代码表示的分总范式:Vulnerability Detection with Fine-Grained Interpretations
参考文献
Vulnerability Detection with Fine-Grained Interpretations - 3.1
代码表示学习:分总范式
build the vector representations for code features
- 代码的基本4大特征:单词语义;语法结构;代码控制流信息(本文无);程序依赖信息
- 本文使用的方法:分开学习 + 融合

1 分布式特征特征
1.1 语句中单词语义特征学习
原因:分词粒度在代码词表中的重复程度远高于整个单词
方法:将单行语句进行分词,将分词后的token序列进行embeding
1.1.1 分词
基于驼峰或匈牙利原则进行分词,将分词结果中的单个字母丢弃,例如下图代码语句

分词结果:s_cmd分为:s和cmd,丢弃s

1.1.2 词嵌入
方法: GloVe + GRU
The GloVe is known to capture well semantic similarities among tokens.
GRU is chosen to summarize the sequence of vectors into one feature vector for the next step.

1.2 语句的语法结构特征学习
原因:上一步通过序列化表达方式得到单词在代码上下文的表示,但是无法得到代码本身结构化的信息。
方法:单行语句的AST + Tree-LSTM

1.3 变量和类型特征学习
原因:变量和变量类型是强相关的,在代码中只有定义变量时才会出现类型,而执行语句中该类型信息是默认隐藏的,所以需要额外学习变量和类型的特征;
方法:与步骤1相同

1.4 语句的上下文特征(程序依赖特征)学习
原因:代码中语句的三大语义信息之一:程序依赖,该特征需要通过当前语句关联的其它语句中学习到
方法:首先进行程序依赖分析,得到控制相关和数据相关的语句集合,利用步骤1相同的方法的得到这些语句的向量化特征
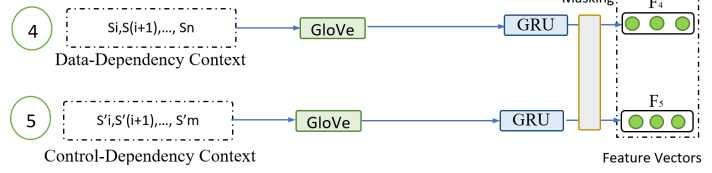
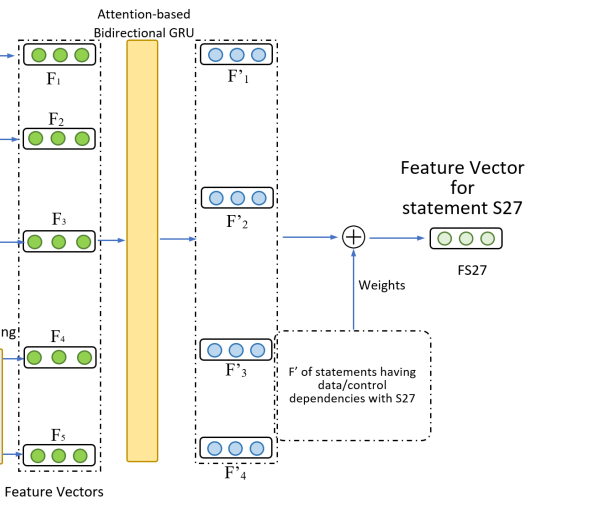
2 多特征融合
原因:F1 ~ F5分别代表了当前语句的不同角度特征向量,需要找到合适的权重将这些特征加权;
方法:Attention-based Bidirectional GRU,通过门控单元得到 F1 ~ F5 权重,利用权重进行加权。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号