第18章:Upack PE分析
对两个PE文件进行对比分析:

可以发现,对各个结构体进行了重叠。首先观察PE头,DOS存根被省掉。
从3C地址处,找到NT头地址,在10H处。即DOS头和NT头进行了重叠。
文件头倒数第二个元素(SizeOfOptionalHeader)的值为148H。
由值10B找到可选头,下面一行即为EntryPoint(1018H),向下数6行,即到DataDirectory。
1018H的文件偏移为18H.

第二个数组即是ImportDirectory,得到值271ee,大小为14H。
为将RVA转换为FileOffset,找到对应节区的地址。
28+148=170H,即为节区头开始的地址。
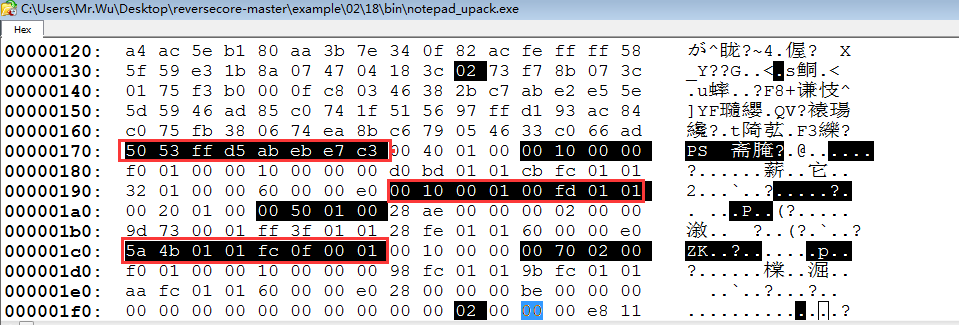
一共有三个节区(需要注意的是,这里的节区并没有使用常规的名字),每个节区的文件偏移为10H。
读结构体可知:
节区大小为10000H,起始地址为27000H。而前面给的地址是271ee < 28000。在第三节区。
故IAT的地址为:271ee-27100+10=2fe.
但是PointerToRawData的值必须为FileAlignment的整数倍。故必须为0,200,400,600等值。
经过测试,发现修改两个10H的值,只要值在[11,199]之间就会报错,小于11H的值都可以取。
PE装载器会将小于等于10H的值强制置为0.

从前面的可选头可以知道分块大小分别为1000H和200H。值得注意的是:这里的分块是指绝对地址,而不是相对地址。
因此这里其实被隔断了,最终只用了2字节表示了FirstThunk。
因此200H就是第二个节区的起始地址,FirstThunk(IAT)的值为11e8,文件偏移为 1e8。LibraryName在02H处。![]()
每一个四字节代表一个函数结构体地址,最终用一个NULL结尾。
由于INT为0,通过IAT查找函数即可:
![]()
![]()
前面两个字是Ordinal,后面是函数名以及一个00。这两个函数使得形成原文件IAT非常的方便。
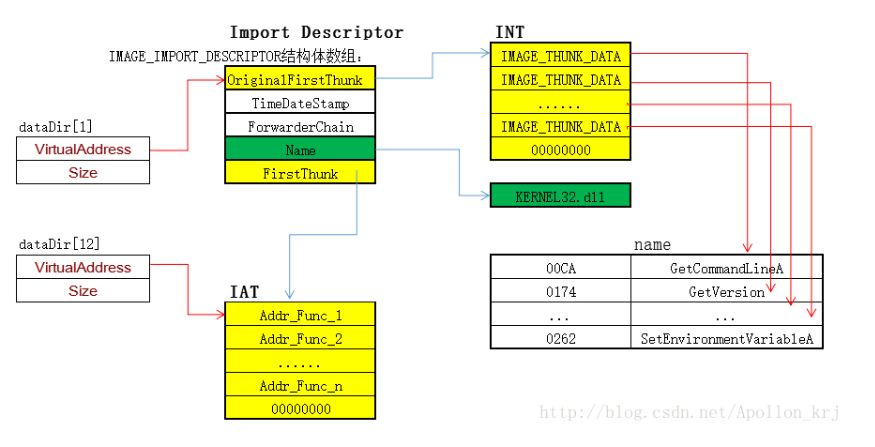
注意INT的查找方式和IAT类似,在此处, 都是以地址数组的形式指向函数结构体。前面 notepa.exe 中就直接指向了函数地址.
那么IAT和INT有什么区别呢?
在网上找到如下解释(讲得很清楚):
程序加载前,IAT和INT指向同一结构,而加载后INT不变依旧保存dll函数名与函数序号的地址信息。
而IAT则根据导入表INT(IAT加载前)的内容和库文件导出表信息,修改为对应的函数的地址信息。
这也是为什么INT被称为OriginalFirstThunk的原因。
同时也应当注意到:第一、第三节区的起始地址是相同的。PE规范并为对此进行规定。
只要代码对对应的节区进行解压缩,放到合适的位置就不影响程序的运行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号