
大模型中用到的归一化方法总结
大模型中的归一化主要是为了解决LLM训练不稳定的问题
LLM中归一化方法可以按照归一化方法来分,主要分为LayerNorm,BatchNorm,RMSNorm以及DeepNorm
按照归一化位置来分类,包括 postNorm 和 preNorm
1. BatchNorm
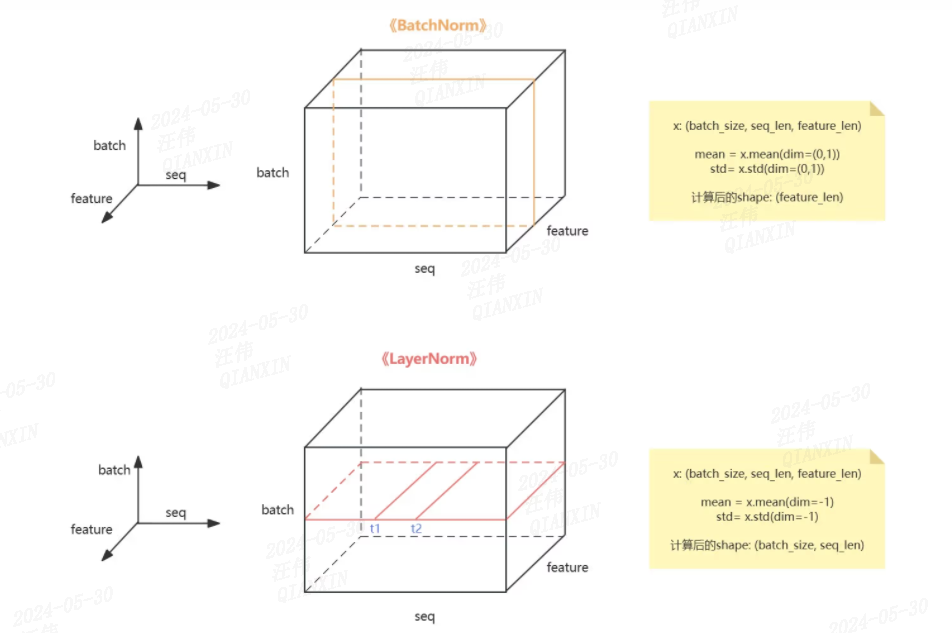
BatchNorm主要对数据的一定的特征维度在batch数据中进行归一,一般来说应用于图像。
这种方法很难适用于序列数据,对于序列数据而言,在batch维度做归一意义不大,而且一个batch内的序列长度不同。
2. LayerNorm(https://zhuanlan.zhihu.com/p/666791682)
LayerNorm是针对序列数据提出的一种归一化方法,主要在layer维度进行归一化,即对整个序列进行归一化。layerNorm会计算一个layer的所有activation的均值和方差,利用均值和方差进行归一化。
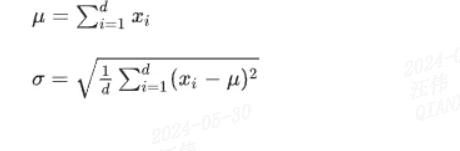


3. RMSNorm
RMSNorm的提出是为了提升layerNorm的训练速度提出的。RMSNorm也是一种layerNorm,只是归一化的方法不同。相比layerNorm中利用均值和方差进行归一化,RMSNorm 利用均方根进行归一化。
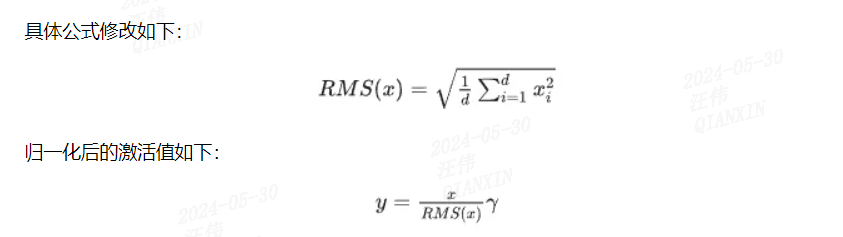
对于layerNorm和RMSNorm,layerNorm包含缩放和平移两部分,RMSNorm去除平移部分,只保留缩放部分。这样做的依据是,有研究认为layerNorm取得成功的关键是缩放部分的缩放不变性,而不是平移部分的平移不变性。
RMSNorm相比一般的layerNorm,减少了计算均值和平移系数的部分,训练速度更快,效果基本相当,甚至有所提升。
4. DeepNorm
DeepNorm是由微软提出的一种Normalization方法。主要对Transformer结构中的残差链接做修正。
DeepNorm可以缓解模型参数爆炸式更新的问题,把模型参数更新限制在一个常数域范围内,使得模型训练过程可以更稳定。模型规模可以达到1000层。
DeepNorm兼具PreLN的训练稳定和PostLN的效果性能。
DeepNorm对layerNorm之前的残差链接进行了up-scale,在初始化阶段down-scale了模型参数。GLM-130B 模型中就采用了DeepNorm。
二、归一化位置
同一设置之下,Pre Norm结构往往更容易训练,但最终效果通常不如Post Norm。
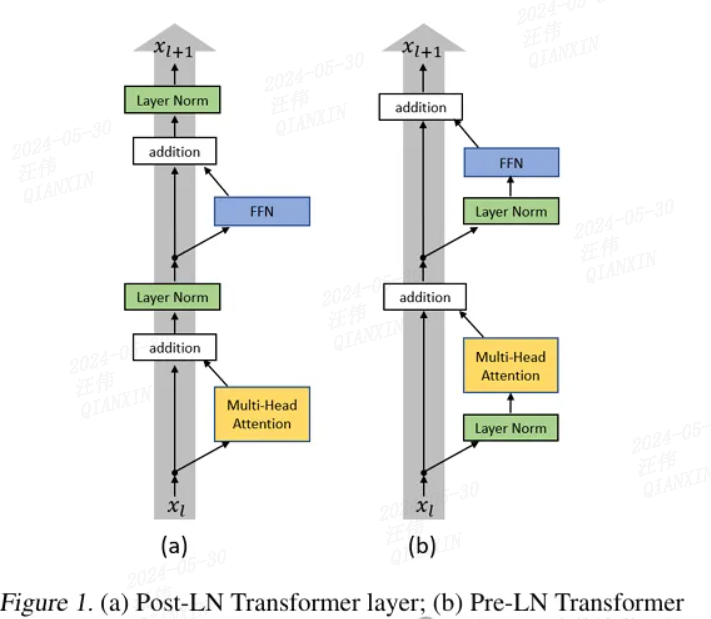

而我们知道,神经网络深度通常比宽度更重要:
a. 提升同样效果需要增加的宽度远远超过需要增加的深度
Warmup是在训练开始阶段,将学习率从0缓增到指定大小,而不是一开始从指定大小训练。如果不进行Wamrup,那么模型一开始就快速地学习,由于梯度消失,模型对越靠后的层越敏感,也就是越靠后的层学习得越快,然后后面的层是以前面的层的输出为输入的,前面的层根本就没学好,所以后面的层虽然学得快,但却是建立在糟糕的输入基础上的。
很快地,后面的层以糟糕的输入为基础到达了一个糟糕的局部最优点,此时它的学习开始放缓(因为已经到达了它认为的最优点附近),同时反向传播给前面层的梯度信号进一步变弱,这就导致了前面的层的梯度变得不准。
所以,如果Post Norm结构的模型不进行Wamrup,我们能观察到的现象往往是:loss快速收敛到一个常数附近,然后再训练一段时间,loss开始发散,直至NAN。如果进行Wamrup,那么留给模型足够多的时间进行“预热”,在这个过程中,主要是抑制了后面的层的学习速度,并且给了前面的层更多的优化时间,以促进每个层的同步优化。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架