

机器学习西瓜书白话解读笔记---0208-0215、主要是性能度量
机器学习西瓜书白话解读笔记---0208-0215、主要是性能度量
一、总结
一句话总结:
不要受了一点挫折就灰心丧气,最近都是这样,非常不好
1、错误率和精度?
仔细看下面的公式,非常简单,【错误率就是总错误个数除以样本总数m】,所以有个求和符号,求和符号右边【相当于一个满足条件就取1的符号】

2、查准率和查全率?


【查全率recall】:【所有的正例是否查全】:所以是 【正确正例/【真实】所有正例】
【查准率precision】:【所有的正例是否准确】:所以是 【正确正例/【预测】所有正例】
3、为什么有了精度,查全率和查准率还有意义?
【《机器学习实战》】,比如二分类问题,10%是5,【如果我们所有数字都不选5,那么有90%准确率,而一个模型96%准确率其实没啥意义】,所以这个时候可以用查全率和查准率
4、查全率recall和查准率precision 随着阈值反向变化?
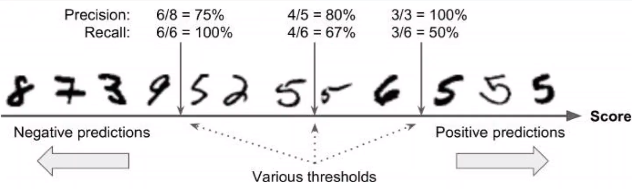
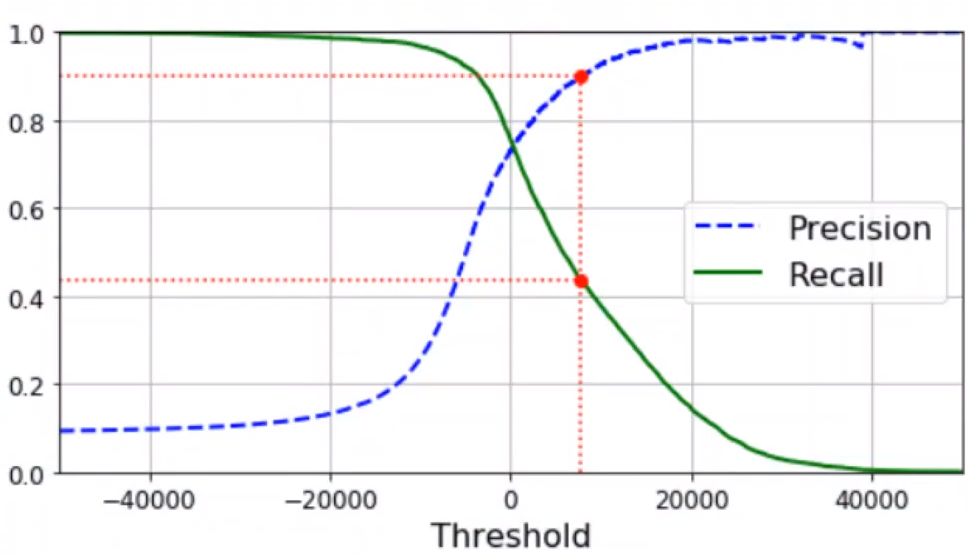
【查全率recall】:【所有的正例是否查全】:所以是 【正确正例/【真实】所有正例】;【查准率precision】:【所有的正例是否准确】:所以是 【正确正例/【预测】所有正例】
【阈值越严格,查准率precision越高,查全率recall越低】,阈值越宽松反之
5、查全率recall和查准率precision 对应关系图?


6、F1度量?
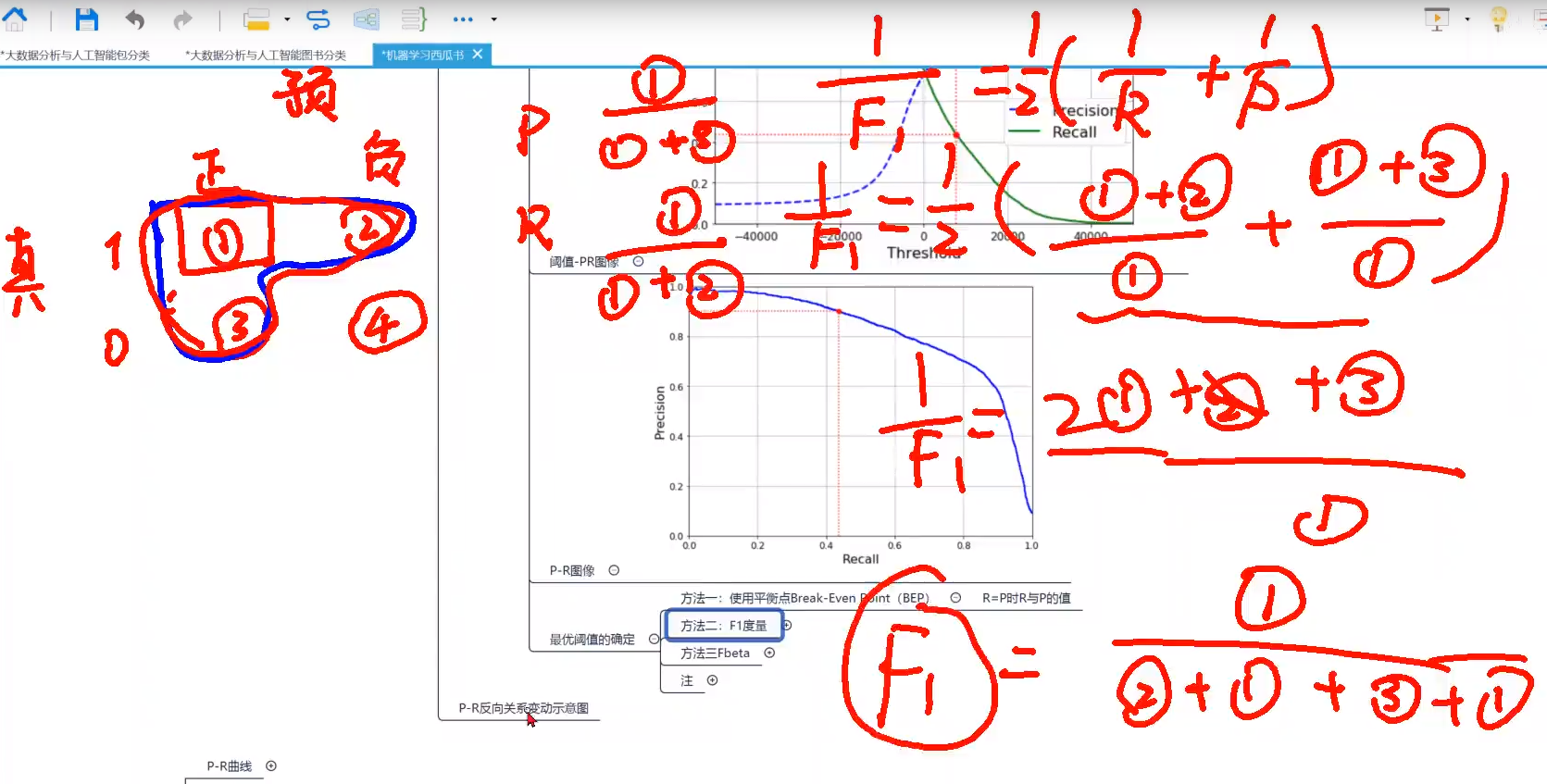
【F1度量】是在这个【所有P-R阈值中选一个阈值的一种方式】,另一种阈值选取的点是【使用平衡点Break-Even Point(BEP)】,R=P时R与P的值,即【交点】
【F1度量】就是上图中的【1在123中的占比】,用的是【调和平均数】
$$F 1 = \frac { 2 \times P \times R } { P + R } = \frac { 2 \times T P } { 样本总例 } + T P - T N$$
7、模型的最优阈值的确定(或者说P-R的最优阈值确定)?
1、使用【平衡点】:也就是【recall和precision的交点】
2、【F1度量】:也就是【1在123中的占比】
3、【Fbeta】:就是一个【加权的调和平均数】

8、最优阀值的确定方法中的F1和Fbeta的关系?
F1是【调和平均】,Fbeta是【加权调和平均】
F1是基于查准率与查全率的调和平均(harmonic mean)定义的:$$\frac { 1 } { F 1 } = \frac { 1 } { 2 } \cdot ( \frac { 1 } { P } + \frac { 1 } { R } )$$
Fbeta则是加权调和平均:$$\frac { 1 } { F _ { \beta } } = \frac { 1 } { 1 + \beta ^ { 2 } } \cdot ( \frac { 1 } { P } + \frac { \beta ^ { 2 } } { R } )$$

二、内容在总结中
博客对应课程的视频位置:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号