<ts(Ti)<ts(Tj),则Wi(X)被拒绝,Ti将被取消,因为这样存在冲突,将造成不可串行化的结果。否则,Wi(X)被转化为Wi(Xi)并执行,即为数据项X生成一个新的版本Xi
3. 可选规则:延迟提交。这是在不允许脏读的情况下用来避免产生脏读的一个机制。如果事物Ti读取了Tj写入的某个数据项,即存在Ri(Xj)操作,则事物Ti的提交操作Ci需要被推迟到事物Tj成功提交之后再执行。如果事物Tj失败则事物Ti也失败(或重做)
下面是MVTO协议下的一个执行示例,可以使用上面的规则进行解释:
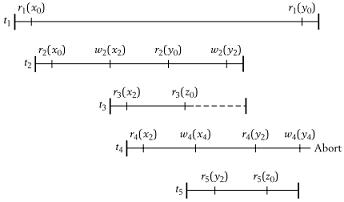
图:MVTO协议下的执行示例
* 事物t3中因为存在r3(x2)操作,即读取了x2这个未提交的版本(按照规则1,他应该读取x2的),所以他的提交被延迟(虚线表示等待),在t2提交之后再提交
* t4被终止是因为规则2的作用,因为t5中存在r5(y2)这个操作,如果让w4(y4)成功,则事物t5可能出现不一致读的情况,不是一个可串行化的调度。图来自原书,图中应该有个错误,r5(y2)不可能出现在w2(y2)前面的,他应该位于w2(y2)与w4(y4)之间才对
* 最后看一下t1,在读取y的时候,根据MVTO的规则1,应该读取y0这个版本。这样在没有加锁的情况下实现了事物t1的一致性读,但他并没有利用锁阻塞t2、t4(两阶段封锁协议的情况下他们的写操作与t1的读锁冲突),而是让t2、t4并行执行。根据MVTO规则,t1不能有写x、y的操作,否则按照规则2应该取消t1。这样从理论上看存储层还是可以保证x、y的可串行性结果的,但存在一个疑问是:如果t1有其他写操作,比如 w1(u1),而u1是基于x、y的运算而来,即u1=f0(u)f1(x)f2(y),如何确保数据项u的可串行性结果呢?还有对外部而言t1实现了对 x、y的一致性读,但w2(y2)成功了,外部基于x、y得来的计算结果可能就是一个不正确的值,如何确保一致性?
另外还有多版本两阶段封锁协议 - multiversion 2PL locking protocol - MV2PL、只读多版本协议 - read-only multiversion protocol - ROMV等
暂态版本化 - Transient Versioning
暂态版本化的做法是将数据项的最新版本放在数据记录位置上,数据项以前的旧版本都放在版本池version pool中,版本池可以驻留内存或者磁盘。这样当访问最新版本数据时没有性能损失,版本池也方便对旧版本的垃圾回收。有些系统中把版本池跟用于恢复的日志项合并在一起。版本池也叫做回滚段rollback segment

图:暂态版本化的存储组织图:暂态版本化的存储组织
数据项的每个版本包括两个额外的字段,一个是创建时间戳,另一个是指向前一版本的指针
* 对于新增的数据项,还没有旧版本,因此在当前版本中指针为空,例如图中的1135
* 删除的数据仍然保留在当前版本位置上,但会打上删除标记,例如图中的1141
* 同一个数据项的各个版本组成一个链表
另一种方法是在数据项的当前版本中维护一个小的版本选择表,其中包含每个版本的时间戳以及一个指向该版本位置的指针
如果一个数据项的旧版本再也不会被当前活动的事务使用到,则这些旧版本就成为垃圾,可以被回收掉
关系数据库的并发控制
面向谓词的并发控制 - Predicate-Oriented Concurrency Control
封锁协议是针对页、数据项加锁,而面向谓词的并发控制是针对操作加锁,更具体的是针对操作的谓词加锁。例如:
select name from persons where age>30
则将age>30与锁关联
面向谓词的并发控制是比较早提出来的一种想法,后来也经过了不少研究,他的问题在于检测两个谓词是否兼容是一个NP完全问题,成本太高,但在特定场景下,例如B+树上的并发控制,具有实际意义
实现和实用性问题
通用的锁管理器数据结构
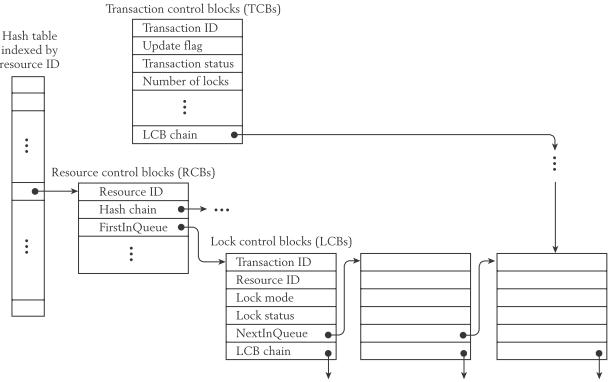
图:锁管理器的数据结构
锁管理器需要达成的目标:
1. 请求锁时可以检验冲突
2. 释放锁时,需要将资源授予被该锁阻塞的其他锁
3. 事务终止时释放该事务的所有锁
锁管理器的数据结构常驻内存,由resource ID索引的哈希表存放已经加锁以及需要加锁的资源ID
每个哈希表项指向一个资源控制块RCB,RCB中的hash chain用于解决hash冲突
对于共享锁,多个锁可以同时被同一资源持有,多个锁请求(例如冲突的写锁)可能正在等待被授予该资源上,这样在同一个资源上将形成一个已持有的共享锁列表以及等待被授予的排他锁与共享锁队列,因此在RCB上会指向一个锁控制块LCB的链接表,即上图中的FirstInQueue, NextInQueue链表
为了达成第3点,为每个活动事务维护一个事务控制块TCB,同样使用链表将该事务的所有锁链接起来,即上图中的LCB chain构成的链表
锁的数据结构将是数据库中访问最频繁的地方之一,因此需要控制这个内存数据结构的大小来避免性能问题,所以一般数据库中存在锁粒度升级的处理方式。如果一个事务已经持有了大量细粒度的行锁,数据库可能会将锁粒度升级为页锁或者表锁,以减小锁管理器的内存空间
使用了不同粒度的锁,就存在不同粒度之间相容性的判断问题,所以引入了意向锁,参考数据库系统 - 面向应用的方法
页的存储结构
图:数据库页的存储布局页是磁盘与主存间传输数据的最小单元,也是内存中进行缓存的单元
页头(page header)包含页内空间管理的一些信息,比如空闲空间字节数、最大空闲区域大小等
页槽Slot Array的作用:
varchar等变长类型字段的更新操作等,可能导致记录在页内移动,如果外部直接以数据记录的物理地址进行引用,记录移动时处理非常复杂,所以在中间添加一个隔离层Slot Array。Slot Array中存放页内数据的实际地址,以页号+槽号形成RID,外部均以RID引用数据记录
数据在页内移动时只需要更新Slot Array中的实际地址即可,页间移动可以使用一个Forwarding RID实现,例如上图中的示例
对于包含BLOB等长字段类型的记录,简单技巧可以将列的实际数据存储在其他多个页中,而在记录实际数据位置存储页号列表
一次磁盘IO可以读取一个或多个连续的页,可以一次读取的固定数目的页称作块(block),在数据库理论中块和页等同对待
数据库系统通常以区间(extent)为单位预先分配磁盘空间(一次预先分配一个或多个区间),区间是多个连续页。注意区间和块的区别
存储层需要保存必要的元数据,例如将页号转换成物理磁盘地址、空闲空间管理等。通常使用区间表(extent table)来完成页号与物理磁盘地址的转换
计算模型 Computational Models
页模型page model
也称作读写模型read/write model,是一种简单模型。例如事务t使用页模型定义类似如下:t=r(x)w(x)r(y)r(u)w(y),其中r表示读取数据页,w表示写数据页,对于存储层而言一个事务就是这样一个读写序列或偏序
页模型通过简明优雅的方式抓住并发控制与恢复的实质,可以描述很多系统实现中的重要问题,局限在于仅以低层页的读写操为元素,没有表达数据访问操作的语义
对象模型object model
对象模型在页模型的基础上考虑高层操作,在对象模型中事务由ADT(abstract data type)操作构成,最终仍归于低层页的读写
下面是一个对象模型示例图:
图:对象模型示例示例场景说明如下:
* 事务t1中先执行一个select语句,找出住在城市Austin的人员,然后执行一条insert语句,插入一条住在城市Austin的人员信息
* 假设表中只有一个索引,位于城市这个字段,使用的B+ tree结构,索引结构只有2层
ADT操作以及页的读写说明如下:
1. Search('Austin'): select语句使用城市的索引查找符合Austin的索引项,得到RID列表
* r(r): 读取B+ tree索引根节点页
* r(l): 读取B+ tree索引叶节点页
2. Fetch(x), Fetch(y): 根据RID列表加载数据x、y所在的数据页,得到数据记录x、y
* r(p), r(q): 分别读取RID x和y所在的数据页p和q
3. Store(z): 插入记录z
* r(f): 读取存储层的元数据页f,其中记录了空闲空间信息
* r(p): 从页f上得到页p具有足够空间插入记录z,这里读取这个页p
* w(p): 把记录z写入页p,并将页p写回磁盘
* r(r), r(l), w(l): 更新城市字段的索引,读取索引根节点页r、叶节点页l,更新叶节点页l并写回磁盘
对象模型事务t是一棵树,用事务标识符标记根节点,用被调用的操作名称、参数标记非叶节点,用页模型的读写操作标记叶节点
如果将事务的操作序列看成全序,则这个事务只能串行执行;如果将其看作偏序,则其中某些操作可以并行执行
经典并发问题
脏读dirty-read、不一致读inconsistent-read、幻象读phantom-read参考Transaction, Lock, Isolation Level
更新丢失lost-update:
图:丢失更新问题
页模型上的并发控制 - 调度协议
页模型的可串行性理论有终态可串行性、视图可串行性、冲突可串行性等,由于判定终态可串行性和视图可串行性的复杂度太高,因此商业数据库基本都采用冲突可串行性CSR类进行判定
概念:
历史history:指一个完整、已经结束的事务,即事务要么使用commit提交了,要么使用abort终止了
调度schedule:指未完成的事务,即历史的一个前缀
图:Transaction Scheduler图:事物调度器 Transaction Scheduler
client 1、client 2等代表不同事物的操作序列
事务管理器TM主要任务是事物登记,管理trans、commit、abort、active列表,维护ready-to-execute列表等
调度器从TM接收输入调度,将其转化为可串行化的输出调度
调度器分为乐观的、悲观的
死锁处理
一般基于等待图waits-for graph WFG概念,WFG中存在环路时即发生死锁
死锁检测:持续检测continuous detection、周期检测periodic detection
死锁处理方法一:允许发生死锁,从死锁中选出牺牲者消除WFG环路;处理方法二:死锁预防,即不允许死锁情况发生
两阶段封锁协议 - two-phase locking protocol - 2PL
对每个事物,加锁阶段严格区别于紧接着的释放阶段,该封锁协议就是两阶段的
即可以明确的将事务分成前后两个部分,在前面部分只存在加锁,不存在锁释放,而在后面部分则只存在锁释放操作,没有加锁操作。商业数据库考虑性能问题不会严格按照2PL协议实现。SQL92不同的隔离级别本身就是性能与可串行性之间的一个取舍平衡,另外页模型并没有考虑到语义方面,商业数据库部分结合语义方面之后也能对封锁协议进行改造优化以换取性能
图:2PL下锁增长和缩减阶段示意图图:2PL下锁增长和缩减阶段示意图
2PL协议具有C2PL、S2PL、SS2PL几种变体
下面是一个2PL调度器的调度示例:
图:调度示例图:2PL调度器调度示例
顶部的s是输入,底部3行是经过2PL调度器的一种可行的输出
下表1、2、3等表示不同的事物t1、t2、t3等,wl表示加写锁,wu表示释放写锁,rl表示加读锁,ru表示释放读锁,c表示事物结束(commit)
中间部分锁的持有时序图中,虚线部分表示锁冲突时的等待时间
保守2PL - Conservative 2PL - C2PL
在事物开始时对所有需要访问的数据获取锁。这个协议只能在有限的应用场景下使用,他不存在死锁问题,因为事物要么等待不能开始,要么就已经得到了全部所需的锁了
图:C2PL下锁增长和缩减阶段示意图图:C2PL下锁增长和缩减阶段示意图
严格2PL - Strict 2PL - S2PL
事物一直持有已经获得的所有写锁,直到事物终止
图:S2PL下锁增长和缩减阶段示意图图:S2PL下锁增长和缩减阶段示意图(假设事物中的锁都是写锁)
强2PL - Strong 2PL - SS2PL
事物获得的所有锁(包括读锁和写锁)被一直保持直到事物终止。这种情况下锁的增长和缩减阶段与S2PL相同,不过不局限于写锁
有序共享2PL - Ordered Sharing 2PL - O2PL
在2PL中,如果对同一个数据项申请的锁,与这个数据项上面已经存在的锁不相容时,就只能等待
有序共享相容性规则:同一个数据项上的两个锁无论是否冲突,只要锁操作与相应的数据操作均以相同的顺序执行就可以被不同事物同时持有。这个规则以固定的顺序对数据项进行操作为前提,从而放宽了锁相容性规则,理论上证明是可行的,但他必须强制数据访问的顺序,需要额外的数据结构和运行时代价,实际中比较少采用
利他锁 - Altruistic Locking - AL
是2PL的一种扩展协议。某些事物时间可能很长,持有大量的锁,这样可能阻塞大量其他短事物。如果短事物访问的仅仅是长事物已经处理过的数据项的子集,则长事物将这部分数据项捐赠给其他事物访问
非两阶段封锁协议
有只写封锁树 write-only tree locking WTL、读写封锁树read/write tree locking RWTL等,他们只能在对数据项的访问遵从特定的顺序的情况下使用,比如对数据项的访问呈树状方式
WTL在封锁规则的基础上添加了两条附加规则:只有在持有父项数据写锁的情况下,才能获取子项数据的写锁;事物对释放某个数据项的写锁之后,不能在获得该数据项的写锁。这确保了数据更新处理将沿着树的某一路径从根节点向叶节点进行,锁的范围可以限制在某个子树范围内。锁的申请和释放并不是两阶段的,沿着数的路径向子树进行时,父项的锁可以释放,即锁的申请和释放可以交替进行
WTL协议是无死锁的,对RWTL协议规则稍作修改可以导出DAG封锁协议DAG locking protocol
时间戳排序协议 - timestamp ordering protocol - TO
不使用封锁,基本规则是对不同事物冲突的操作,严格按照事物开始时间的先后关系进行调度
在封锁协议中通过锁机制检测冲突,在TO中也需要有额外的信息用于检测冲突。例如Ti在Tj之前开始,调度器先对Tj输出了一个调度qj(x),但后来 Ti发送过来一个pi(x)的操作,与qj(x)冲突(即按照TO规则,pi(x)必须在qj(x)之前执行,但在pi(x)之前qj(x)已经被调度输出了),所以调度器需要记录信息以检测这种冲突并作出相应处理(例如阻塞Ti,等待Tj结束后再开始)
SGT协议 - Serialization Graph Tester - 可串行化图检测器
维护一张SGT图,图中并发的每个事物拥有一个节点,事物Ti的操作与Tj冲突,如果Tj中发生冲突的操作已经输出了,则由Tj向Ti添加一条有向边,Ti进入等待状态。如果事物Ti的某个操作导致SGT图中存在环路,则输出是不可串行化的,事物Ti需要取消
实际中SGT协议需要维护的额外数据量以及运算量都比较大,对于调度器而言无法接收,所以很少采用
对象模型上的并发控制,搜索结构上的并发控制
......
多版本并发控制 - multiversion concurrency control
单版本时数据库中的每个数据项只有一个副本,而多版本时则会为数据项同时维护多个版本,而多版本对于client是透明的,对client而言数据库仍然只维护了数据项的一个副本。通过对并发控制算法的扩展调整,多版本同样可以达到可串行性目标,他仅仅是并发控制的另一种处理方式。他的优点是可以降低封锁协议中锁的使用,极大的提高并发处理性能,并给数据恢复等方面带来好处
多版本时间戳排序协议 - multiversion timestamp ordering protocol - MVTO
本质上类似FIFO方式处理并发操作。每个事物按照事物开始时的时间戳排序,基于这个顺序处理调度和冲突
下面对的规则描述中,Ti表示第i个事物;ts(Ti)表示第i个事物的时间戳;Ri(X)表示Ti读取数据项X;Xk则表示数据项X的某一个版本,他是由事物Tk写入的;ts(Xk)表示数据项的Xk这个版本的时间戳,他就是事物Tk的时间戳,即ts(Xk)=ts(Tk)。下面是MVTO规则:
1. Ri(X)将被转化为Ri(Xk),即需要明确读取数据项X的哪一个版本,其中Xk应该为ts(Xk)<ts(Ti)的一个最新版本。另外Xk可能是已提交的版本,也可能是未提交的版本
2. 处理Wi(X)时,如果已经存在一个Rj(Xk)操作,并且时间戳关系为ts(Xk)<ts(Ti)<ts(Tj),则Wi(X)被拒绝,Ti将被取消,因为这样存在冲突,将造成不可串行化的结果。否则,Wi(X)被转化为Wi(Xi)并执行,即为数据项X生成一个新的版本Xi
3. 可选规则:延迟提交。这是在不允许脏读的情况下用来避免产生脏读的一个机制。如果事物Ti读取了Tj写入的某个数据项,即存在Ri(Xj)操作,则事物Ti的提交操作Ci需要被推迟到事物Tj成功提交之后再执行。如果事物Tj失败则事物Ti也失败(或重做)
下面是MVTO协议下的一个执行示例,可以使用上面的规则进行解释:
图:MVTO协议下的执行示例
* 事物t3中因为存在r3(x2)操作,即读取了x2这个未提交的版本(按照规则1,他应该读取x2的),所以他的提交被延迟(虚线表示等待),在t2提交之后再提交
* t4被终止是因为规则2的作用,因为t5中存在r5(y2)这个操作,如果让w4(y4)成功,则事物t5可能出现不一致读的情况,不是一个可串行化的调度。图来自原书,图中应该有个错误,r5(y2)不可能出现在w2(y2)前面的,他应该位于w2(y2)与w4(y4)之间才对
* 最后看一下t1,在读取y的时候,根据MVTO的规则1,应该读取y0这个版本。这样在没有加锁的情况下实现了事物t1的一致性读,但他并没有利用锁阻塞t2、t4(两阶段封锁协议的情况下他们的写操作与t1的读锁冲突),而是让t2、t4并行执行。根据MVTO规则,t1不能有写x、y的操作,否则按照规则2应该取消t1。这样从理论上看存储层还是可以保证x、y的可串行性结果的,但存在一个疑问是:如果t1有其他写操作,比如 w1(u1),而u1是基于x、y的运算而来,即u1=f0(u)f1(x)f2(y),如何确保数据项u的可串行性结果呢?还有对外部而言t1实现了对 x、y的一致性读,但w2(y2)成功了,外部基于x、y得来的计算结果可能就是一个不正确的值,如何确保一致性?
另外还有多版本两阶段封锁协议 - multiversion 2PL locking protocol - MV2PL、只读多版本协议 - read-only multiversion protocol - ROMV等
暂态版本化 - Transient Versioning
暂态版本化的做法是将数据项的最新版本放在数据记录位置上,数据项以前的旧版本都放在版本池version pool中,版本池可以驻留内存或者磁盘。这样当访问最新版本数据时没有性能损失,版本池也方便对旧版本的垃圾回收。有些系统中把版本池跟用于恢复的日志项合并在一起。版本池也叫做回滚段rollback segment
图:暂态版本化的存储组织图:暂态版本化的存储组织
数据项的每个版本包括两个额外的字段,一个是创建时间戳,另一个是指向前一版本的指针
* 对于新增的数据项,还没有旧版本,因此在当前版本中指针为空,例如图中的1135
* 删除的数据仍然保留在当前版本位置上,但会打上删除标记,例如图中的1141
* 同一个数据项的各个版本组成一个链表
另一种方法是在数据项的当前版本中维护一个小的版本选择表,其中包含每个版本的时间戳以及一个指向该版本位置的指针
如果一个数据项的旧版本再也不会被当前活动的事务使用到,则这些旧版本就成为垃圾,可以被回收掉
关系数据库的并发控制
面向谓词的并发控制 - Predicate-Oriented Concurrency Control
封锁协议是针对页、数据项加锁,而面向谓词的并发控制是针对操作加锁,更具体的是针对操作的谓词加锁。例如:
select name from persons where age>30
则将age>30与锁关联
面向谓词的并发控制是比较早提出来的一种想法,后来也经过了不少研究,他的问题在于检测两个谓词是否兼容是一个NP完全问题,成本太高,但在特定场景下,例如B+树上的并发控制,具有实际意义
实现和实用性问题
通用的锁管理器数据结构
图:锁管理器的数据结构
锁管理器需要达成的目标:
1. 请求锁时可以检验冲突
2. 释放锁时,需要将资源授予被该锁阻塞的其他锁
3. 事务终止时释放该事务的所有锁
锁管理器的数据结构常驻内存,由resource ID索引的哈希表存放已经加锁以及需要加锁的资源ID
每个哈希表项指向一个资源控制块RCB,RCB中的hash chain用于解决hash冲突
对于共享锁,多个锁可以同时被同一资源持有,多个锁请求(例如冲突的写锁)可能正在等待被授予该资源上,这样在同一个资源上将形成一个已持有的共享锁列表以及等待被授予的排他锁与共享锁队列,因此在RCB上会指向一个锁控制块LCB的链接表,即上图中的FirstInQueue, NextInQueue链表
为了达成第3点,为每个活动事务维护一个事务控制块TCB,同样使用链表将该事务的所有锁链接起来,即上图中的LCB chain构成的链表
锁的数据结构将是数据库中访问最频繁的地方之一,因此需要控制这个内存数据结构的大小来避免性能问题,所以一般数据库中存在锁粒度升级的处理方式。如果一个事务已经持有了大量细粒度的行锁,数据库可能会将锁粒度升级为页锁或者表锁,以减小锁管理器的内存空间
使用了不同粒度的锁,就存在不同粒度之间相容性的判断问题,所以引入了意向锁,参考数据库系统 - 面向应用的方法

