代码表示学习:序列化表示的结构化信息增强
参考文献
ISVSF: Intelligent Vulnerability Detection Against Java via sentence-level Pattern Exploring - IEEE SYSTEMS JOURNAL 2021
代码序列化表示学习的结构化信息增强
- 序列化代码表示学习借鉴NLP领域,将代码看做文本序列进行表示学习;
- 序列化表示学习会导致代码本身的结构化信息丢失,所以需要进行结构化信息增强;
- 序列化表示的结构信息增强的基本思路是:以结构信息中的最小集作为序列单位,而不是语义最小集作为序列单位;
- 一般步骤:代码中间表示;基于中间表示的子序列分割;子序列encoder
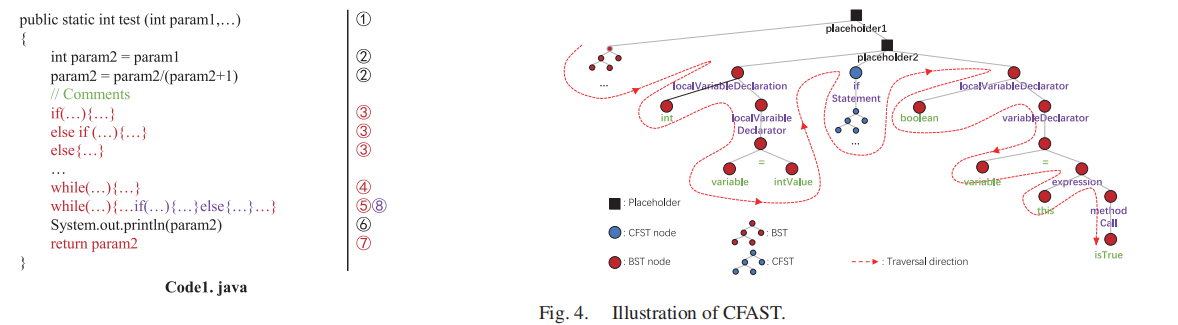
1.代码中间表示 : control flow abstract syntax tree (CFAST)
在AST的基础上加上CFG边,一种常见的代码结构化表示方式。
2.代码子序列分割
CFAST是一种结构化表示方式,而NLP是基于序列的编码技术,所以分割的基本要求是分割得到的序列要保留完整的结构化信息。
根据结构将CFAST分割为:basic sub-block tree 和 control flow sub-block tree
基本语句块:只有语法信息的语句
控制流块:包含控制流信息的语句
将CFAST分割成2种子树组成的集合
CFAST : {Basic Sub-Tree Set} ∩ {Control-Flow Sub-Tree set}
利用广度优先遍历子树集合,得到语句集合s
sentences set = BFS(Basic Sub-Tree Set) ∩ BFS(Control-Flow Sub-Tree set)
comments
该文章是将普通的AST进行分割,然后使用分割的结果进行分别遍历得到对应的序列化表示。
与直接使用代码语句作为序列化表示相比,并没明显的控制流信息,个人感觉该方法无法在序列中体现控制流语义信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号