聚集索引、非聚集索引
1、聚集索引
定义:索引的叶子节点包含了完整的表数据;此处的完整数据指的是索引列字段+完整的行记录数据,具体如下图所示:
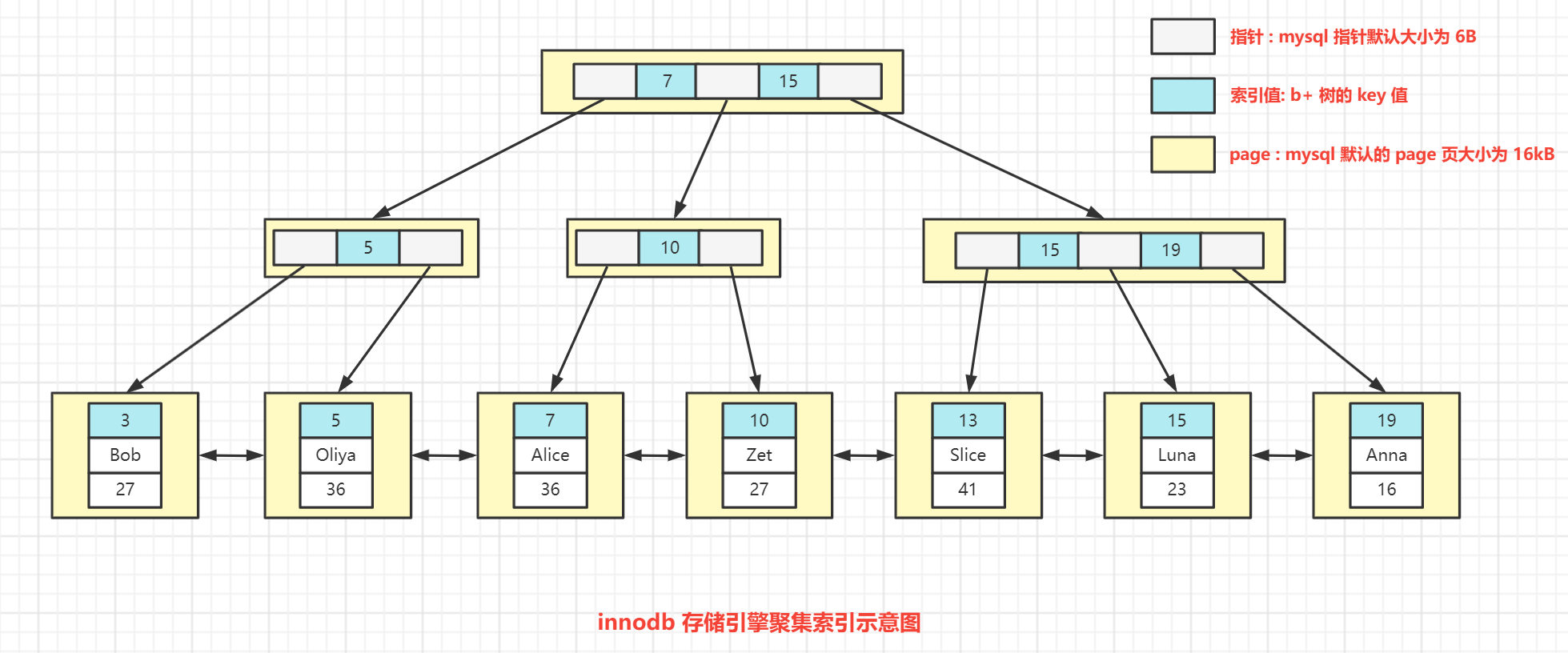
Innodb的主键索引就是基于聚集索引实现的。
聚集索引必须存在且只能有一个;
聚集索引的生成策略是:
若存在主键,那么主键就是聚集索引;
若不存在主键,则会使用第一个唯一、非空的索引作为聚集索引;
如果表中既没有主键索引,又没有合适的唯一索引,那么Innodb会自动维护一个row_id(默认大小为6B)作为隐藏的聚集索引。
2、非聚集索引
非聚集索引是相对聚集索引来说的;它是把索引和行数据分开维护,即叶子节点并没有包含完整的数据记录;
其叶子节点的数据区存储的是聚集索引的id或数据的磁盘地址;
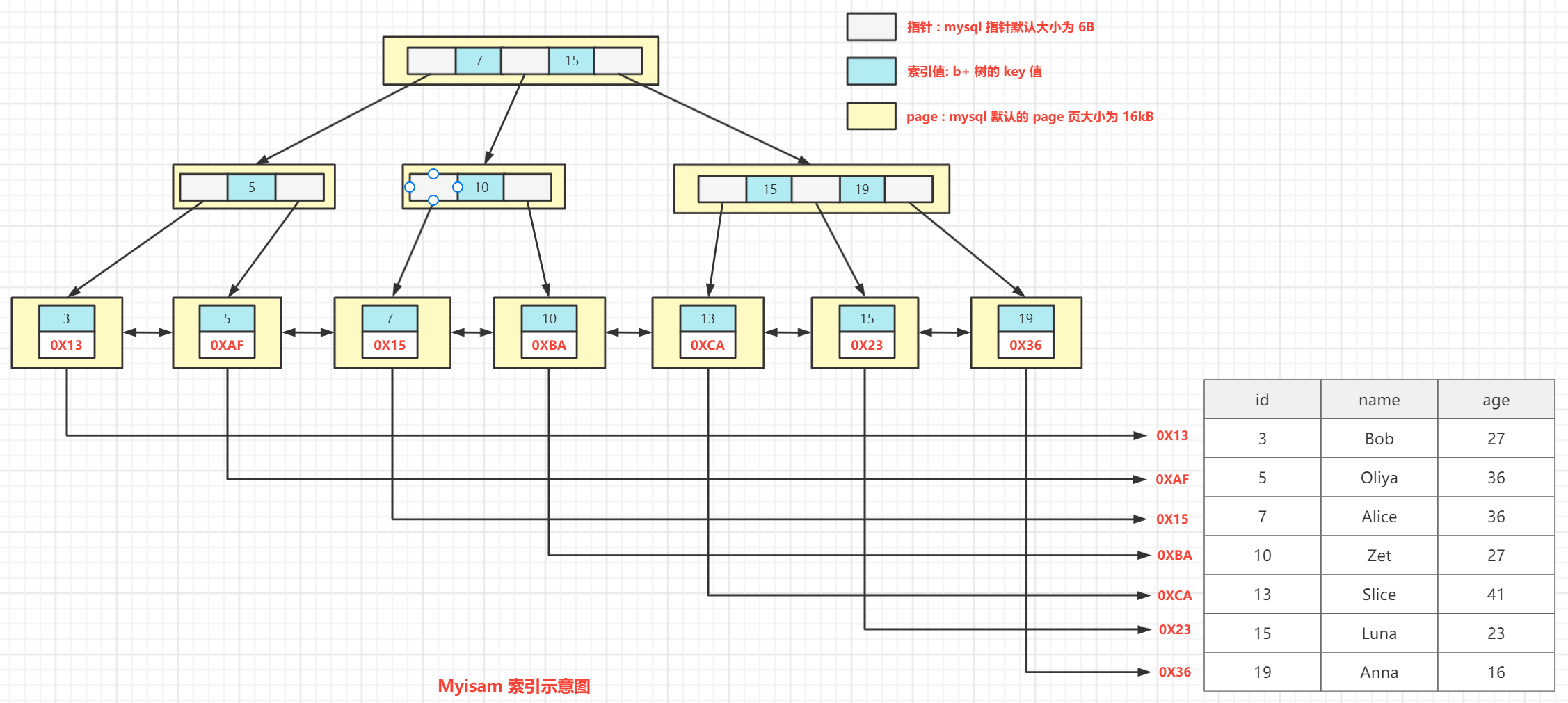
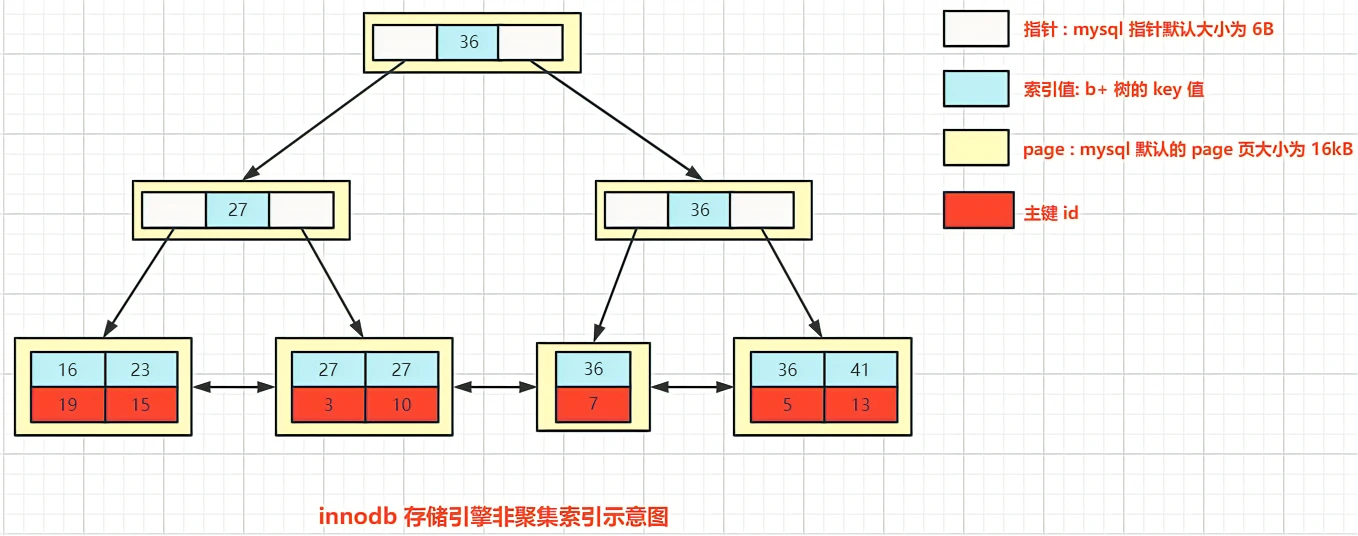
对于叶子节点的数据区存储的是数据的磁盘地址这种情况,就是多了一步寻址操作;
对于叶子节点的数据区存储的是聚集索引的id这种情况,在找到对应id后,会根据该id去聚集索引里面查找相应的数据,这个过程也称为回表。
那么为什么不直接使用聚集索引呢?
聚集索引一定存在且唯一;
一个表会有多个索引;SQL语句的检索条件也不可能一直是id主键;
所以这时肯定不能存储整行数据,不然有变成了聚集索引了;
且假设可以存储整行数据,那如果有十个索引,那是不是数据冗余了,且插入删除数据时,一致性问题难以保证!
参考链接:
https://www.cnblogs.com/xiaomaomao/p/16196006.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号