TF-IDF算法
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)
TF-IDF本质上是一种统计方法,用来评估一个词/token在整个语料库中当前文档中的重要程度,字词的重要性随着它在当前文档中出现的频率成正比增加,随着它在整个语料库中出现的频率成反比降低。
主要思想:某个单词在当前文章中出现的次数越多,并且在其他文章中出现的次数越少,则说明该词是当前文档的一个关键词,对于当前文档具有较好的类别区分能力,适合用来分类。
1)TF(Term Frequency) 词频
这个数字通常会被归一化(一般是词频除以文章总词数,也可以是这篇文章中出现最多的词的出现次数),以防止它偏向长的文件。

2)IDF(Inverse Document Frequency) 逆向文件频率
IDF是针对某一特定词语进行计算,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。
如果包含该特定词语的文档越少, IDF越大,则说明词条具有很好的类别区分能力。

3)计算TF-IDF
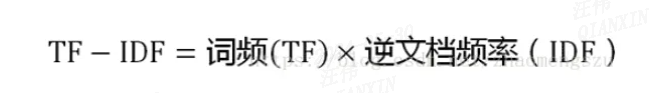
4)TF-IDF的用法
-
文档关键词提取
-
文档信息检索
5)TF-IDF的优缺点
优点:简单快速,结果比较符合实际情况
缺点:1.没有考虑关键词的位置信息,词语出现在文档不同位置,贡献度是不一样的(首行和末行权重应更大);2.生僻词的idf会高;不够全面,有些关键的人名、地名提取效果不好
import math # 建立一个语料库 corpus = [ "what is the weather like today", "what is for dinner tonight", "this is a question worth pondering", "it is a beautiful day today" ] # 进行分词,去停用词 # 如果有自定义的停用词典,我们可以用下列方法来分词并去掉停用词 words = [] f = ["is", "the"] for i in corpus: all_words = i.split() new_words = [] for j in all_words: if j not in f: new_words.append(j) words.append(new_words) print(words) # 计算词频TF TF_list = [] def counter_Tf(words): for i in words: temp = [] all_words = len(i) for word in i: temp.append(i.count(word)/all_words) TF_list.append(temp) return TF_list counter_Tf(words) print(TF_list) # 计算IDF word_dict = {} def counter_Word_IDF(words): for i in words: for word in i: if word in word_dict: word_dict[word] += 1 else: word_dict[word] = 0 return word_dict IDF_list = [] def counter_Tf(words): all_words = len(words) for i in words: temp = [] for word in i: temp.append(math.log(all_words/(1+word_dict[word]))) IDF_list.append(temp) return IDF_list counter_Word_IDF(words) counter_Tf(words) print(IDF_list) # 计算TF-IDF TF_IDF = TF*IDF
import math
# 建立一个语料库
corpus = [
"what is the weather like today",
"what is for dinner tonight",
"this is a question worth pondering",
"it is a beautiful day today"
]
# 进行分词,去停用词
# 如果有自定义的停用词典,我们可以用下列方法来分词并去掉停用词
words = []
f = ["is", "the"]
for i in corpus:
all_words = i.split()
new_words = []
for j in all_words:
if j not in f:
new_words.append(j)
words.append(new_words)
print(words)
# 计算词频TF
TF_list = []
def counter_Tf(words):
for i in words:
temp = []
all_words = len(i)
for word in i:
temp.append(i.count(word)/all_words)
TF_list.append(temp)
return TF_list
counter_Tf(words)
print(TF_list)
# 计算IDF
word_dict = {}
def counter_Word_IDF(words):
for i in words:
for word in i:
if word in word_dict:
word_dict[word] += 1
else:
word_dict[word] = 0
return word_dict
IDF_list = []
def counter_Tf(words):
all_words = len(words)
for i in words:
temp = []
for word in i:
temp.append(math.log(all_words/(1+word_dict[word])))
IDF_list.append(temp)
return IDF_list
counter_Word_IDF(words)
counter_Tf(words)
print(IDF_list)
# 计算TF-IDF
TF_IDF = TF*IDF

 浙公网安备 33010602011771号
浙公网安备 33010602011771号