BERT模型-文本相似度任务
作者:李rumor
链接:https://www.zhihu.com/question/354129879/answer/882012043
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
![]()
链接:https://www.zhihu.com/question/354129879/answer/882012043
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先对BERT本身的输出做pooling就可以得到句子表示,然后用一些metric(比如cosine)来计算相似度。但BERT在预训练时的目标是token-level的,这就导致训练-预测目标不一致,直接得到的表示并不好用。
下面推荐一些改进:
1、直接对BERT输出的表示进行改进
BERT-flow是20年字节提出的最新模型,但后来苏神证实了简单的whitening也能起到差不多的效果。
BERT-flow
题目:On the Sentence Embeddings from Pre-trained Language Models
论文:https://arxiv.org/pdf/2011.05864.pdf
代码:https://github.com/bohanli/BERT-flow
字节在EMNLP2020提出了BERT-flow,主要是基于Sentence-BERT做改动,因为之前的预训练+迁移都是使用有监督数据,而作者基于对原生BERT表示的分析发现,那些表示在空间的分布很不均匀,于是使用flow-based生成模型将它们映射到高斯分布的均匀空间,比之前的Sentence-BERT提升了4个点之多。
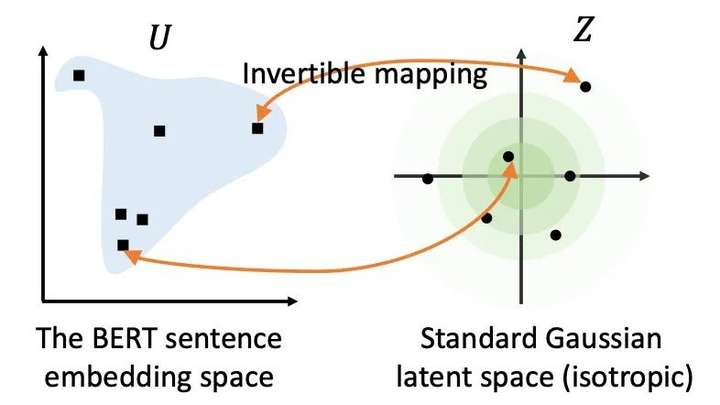
但这个模型的缺点是又加了一层机制,在预测时候会降低速度,同时在知乎上看到个别同学在自己任务上的试用反馈也不太好。不过我倒是验证了SentEval上有监督的效果(论文只给了无监督的),效果跟Sentence-BERT差不多。
https://zhuanlan.zhihu.com/p/357864974

 浙公网安备 33010602011771号
浙公网安备 33010602011771号