OpenEuler中C语言中的函数调用测试(选做)
作业要求
- 在X86_64架构下实践2.4中的内容
- 通过GDB查看寄存器的内容,把教材中的图填入具体的值
- 把2.4的C代码在OpenEuler中重新实践一遍,绘制出ARM64的逻辑框图
- 实验内容要经过答辩才能得到相应分数
实践流程1-在X86_64架构下
代码与汇编转换
通过教材可知,64位和32位在参数传递上存在差异。32位在传递参数的时候是直接通过堆栈进行传递,而64位在传递传输的时候是先将前6个参数依次传入rdi、rsi、rdx、rcx、r8、r9,然后剩余的参数像32位一样通过堆栈传递,在2.5的作业上用32位代码直接在64位上调用printf函数出现段错误的问题,教材这里直接说明了,就是这个差异导致的。
示例代码t.c:
#include <stdio.h>
int sub(int a,int b,int c,int d,int e,int f,int g,int h)
{
int u,v,w;
u = 9;
v = 10;
w = 11;
return a+g+u+v;
}
int main()
{
int a,b,c,d,e,f,g,h,i;
a=1;
b=2;
c=3;
d=4;
e=5;
f=6;
g=7;
h=8;
i=sub(a,b,c,d,e,f,g,h);
}
在x86_64的openEuler上转为汇编代码并查看:
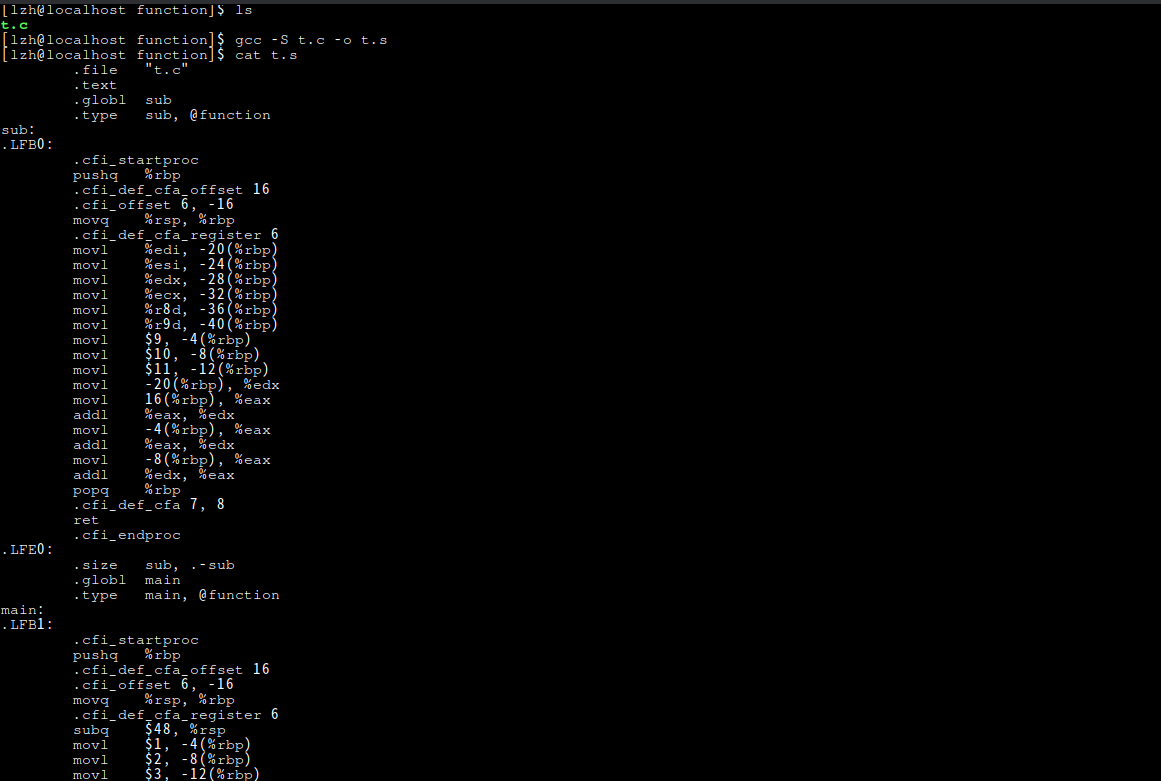
t.s:
.file "t.c"
.text
.globl sub
.type sub, @function
sub:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl %edi, -20(%rbp)
movl %esi, -24(%rbp)
movl %edx, -28(%rbp)
movl %ecx, -32(%rbp)
movl %r8d, -36(%rbp)
movl %r9d, -40(%rbp)
movl $9, -4(%rbp)
movl $10, -8(%rbp)
movl $11, -12(%rbp)
movl -20(%rbp), %edx
movl 16(%rbp), %eax
addl %eax, %edx
movl -4(%rbp), %eax
addl %eax, %edx
movl -8(%rbp), %eax
addl %edx, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size sub, .-sub
.globl main
.type main, @function
main:
.LFB1:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $48, %rsp
movl $1, -4(%rbp)
movl $2, -8(%rbp)
movl $3, -12(%rbp)
movl $4, -16(%rbp)
movl $5, -20(%rbp)
movl $6, -24(%rbp)
movl $7, -28(%rbp)
movl $8, -32(%rbp)
movl -24(%rbp), %r9d
movl -20(%rbp), %r8d
movl -16(%rbp), %ecx
movl -12(%rbp), %edx
movl -8(%rbp), %esi
movl -4(%rbp), %eax
movl -32(%rbp), %edi
pushq %rdi
movl -28(%rbp), %edi
pushq %rdi
movl %eax, %edi
call sub
addq $16, %rsp
movl %eax, -36(%rbp)
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1:
.size main, .-main
.ident "GCC: (GNU) 7.3.0"
.section .note.GNU-stack,"",@progbits
gdb分析
使用gcc -g t.s -o t将t.s进行编译,可以通过cgdb t直接对汇编代码进行调试,查看。
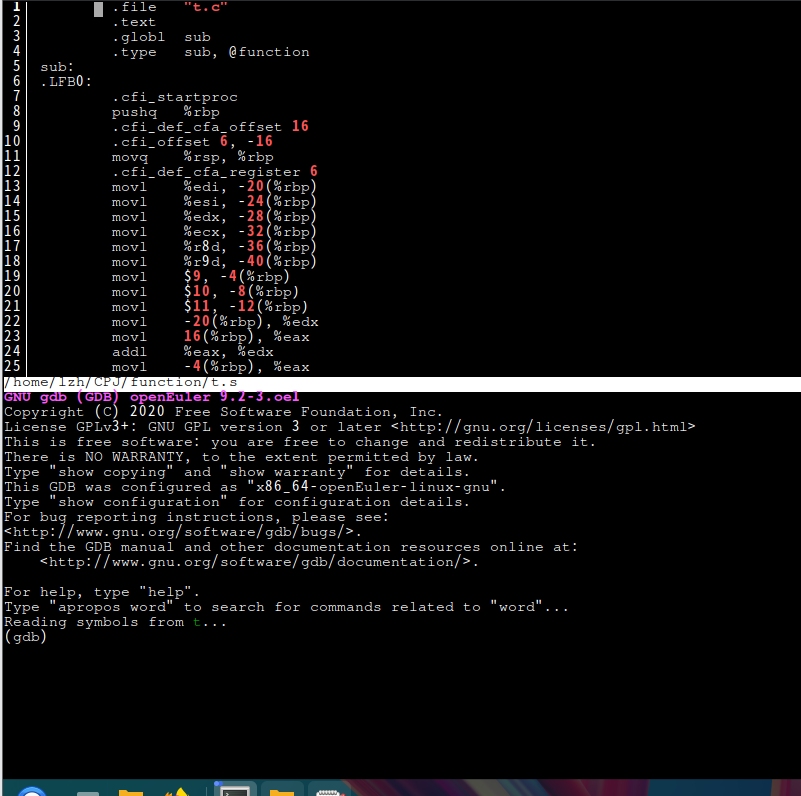
使用b main,r开始单步执行。
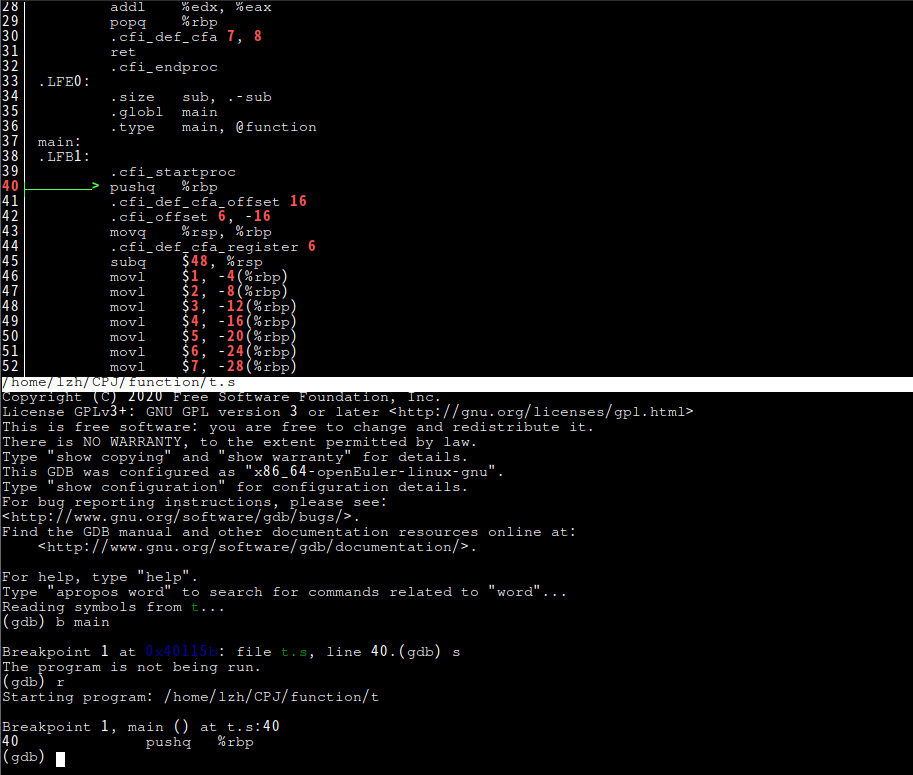
函数在执行前,都会先将rbp推入堆栈。
使用s单步执行。

首先是main函数的变量定义,首先esp减少48,为a~h提供空间。
查看寄存器的值:用i r,查看对应内存中的值,用x 0x012345678abcdef

对应上图ebp的值,查看堆栈中的a~h的值:
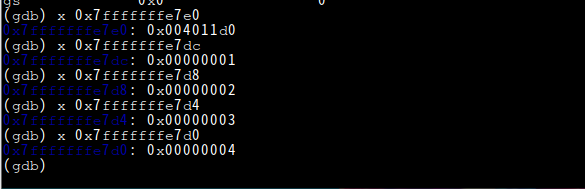
分析出main函数存值后的堆栈状态:

进入sub函数中后,在进行运算前,先将6个存在寄存器中的数存到了堆栈中:

然而,我看到代码并没有将多出来的两个参数(g和h)进行还原。
在运算时,需要将a、g、u、v相加。
其中,u和v是sub函数中定义的,a是通过寄存器传进来的,而h是通过堆栈传的。通过分析,h的值就是16(%rbp)。
下图中的框就是相加的部分。
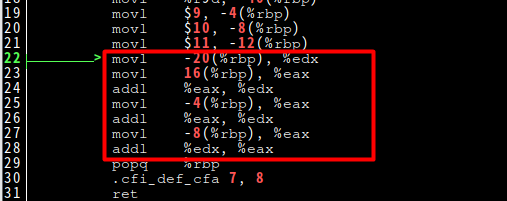
下图为堆栈分析图:
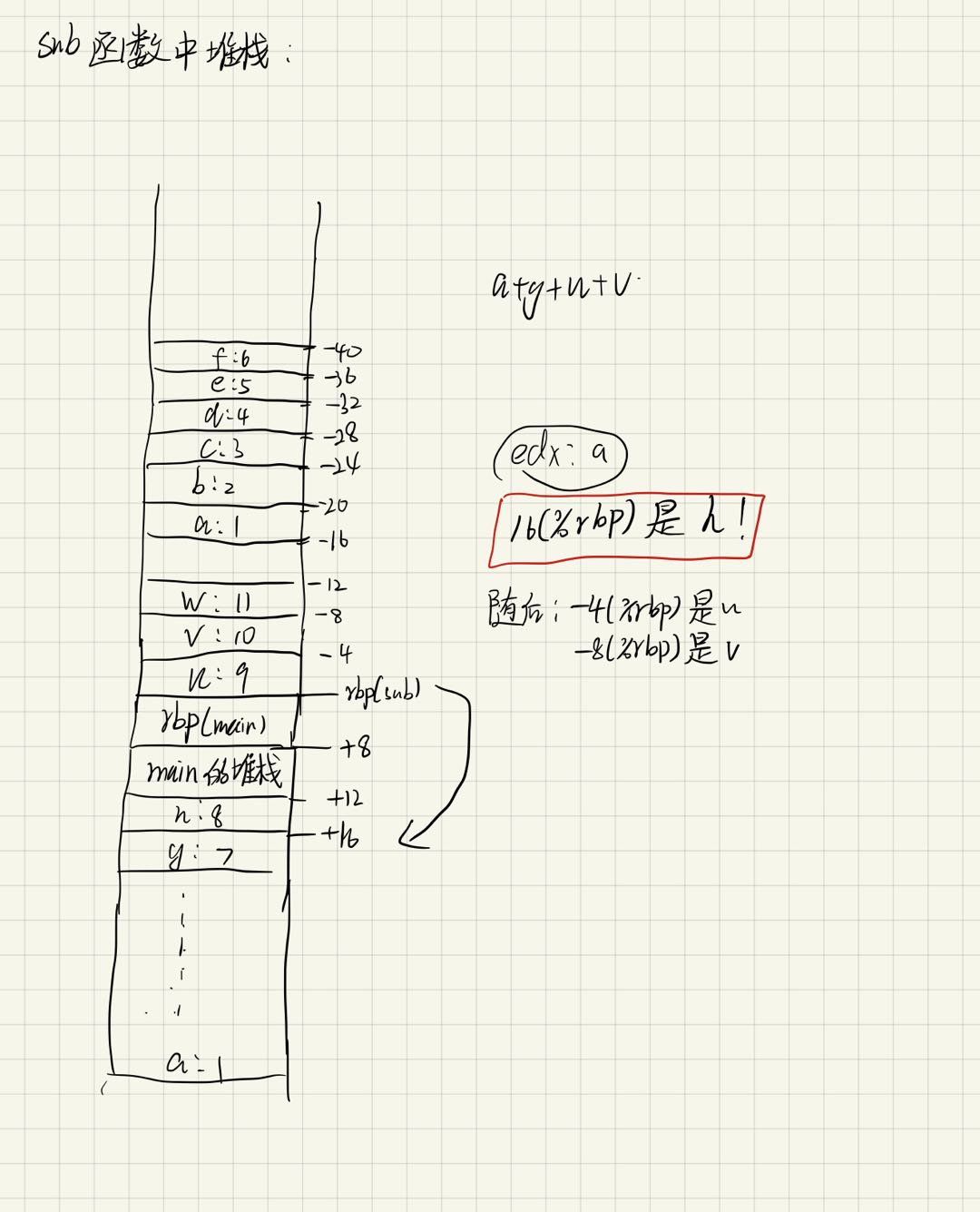
最后完成计算后,恢复rbp,返回。返回值存在rax中。
实践流程2-在Arm64架构下
华为鲲鹏服务器为Arm64架构。

代码与汇编转换
arm64架构下的的t.s:
.cpu generic+fp+simd
.file "t.c"
.text
.align 2
.global sub
.type sub, %function
sub:
.LFB0:
.cfi_startproc
sub sp, sp, #48
.cfi_def_cfa_offset 48
str w0, [sp,28]
str w1, [sp,24]
str w2, [sp,20]
str w3, [sp,16]
str w4, [sp,12]
str w5, [sp,8]
str w6, [sp,4]
str w7, [sp]
mov w0, 9
str w0, [sp,44]
mov w0, 10
str w0, [sp,40]
mov w0, 11
str w0, [sp,36]
ldr w1, [sp,28]
ldr w0, [sp,4]
add w1, w1, w0
ldr w0, [sp,44]
add w1, w1, w0
ldr w0, [sp,40]
add w0, w1, w0
add sp, sp, 48
.cfi_def_cfa_offset 0
ret
.cfi_endproc
.LFE0:
.size sub, .-sub
.align 2
.global main
.type main, %function
main:
.LFB1:
.cfi_startproc
stp x29, x30, [sp, -64]!
.cfi_def_cfa_offset 64
.cfi_offset 29, -64
.cfi_offset 30, -56
add x29, sp, 0
.cfi_def_cfa_register 29
mov w0, 1
str w0, [x29,60]
mov w0, 2
str w0, [x29,56]
mov w0, 3
str w0, [x29,52]
mov w0, 4
str w0, [x29,48]
mov w0, 5
str w0, [x29,44]
mov w0, 6
str w0, [x29,40]
mov w0, 7
str w0, [x29,36]
mov w0, 8
str w0, [x29,32]
ldr w0, [x29,60]
ldr w1, [x29,56]
ldr w2, [x29,52]
ldr w3, [x29,48]
ldr w4, [x29,44]
ldr w5, [x29,40]
ldr w6, [x29,36]
ldr w7, [x29,32]
bl sub
str w0, [x29,28]
ldp x29, x30, [sp], 64
.cfi_restore 30
.cfi_restore 29
.cfi_def_cfa 31, 0
ret
.cfi_endproc
.LFE1:
.size main, .-main
.ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-39)"
.section .note.GNU-stack,"",%progbits
参数传递流程分析
arm中:str为存储,ldr为取。
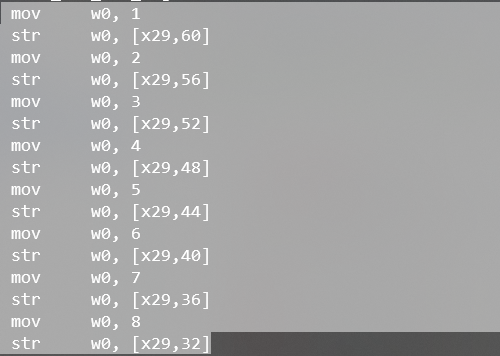
上图部分将a-h存到x29,60~x29,32的对应位置。
分析后的堆栈和流程图:
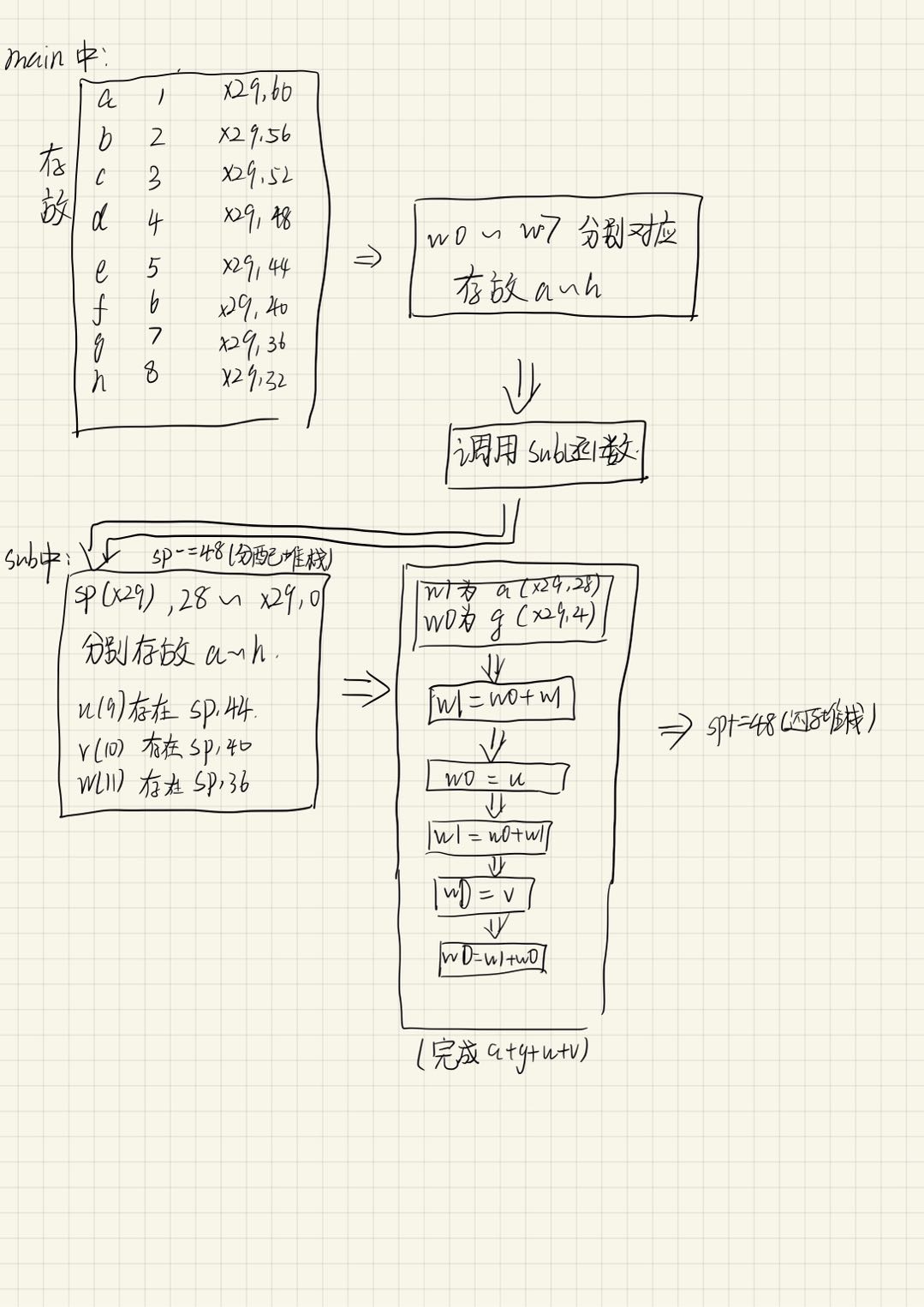
可见,本例arm64中的函数参数传递是通过w0-w7实现的。
代码链接
https://gitee.com/Ressurection20191320/code/tree/master/IS/function
