

php如何实现读取网易有道词典输出单词的xml格式并且转化为html形式
php实现读取网易有道词典输出单词的xml格式并且转化为html形式
一、总结
一句话总结:将xml中的文件用preg_match_all读出来,然后组合成想要的数据
1、explode除了爆炸的意思,还有什么意思?
解答:分割、分解、打碎
2、合并一个文档中多行为一行的方法是什么?
解答:替换,把换行符全部替换成空格。$con=str_replace(PHP_EOL,"",$con);
3、PHP正则中的多行匹配修饰符是?
解答:s。多行匹配修饰符s:$pattern="/<".$val.">.*?<\/".$val.">/s";。
4、如何解决file_put_contents函数 failed to open stream: Invalid argument的问题?
解答:把文件名从中文名改成英文名就OK了。
5、如何设置php文件的输出到页面的字符集?
解答:meta标签的charset属性,echo '<meta charset="utf-8"/>';。
6、preg_match_all的两个结果参数分别代表什么?
解答: $out[0]是包含匹配完整模式的字符串的数组, $out[1]是包含闭合标签内的字符串的数组。。
7、php中explode函数的作用是什么?
解答:用一个字符串去分割另外一个。
二、php实现读取网易有道词典的xml格式输出单词并且转化为html形式
正则表达式匹配多行问题:
xml中的trans标签,因为有的是多行的,所以用preg_match_all方法有一些匹配不到
解决策略一:去掉所有换行符
将所有行合并到一行,然后来提取,就没有换行符的影响了,这个时候回出现贪婪匹配的问题,就是比如<word>prompt</word><word>prompt</word><word>prompt</word>,匹配的时候直接匹配的是第一个<word>和最后一个</word>,中间的都被弄进去了,解决方法,优化正则表达式
合并行:$con=str_replace(PHP_EOL,"",$con);
惰性匹配:$pattern="/<".$val.">.*?<\/".$val.">/"; preg_match_all($pattern,$con,$temp);
解决策略二:多行匹配,可以用正则表达式修饰符s
多行匹配修饰符s:$pattern="/<".$val.">.*?<\/".$val.">/s"; preg_match_all($pattern,$con,$temp);
html标签贪婪匹配的问题:
比如<word>prompt</word><word>prompt</word><word>prompt</word>,匹配的时候直接匹配的是第一个<word>和最后一个</word>,中间的都被弄进去了,不同的word没有被区别开来
解决策略一:用惰性匹配就好
惰性匹配:$pattern="/<".$val.">.*?<\/".$val.">/"; preg_match_all($pattern,$con,$temp);
file_put_contents函数 failed to open stream: Invalid argument的问题
解答:把文件名从中文名改成英文名就OK了
1、原数据形式(部分)
<wordbook> <item> <word>prompt</word> <trans><![CDATA[adj. 敏捷的,迅速的;立刻的 vt. 提示;促进;激起;(给演员)提白 n. 提示;付款期限;DOS命令:改变DOS系统提示符的风格 adv. 准时地]]></trans> <phonetic><![CDATA[[prɒm(p)t]]]></phonetic> <tags></tags> <progress>1</progress> </item> <item> <word>expression</word> <trans><![CDATA[n. 表现,表示,表达;表情,脸色,态度,腔调,声调;式,符号;词句,语句,措辞,说法]]></trans> <phonetic><![CDATA[[ɪk'sprɛʃən]]]></phonetic> <tags></tags> <progress>1</progress> </item> </wordbook>
2、最后呈现形式
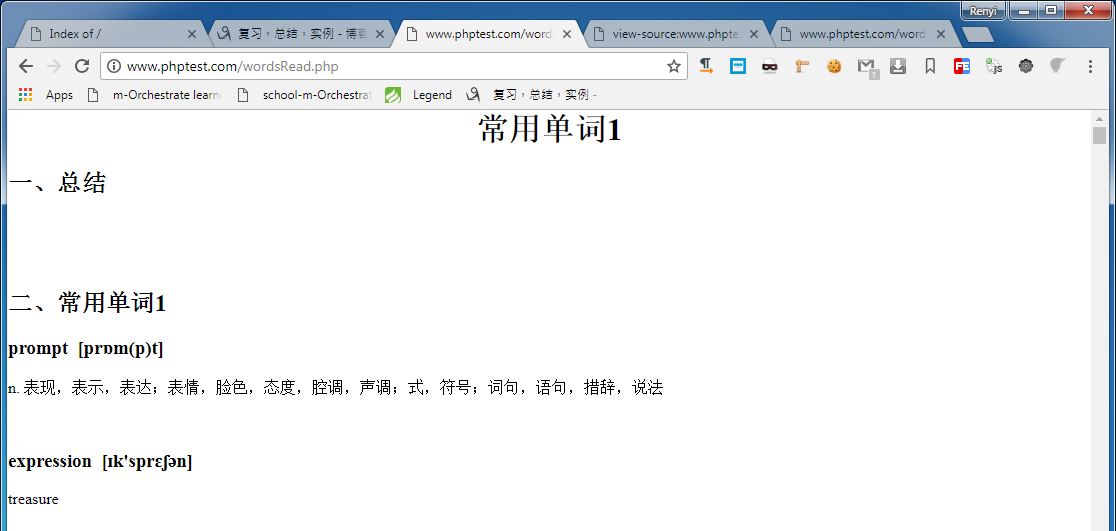
3、代码
1 <?php 2 /** 3 * Created by PhpStorm. 4 * User: rfan 5 * Date: 31/5/2018 6 * Time: 12:29 PM 7 */ 8 echo '<meta charset="utf-8"/>'; 9 $con=file_get_contents('words.xml'); 10 11 //应该是由于换行符的问题导致的trans匹配不到,那可以把所有的内容匹配成一行就好 12 $con=str_replace(PHP_EOL,"",$con); 13 //echo $con; 14 15 16 //XML标签配置 17 $xmlTag=[ 18 'word', 19 'trans', 20 'phonetic', 21 'tags', 22 'progress' 23 ]; 24 $arr = array(); 25 foreach ($xmlTag as $key=>$val){ 26 //应该是由于换行符的问题导致的trans匹配不到,那可以把所有的内容匹配成一行就好 27 /***********************************未去掉换行符后的正则表达式***********************************/ 28 // $pattern='/<'.$val.'>'.'.*'.'/<\/'.$val.'>'; 29 // $pattern="/<".$val.">[^<>]*<\/".$val.">/"; 30 // $pattern="/<".$val.">.*\n*.*<\/".$val.">/"; //多行的问题只能匹配139个 31 // $pattern="/<".$val.">.*?<\/".$val.">/s"; //正确 32 /***********************************去掉换行符后的正则表达式***********************************/ 33 $pattern="/<".$val.">.*?<\/".$val.">/"; //正确 34 // echo $pattern.'</br>'; 35 preg_match_all($pattern,$con,$temp); 36 $arr[] = $temp[0]; 37 // echo '<pre>'; 38 // var_dump($temp); 39 // echo '</pre>'; 40 } 41 42 //echo '<pre>'; 43 //var_dump($arr); 44 //echo '</pre>'; 45 46 //去除XML标签并组装数据 47 $data = array(); 48 foreach($arr as $key => $value) { 49 foreach($value as $k => $v) { 50 $a = explode($xmlTag[$key].'>', $v); 51 $v = substr($a[1], 0, strlen($a[1])-2); 52 $data[$k][$xmlTag[$key]] = $v; 53 } 54 } 55 56 //echo '<pre>'; 57 //var_dump($data); 58 //echo '</pre>'; 59 60 61 //清除数据里面的<![CDATA[]]> 62 foreach($data as $key=>&$val){ 63 foreach($val as $k => &$v){ 64 // echo $v.'</br>'; 65 $start="/<!\[CDATA\[/"; 66 $end="/\]\]>/"; 67 $v=preg_replace($start,"",$v); 68 $v=preg_replace($end,"",$v); 69 // echo $k.': '.$v.'</br>'; 70 } 71 } 72 73 74 //给数据添加好标签,然后按照自己格式输出到文本 75 76 //文章题号开始标记 77 $articleStart=1; 78 //每篇文章取单词的数目 79 $selectWordNum=20; 80 //单词索引号 81 $iii=1; 82 foreach($data as $key=>&$val){ 83 if($iii%20==1){ 84 85 if(isset($articleContent)&&!empty($articleContent)){ 86 echo $articleContent; 87 88 $fileName='commonWords/'.$pureTitle_en.'.html'; 89 file_put_contents($fileName,$articleContent); 90 } 91 $pureTitle_en='commonWords'.$articleStart; 92 $pureTitle_cn='常用单词'.$articleStart++; 93 $title='<h1 style="text-align: center;">'.$pureTitle_cn.'</h1>'; 94 $headPart=$title.'<h2>一、总结</h2><p> </p><p> </p><h2>二、'.'测试题-简答题'.'</h2>'; 95 $articleContent=$headPart; 96 97 98 99 } 100 //每道题目的问题 101 $pureQuestion=$val['word']." ".$val['phonetic']; 102 $jj=$iii%20==0?20:$iii%20; //保证每篇文章每道题目的序号都是1-20 103 $question='<h3>'.$jj.'、'.$pureQuestion.'</h3>'; 104 //每道题目的答案 105 $pureAnswer=$val['trans']; 106 $answer='<p>'.$pureAnswer.'</p><p> </p><p> </p>'; 107 //添加每篇文章的内容 108 $articleContent.=$question.$answer; 109 110 unset($val['tags']); 111 unset($val['progress']); 112 113 $iii++; 114 } 115 116 //如果有多的没完的哪一篇,把多的没完的那一篇打下来 117 if(isset($articleContent)&&!empty($articleContent)){ 118 echo $articleContent; 119 120 $fileName='commonWords/'.$pureTitle_en.'.html'; 121 file_put_contents($fileName,$articleContent); 122 } 123 124 125 126 //$str="dfafeasfasefase"; 127 //$start="/^dfa/"; 128 //$end="/ase$/"; 129 //echo $str.'</br>'; 130 //$str=preg_replace($start,"",$str); 131 //echo $str.'</br>'; 132 //$str=preg_replace($end,"",$str); 133 //echo $str.'</br>'; 134 135 //echo '<pre>'; 136 //var_dump($data); 137 //echo '</pre>'; 138 139 //按照自己格式输出到文本 140 //$file='wordsOk.text'; 141 //file_put_contents($filet,$data);
三、附加
1、preg_match_all 使用实例
1 <?php 2 preg_match_all("|<[^>]+>(.*)</[^>]+>|U", 3 "<b>example: </b><div align=left>this is a test</div>", 4 $out, PREG_PATTERN_ORDER); 5 echo $out[0][0] . ", " . $out[0][1] . "\n"; 6 echo $out[1][0] . ", " . $out[1][1] . "\n"; 7 ?> 8 以上例程会输出: 9 10 <b>example: </b>, <div align=left>this is a test</div> 11 example: , this is a test
因此, $out[0]是包含匹配完整模式的字符串的数组, $out[1]是包含闭合标签内的字符串的数组。
四、测试题-简答题
1、explode除了爆炸的意思,还有什么意思?
解答:分割、分解、打碎
2、合并一个文档中多行为一行的方法是什么?
解答:替换,把换行符全部替换成空格。$con=str_replace(PHP_EOL,"",$con);
3、PHP正则中的多行匹配修饰符是?
解答:s。多行匹配修饰符s:$pattern="/<".$val.">.*?<\/".$val.">/s";。
4、如何解决file_put_contents函数 failed to open stream: Invalid argument的问题?
解答:把文件名从中文名改成英文名就OK了。
5、如何设置php文件的输出到页面的字符集?
解答:meta标签的charset属性,echo '<meta charset="utf-8"/>';。
6、preg_match_all的两个结果参数分别代表什么?
解答: $out[0]是包含匹配完整模式的字符串的数组, $out[1]是包含闭合标签内的字符串的数组。。
7、php中explode函数的作用是什么?
解答:用一个字符串去分割另外一个。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号