[整理] - Relational Engine之Query Process
大部分情况下,SQL的优化调整,就是做一系列让optimizer做出更好选择(决定)的事情。充分理解SQL语句的编译、优化、执行过程,才能更有效的开发良好性能的SQL Query。
对于一个效率不好的Query,我们应当了解SQL Server会用怎样的步骤来执行,为什么用这样一个步骤,然后我们就可以影响、改变SQL Server的这个选择,以提高性能。
对于一个效率不好的Query,我们应当了解SQL Server会用怎样的步骤来执行,为什么用这样一个步骤,然后我们就可以影响、改变SQL Server的这个选择,以提高性能。
Some concepts
DDL, DCL, DML
SQL语句的分类。
DDL:Data Definition Language,数据定义。用于管理数据库对象的,例如CREATE TABLE、CREATE VIEW、DROP TABLE等等。
DCL:Data Control Language,数据控制。控制数据库对象的权限等语句。例如GRANT、REVOKE等。SQL Server中程序化控制语句WHILE、IF、变量定义等。
DML:Data Manipulation Language,数据管理。数据的存取命令,SQL语句中仅SELECT、INSERT、UPDATE、DELETE等语句属于DML。
SQL, Transact-SQL(T-SQL)
一般的情况下,以及大家平常使用的称呼中,SQL和Transact-SQL(T-SQL)是等价的概念,但在此处需要指明他们的区别,因为在查询处理器中,对SQL和T-SQL的处理是不一样的。
SQL,指仅包含DML的语句。Transact-SQL(T-SQL)则是DDL、DCL、DML的通称,例如IF、WHILE、局部变量定义等。
SARG(Search Argument)
SQL语句的条件中,只有SARG的条件才能被index使用,用于index seek中,加快查询速度。SARG的形式如下:
<column> <operator> <constant or variable>或者
<<constant or variable> <operator> <column>
Operator(操作符)包括=、>、<、>=、<=,和某些情况下的LIKE语句。例如 LIKE 'Jon%'是一个SARG,而LIKE '%Jon'就不是一个SARG(即索引的前导匹配)。LIKE语句用于字符类型列的搜索,要使条件能进行Index Seek,条件的第一个字符就不能是一个通配符,否则就不是一个SARG(SQL Server 2005中,'%Jon%'形式的条件也能用于index seek)。
列可以出现在operator的任意一边,但如果两边都出现了列,那这个条件就不是SARG。
符合SARG的多个条件之间必须是AND的关系,否则这多个条件就不是一个SARG。例如表中有一个索引(name, salary),条件name LIKE 'Jon%' AND salary>10000是一个SARG,因为在index seek中,可以先使用name LIKE 'Jon%',在符合条件的范围中再对salary>10000进行index seek。如果条件换成name LIKE 'Jon%' OR salary>10000,就无法进行idnex seek了。
Operator中包含NOT, !=, <>, !>, !<, NOT EXISTS, NOT IN以及NOT LIKE等,就不是SARG。
对列进行简单的数学运算,SQL Server可以将这种条件转化为一个SARG。例如WHERE price * 12 = costs转化之后形式为WHERE price = costs/12,成为SARG。
对一个列使用function的条件,不是SARG。例如ABS(ProductID)=60。
有些条件不符合SARG,但是我们可以将其转换为一个等价的SARG,以达到利用idnex的目的。例如:SUBSTRING(name,1,3)='Jon'不是SARG,而等效的条件 name LIKE 'Jon%'是SARG。
SQL语句的分类。
DDL:Data Definition Language,数据定义。用于管理数据库对象的,例如CREATE TABLE、CREATE VIEW、DROP TABLE等等。
DCL:Data Control Language,数据控制。控制数据库对象的权限等语句。例如GRANT、REVOKE等。SQL Server中程序化控制语句WHILE、IF、变量定义等。
DML:Data Manipulation Language,数据管理。数据的存取命令,SQL语句中仅SELECT、INSERT、UPDATE、DELETE等语句属于DML。
SQL, Transact-SQL(T-SQL)
一般的情况下,以及大家平常使用的称呼中,SQL和Transact-SQL(T-SQL)是等价的概念,但在此处需要指明他们的区别,因为在查询处理器中,对SQL和T-SQL的处理是不一样的。
SQL,指仅包含DML的语句。Transact-SQL(T-SQL)则是DDL、DCL、DML的通称,例如IF、WHILE、局部变量定义等。
SARG(Search Argument)
SQL语句的条件中,只有SARG的条件才能被index使用,用于index seek中,加快查询速度。SARG的形式如下:
<column> <operator> <constant or variable>或者
<<constant or variable> <operator> <column>
Operator(操作符)包括=、>、<、>=、<=,和某些情况下的LIKE语句。例如 LIKE 'Jon%'是一个SARG,而LIKE '%Jon'就不是一个SARG(即索引的前导匹配)。LIKE语句用于字符类型列的搜索,要使条件能进行Index Seek,条件的第一个字符就不能是一个通配符,否则就不是一个SARG(SQL Server 2005中,'%Jon%'形式的条件也能用于index seek)。
列可以出现在operator的任意一边,但如果两边都出现了列,那这个条件就不是SARG。
符合SARG的多个条件之间必须是AND的关系,否则这多个条件就不是一个SARG。例如表中有一个索引(name, salary),条件name LIKE 'Jon%' AND salary>10000是一个SARG,因为在index seek中,可以先使用name LIKE 'Jon%',在符合条件的范围中再对salary>10000进行index seek。如果条件换成name LIKE 'Jon%' OR salary>10000,就无法进行idnex seek了。
Operator中包含NOT, !=, <>, !>, !<, NOT EXISTS, NOT IN以及NOT LIKE等,就不是SARG。
对列进行简单的数学运算,SQL Server可以将这种条件转化为一个SARG。例如WHERE price * 12 = costs转化之后形式为WHERE price = costs/12,成为SARG。
对一个列使用function的条件,不是SARG。例如ABS(ProductID)=60。
有些条件不符合SARG,但是我们可以将其转换为一个等价的SARG,以达到利用idnex的目的。例如:SUBSTRING(name,1,3)='Jon'不是SARG,而等效的条件 name LIKE 'Jon%'是SARG。
Query Process

SQL的编译和执行是两个不同的阶段,这两个过程时间上的差别可能很小,只有几毫秒,也可能会很长,达到几小时甚至几天。编译阶段分析时所使用的信息,在执行阶段可能会变得不一样,例如索引可能会改变,table中的数据可能会改变。
Compilation
Parsing
类似编译原理中的词法、语法分析。对SQL进行语法检查,将SQL编译成Sequence Tree(顺序树)。Parsing阶段不检查table、column的有效性,这些在Normalization阶段进行。
Normalization
主要是检查对SQL Server内部对象引用的有效性,例如table、column名称是否正确等。加载metadata,将对SQL Server内部对象的引用转换为对元数据的引用。将隐式的数据类型转换操作放入到顺序树。使用视图的定义替换视图。
接下来SQL Server判断SQL类型,如果是SQL,也就是DML语句,则使用Sequence Tree创建Query Graph(查询树/图)。Optimizer在Query Graph上进行优化,生成Execution Plan。如果是T-SQL,则由程序化控制引擎进行编译。
类似编译原理中的词法、语法分析。对SQL进行语法检查,将SQL编译成Sequence Tree(顺序树)。Parsing阶段不检查table、column的有效性,这些在Normalization阶段进行。
Normalization
主要是检查对SQL Server内部对象引用的有效性,例如table、column名称是否正确等。加载metadata,将对SQL Server内部对象的引用转换为对元数据的引用。将隐式的数据类型转换操作放入到顺序树。使用视图的定义替换视图。
接下来SQL Server判断SQL类型,如果是SQL,也就是DML语句,则使用Sequence Tree创建Query Graph(查询树/图)。Optimizer在Query Graph上进行优化,生成Execution Plan。如果是T-SQL,则由程序化控制引擎进行编译。
Optimization
SQL Server optimizer是基于成本的优化器。Optimizer根据各个可能的Execution Plan对资源的使用量,评估这个Execution Plan的执行成本,尝试从各种可能的Execution Plan找到一个执行成本最低的。有些语句,可以使用的Execution Plan很多,SQL Server并不会对每一种可能的Execution Plan进行分析,否则这个分析过程本身就相当耗时。SQL Server只是尝试从这些Execution Plan中找出一个成本合理的。
最低的执行成本,也并不意味着是最低的资源使用。SQL Server尝试在合理的资源使用上尽快的完成查询。
Optimizer的优化处理包括下面的一些主要步骤。
Trivial Plan Optimization
优化过程需要消耗时间,SQL Server尝试从各种可能的Execution Plan中,得到一个代价最低的,这个优化过程可能会是一个比较昂贵的开销。Trivial Plan Optimization是SQL Server在进行优化前,先检查需要优化的语句是否存在多种可能的Execution Plan。如果对该语句只有一种可能的Execution Plan,例如INSERT一条记录等,则SQL Server加载metadata,例如索引的统计信息等,在可用资源的基础上直接对该语句生成Execution Plan。这避免了SQL Server进行各种尝试消耗额外的时间。
Simplifications
主要是一些Syntactic Transformations。SQL Server可以在不需要索引统计信息情况下,对语句进行语法上的重组优化。
Optimizer的优化,是一系列的转换规则,尝试各种索引和Join策略的组合。为了避免分析所有可能的Execution Plan而消耗时间,Optimizer分成多个阶段进行。每一个阶段都包含一系列规则,在每个阶段结束时,Optimizer评估这一阶段中得到的 Execution Plan的执行成本,如果成本合理则选择这一个,否则,继续进入下一阶段的分析。
每一阶段的分析过程是相同的,大致包括下面几个步骤。
Query Analysis
主要是SARG的识别和选择。
有的SARG条件,不一定可以用于执行期间的Index Seek,但是在优化阶段,可能optimizer仍可以根据该SARG得出更精确的Estimated Row Count,有助于SQL Server选择更好的Execution Plan。
Index Selection
检查SARG是否可以被Index使用,检查Index的可用性。加载Index的统计信息,评估Estimated Row Count和Index使用所需的成本。
Covering Index(覆盖索引),指查询语句中对某table所有column的引用,都存在于一个索引中。这可以避免Bookmark Lookup操作,提高性能。Bookmark Lookup参考文章Bookmark Lookup。
JOIN Selection
Optimizer根据多方面的因素评估Join操作的成本,包括所需的Logical READS数量、内存数量等。SQL Server尝试不同的Join顺序、Join Type等,从其中找出成本最低的一种策略。
关于Join Type:Nested-Loop Join、Merge Join、Hash Join,参考前面几篇的介绍。
大部分情况下,SQL Server在最初的几个优化阶段(Phase 1~n)可以找到一个合适的Execution Plan。如果在Phase 1~n中仍然没有得到合适的plan,则SQL Server根据当前得到的最好的plan评估出的执行成本,与cost threshold for parallelism配置项进行比较。如果成本高于cost threshold for parallelism值,SQL Server进入Full Optimization阶段,生成Parallel Execution Plan。如果成本低于cost threshold for parallelism,或者只有一个CPU可用,SQL Server只能检查所有索引、各处理策略的组合情况,生成一个Serial Execution Plan。
最低的执行成本,也并不意味着是最低的资源使用。SQL Server尝试在合理的资源使用上尽快的完成查询。
Optimizer的优化处理包括下面的一些主要步骤。
Trivial Plan Optimization
优化过程需要消耗时间,SQL Server尝试从各种可能的Execution Plan中,得到一个代价最低的,这个优化过程可能会是一个比较昂贵的开销。Trivial Plan Optimization是SQL Server在进行优化前,先检查需要优化的语句是否存在多种可能的Execution Plan。如果对该语句只有一种可能的Execution Plan,例如INSERT一条记录等,则SQL Server加载metadata,例如索引的统计信息等,在可用资源的基础上直接对该语句生成Execution Plan。这避免了SQL Server进行各种尝试消耗额外的时间。
Simplifications
主要是一些Syntactic Transformations。SQL Server可以在不需要索引统计信息情况下,对语句进行语法上的重组优化。
Optimizer的优化,是一系列的转换规则,尝试各种索引和Join策略的组合。为了避免分析所有可能的Execution Plan而消耗时间,Optimizer分成多个阶段进行。每一个阶段都包含一系列规则,在每个阶段结束时,Optimizer评估这一阶段中得到的 Execution Plan的执行成本,如果成本合理则选择这一个,否则,继续进入下一阶段的分析。
每一阶段的分析过程是相同的,大致包括下面几个步骤。
Query Analysis
主要是SARG的识别和选择。
有的SARG条件,不一定可以用于执行期间的Index Seek,但是在优化阶段,可能optimizer仍可以根据该SARG得出更精确的Estimated Row Count,有助于SQL Server选择更好的Execution Plan。
Index Selection
检查SARG是否可以被Index使用,检查Index的可用性。加载Index的统计信息,评估Estimated Row Count和Index使用所需的成本。
Covering Index(覆盖索引),指查询语句中对某table所有column的引用,都存在于一个索引中。这可以避免Bookmark Lookup操作,提高性能。Bookmark Lookup参考文章Bookmark Lookup。
JOIN Selection
Optimizer根据多方面的因素评估Join操作的成本,包括所需的Logical READS数量、内存数量等。SQL Server尝试不同的Join顺序、Join Type等,从其中找出成本最低的一种策略。
关于Join Type:Nested-Loop Join、Merge Join、Hash Join,参考前面几篇的介绍。
大部分情况下,SQL Server在最初的几个优化阶段(Phase 1~n)可以找到一个合适的Execution Plan。如果在Phase 1~n中仍然没有得到合适的plan,则SQL Server根据当前得到的最好的plan评估出的执行成本,与cost threshold for parallelism配置项进行比较。如果成本高于cost threshold for parallelism值,SQL Server进入Full Optimization阶段,生成Parallel Execution Plan。如果成本低于cost threshold for parallelism,或者只有一个CPU可用,SQL Server只能检查所有索引、各处理策略的组合情况,生成一个Serial Execution Plan。
Other Processing Stratigies
GROUP BY Operations
SQL Server 7只有一种方式处理GROUP BY:先对数据进行排序,然后直接建立GROUP BY结果。这种处理方式的一个效果是,结果集是自动经过排序的。
SQL Server 2000还有另外一种处理方式,即使用Hash算法。当SQL Sever 2000使用Hash算法处理GROUP BY时,如果查询中没有明确的ORDER BY 语句,结果集的排序是不确定的。
DISTINCT Operations
跟GROUP BY一样,SQL Server 7也是先对数据进行排序,然后去除重复的记录。SQL Server 2000可以使用Hash算法进行DISTINCT操作,类似于GROUP BY,只是不需要计算aggregates。
UNION Operations
SQL Server有两种方式合并结果集。如果使用UNION ALL,SQL Server返回input table的所有记录集。如果没有使用ALL关键字,SQL Server在返回结果集前,先需要移除重复记录。
SQL Server使用三种方式移除UNION操作时产生的重复记录:使用Hash算法移除重复记录,跟DISTINCT操作时一样;先对input table排序,然后进行Merge操作;先合并input table,然后在排序,再移除重复记录。
如果确信UNION的各个input中不会有重复记录存在,使用UNION ALL可以避免SQL Server进行移除重复记录的操作,提高性能。
对GROUP BY、DISTINCT、UNION,SQL Server自动选择处理方式,也可以在查询中使用hint强制SQL Server用指定的方式来处理。
SQL Server 7只有一种方式处理GROUP BY:先对数据进行排序,然后直接建立GROUP BY结果。这种处理方式的一个效果是,结果集是自动经过排序的。
SQL Server 2000还有另外一种处理方式,即使用Hash算法。当SQL Sever 2000使用Hash算法处理GROUP BY时,如果查询中没有明确的ORDER BY 语句,结果集的排序是不确定的。
DISTINCT Operations
跟GROUP BY一样,SQL Server 7也是先对数据进行排序,然后去除重复的记录。SQL Server 2000可以使用Hash算法进行DISTINCT操作,类似于GROUP BY,只是不需要计算aggregates。
UNION Operations
SQL Server有两种方式合并结果集。如果使用UNION ALL,SQL Server返回input table的所有记录集。如果没有使用ALL关键字,SQL Server在返回结果集前,先需要移除重复记录。
SQL Server使用三种方式移除UNION操作时产生的重复记录:使用Hash算法移除重复记录,跟DISTINCT操作时一样;先对input table排序,然后进行Merge操作;先合并input table,然后在排序,再移除重复记录。
如果确信UNION的各个input中不会有重复记录存在,使用UNION ALL可以避免SQL Server进行移除重复记录的操作,提高性能。
对GROUP BY、DISTINCT、UNION,SQL Server自动选择处理方式,也可以在查询中使用hint强制SQL Server用指定的方式来处理。
Recompilation & Cache Strategies
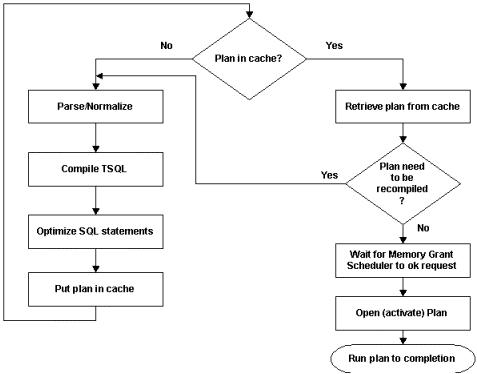
编译优化阶段结束后,生成的执行计划将直接执行,或者被放入缓存中等待执行。
Recompilation
从上面可以看到,编译、优化阶段使用了大量的信息,在这些信息的基础上生成一个优化的执行计划。如果这些信息发生了变化,那已经生成的执行计划可能成为一种不好的方案。如果SQL Server检测到某些关键信息与编译优化阶段不一样了,就会重新编译这个执行计划。
导致执行计划被重新编译的一些信息,包括并发进程数、lock的数量,还有元数据信息,例如添加删除了索引。还有就是统计信息的变化,因为SQL Server基于统计信息分析索引的可用性,从而生成优化的执行计划。如果编译优化之后,表中被插入大量的数据,统计信息会有大的改变,索引的可用性也发生变化了。
另外一些情况不会导致计划的重编译,例如使用参数化的查询,参数的值发生变化;其它一些环境信息,例如可用内存数、需要使用的数据是否已被加载到内存缓存中。
Procedure Cache
对简单的ad hoc SQL语句,编译优化所用成本很小,SQL Server不会缓存执行计划,对于存储过程、参数化的查询语句或者复杂的ad hoc语句,SQL Server才会将执行计划进行缓存。
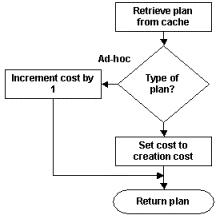
执行计划在放入缓存时,会附带一个执行计划的编译成本因子(cost factor)。这个编译成本因子是基于SQL Server I/O成本的,从磁盘读取一个数据页到内存,为1个I/O成本单位。SQL Server将编译优化期间从磁盘加载统计信息的成品,以及编译、优化所用的时间,都转换为I/O成本单位,与执行计划一起保存。
对于ad hoc的执行计划,成本因子被设置为0,这意味着ad hoc的执行计划将最先从缓存中清除。对于参数化的查询语句和存储过程的执行计划,成本因子被设置为编译优化的成本。

在其它的查询请求重用某个执行计划时,如果这个查询是ad hoc语句,SQL Server把这个执行计划的成本因子增加1(最大值为这个ad hoc编译优化的成本值);如果是存储过程、参数化查询语句,SQL Server把成本因子恢复到这个执行计划编译、优化的成本值。
Lasywriter将管理procedure cache,它实际上属于存储引擎部分,是SQL Server的内存管理机制,用于管理SQL Server内存中缓存数据的生命周期,按照缓存策略从内存移除数据,以释放内存空间分配给其它操作。
Lasywriter扫描内存中所有的buffer headers。在内存压力比较小时,lasywrite扫描频率很低;当内存压力非常大时,lasywrite的扫描频率也变得非常高。 Lasywriter检查到某个buffer header中的成本因子为0时,如果是ad hoc或者参数化查询语句的执行计划,lasywriter会将这个buffer的内存页释放出来;如果是存储过程的执行计划,lasywrite调用 SQL Manager清除缓存中的存储过程执行计划。
从上面procedure cache的管理机制中可以了解,对ad hoc的执行计划,必须使用非常频繁,才能够保留在缓存中;而对于那些编译成本很高的存储过程的执行计划,即使使用的频率非常低,它在缓存中保留的时间还是会很久,因为它初始的成本因子值就相当高。
Recompilation
从上面可以看到,编译、优化阶段使用了大量的信息,在这些信息的基础上生成一个优化的执行计划。如果这些信息发生了变化,那已经生成的执行计划可能成为一种不好的方案。如果SQL Server检测到某些关键信息与编译优化阶段不一样了,就会重新编译这个执行计划。
导致执行计划被重新编译的一些信息,包括并发进程数、lock的数量,还有元数据信息,例如添加删除了索引。还有就是统计信息的变化,因为SQL Server基于统计信息分析索引的可用性,从而生成优化的执行计划。如果编译优化之后,表中被插入大量的数据,统计信息会有大的改变,索引的可用性也发生变化了。
另外一些情况不会导致计划的重编译,例如使用参数化的查询,参数的值发生变化;其它一些环境信息,例如可用内存数、需要使用的数据是否已被加载到内存缓存中。
Procedure Cache
对简单的ad hoc SQL语句,编译优化所用成本很小,SQL Server不会缓存执行计划,对于存储过程、参数化的查询语句或者复杂的ad hoc语句,SQL Server才会将执行计划进行缓存。
执行计划在放入缓存时,会附带一个执行计划的编译成本因子(cost factor)。这个编译成本因子是基于SQL Server I/O成本的,从磁盘读取一个数据页到内存,为1个I/O成本单位。SQL Server将编译优化期间从磁盘加载统计信息的成品,以及编译、优化所用的时间,都转换为I/O成本单位,与执行计划一起保存。
对于ad hoc的执行计划,成本因子被设置为0,这意味着ad hoc的执行计划将最先从缓存中清除。对于参数化的查询语句和存储过程的执行计划,成本因子被设置为编译优化的成本。
在其它的查询请求重用某个执行计划时,如果这个查询是ad hoc语句,SQL Server把这个执行计划的成本因子增加1(最大值为这个ad hoc编译优化的成本值);如果是存储过程、参数化查询语句,SQL Server把成本因子恢复到这个执行计划编译、优化的成本值。
Lasywriter将管理procedure cache,它实际上属于存储引擎部分,是SQL Server的内存管理机制,用于管理SQL Server内存中缓存数据的生命周期,按照缓存策略从内存移除数据,以释放内存空间分配给其它操作。
Lasywriter扫描内存中所有的buffer headers。在内存压力比较小时,lasywrite扫描频率很低;当内存压力非常大时,lasywrite的扫描频率也变得非常高。 Lasywriter检查到某个buffer header中的成本因子为0时,如果是ad hoc或者参数化查询语句的执行计划,lasywriter会将这个buffer的内存页释放出来;如果是存储过程的执行计划,lasywrite调用 SQL Manager清除缓存中的存储过程执行计划。
从上面procedure cache的管理机制中可以了解,对ad hoc的执行计划,必须使用非常频繁,才能够保留在缓存中;而对于那些编译成本很高的存储过程的执行计划,即使使用的频率非常低,它在缓存中保留的时间还是会很久,因为它初始的成本因子值就相当高。
Execution
在执行阶段,SQL Server从缓存中取出执行计划后按顺序执行,这个阶段比较关键的一个处理是内存分配。SQL Server需要使用大量内存进行的操作,主要是排序和hash join。
将要执行的计划被提交给memory grant scheduler。
如果执行计划里面没有排序(指执行计划中的sort操作,并不是说用户提交的SQL里面是否有order by关键字)、hash join等操作,grant scheduler知道这个查询不需要使用大内存,因此不需要任何等待,直接执行这样的查询计划。
另外,如果grant scheduler判断出执行计划比较小,例如"select top 10",或者仅仅是需要对20个行进行排序,这样的计划也不需要使用大内存。这些计划仍然需要通过grant scheduler分配内存之后才会执行,但grant scheduler会在执行队列里面给这些计划比较高的优先级,因此也能够相当快的开始执行。
通常情况下,一些复杂的查询需要使用大量的内存进行操作。SQL Server在每一个执行计划的优化期间,都会确定两个值,一个是为了有效的执行这个计划所需要的最小内存量,另一个是可以提升这个查询速度的最大内存使用量,这两个值都会和执行计划一起保存起来。Grant scheduler在执行队列比较空闲的情况下,开始为这些计划分配内存。Grant scheduler根据当前可用内存量,为执行计划分配一个最小内存使用值,或者是最大内存使用值,或者是这之间的一个值。
之前写过的一篇Blog SQL SQL优化 TOP方面描述了使用不同的TOP值时,语句的执行计划完全一样,但所用时间相差非常大,其根本原因应当同上面讲述的grant scheduler工作原理紧密相关。
Grant scheduler分配完内存之后,将队列里面的计划标记位"opened"状态,开始执行这个计划,直到结束。如果查询使用 default result set model,执行计划在处理完所有的数据之后,将结果返回给client。如果查询使用cursor model,Client将每次请求一个包含多个结果记录行的数据块,并不是一次取全部的结果集。所有的数据块返回给client之后,将等待 client下一系列的请求。在等待阶段,计划在执行队列中的状态变为"domant",这个计划执行时所使用的锁和其它资源都被释放,cursor的位置等当前的一些状态信息被保存起来,以用于计划被唤醒时继续执行。
将要执行的计划被提交给memory grant scheduler。
如果执行计划里面没有排序(指执行计划中的sort操作,并不是说用户提交的SQL里面是否有order by关键字)、hash join等操作,grant scheduler知道这个查询不需要使用大内存,因此不需要任何等待,直接执行这样的查询计划。
另外,如果grant scheduler判断出执行计划比较小,例如"select top 10",或者仅仅是需要对20个行进行排序,这样的计划也不需要使用大内存。这些计划仍然需要通过grant scheduler分配内存之后才会执行,但grant scheduler会在执行队列里面给这些计划比较高的优先级,因此也能够相当快的开始执行。
通常情况下,一些复杂的查询需要使用大量的内存进行操作。SQL Server在每一个执行计划的优化期间,都会确定两个值,一个是为了有效的执行这个计划所需要的最小内存量,另一个是可以提升这个查询速度的最大内存使用量,这两个值都会和执行计划一起保存起来。Grant scheduler在执行队列比较空闲的情况下,开始为这些计划分配内存。Grant scheduler根据当前可用内存量,为执行计划分配一个最小内存使用值,或者是最大内存使用值,或者是这之间的一个值。
之前写过的一篇Blog SQL SQL优化 TOP方面描述了使用不同的TOP值时,语句的执行计划完全一样,但所用时间相差非常大,其根本原因应当同上面讲述的grant scheduler工作原理紧密相关。
Grant scheduler分配完内存之后,将队列里面的计划标记位"opened"状态,开始执行这个计划,直到结束。如果查询使用 default result set model,执行计划在处理完所有的数据之后,将结果返回给client。如果查询使用cursor model,Client将每次请求一个包含多个结果记录行的数据块,并不是一次取全部的结果集。所有的数据块返回给client之后,将等待 client下一系列的请求。在等待阶段,计划在执行队列中的状态变为"domant",这个计划执行时所使用的锁和其它资源都被释放,cursor的位置等当前的一些状态信息被保存起来,以用于计划被唤醒时继续执行。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号