

宋浩《概率论与数理统计》笔记---概率论总结
宋浩《概率论与数理统计》笔记---概率论总结
一、总结
一句话总结:
【基本概念】:概率论也就是先讲概率的一些基本知识,然后讲随机变量和一些常用的分布
【一维】:一维的分布将完了,肯定要讲多维的分布的,然后要讲一些期望和方差等数字特征
【一般规律】:然后讲事情的一般规律(也就是大数定理和中心极限定理)
【估计大模型】:最后讲通过少量样本来估计不可取样本(比如人均收入)对应的模型,也就是大模型对应的参数(也就是参数估计)
二、概率论总结
博客对应课程的视频位置:
【基本概念】:概率论也就是先讲概率的一些基本知识,然后讲随机变量和一些常用的分布
【一维】:一维的分布将完了,肯定要讲多维的分布的,然后要讲一些期望和方差等数字特征
【一般规律】:然后讲事情的一般规律(也就是大数定理和中心极限定理)
【估计大模型】:最后讲通过少量样本来估计不可取样本(比如人均收入)对应的模型,也就是大模型对应的参数(也就是参数估计)
总结了的东西才是你自己的
一、随机事件及其概率
全集和空集
P(Ω)=1
P(Φ)=0
加法原理和乘法原理更好的解释?
加法原理:有几种情况
乘法原理:分几步
几何概率模型 实例?
几何概率模型 就是那些 线段、平面、立体 相关的模型
一个3cm的线段,一个质子扔到1-2之间的概率是1/3
一张桌子,一个质子扔到左边部分的的概率是1/2
Ω={(φ,x)|0<=φ<=pi,0<=x<=d/2}的图形解释?
以φ,x为横纵轴画图即可,即可转化为几何概率模型
频率与概率的关系?
【做大量实验,频率接近一个值,这个值就是概率】:ω_n(A)-->P
【用频率来求概率】:在大量重复进行同一试验时,事件A发生的频率m(A)/n总是接近于某个数,在它附近摆动,这个常数就是事件A的概率。因此只要n相当大,概率是可以通过频率来测量的,或者说频率是概率的一个近似。
条件概率
条件概率就是样本空间发生了变化,和原来的样本空间不一样了
P(A|B)不等于P(AB),而是P(AB)/P(B)
Ω样本空间,A,B两个事件,P(B)>0,在B已经发生的条件下,A发生的概率。这就是A对B的条件概率。P(A|B)
无条件概率 和 条件概率 的样本空间
P(A)无条件概率->样本空间Ω
P(A|B)条件概率->B=Ω_B
计算条件概率公式?
P(A|B)=n_AB/n_B,n表示样本数,n_B表示事件B对应的样本数
P(A|B)=(n_AB/n)/(n_B/n)=P(AB)/P(B)
计算条件概率的时候,样本空间发生了变化
联合概率P(AB)和条件概率P(A|B)的理解?
联合概率侧重二者同时发生,而条件概率侧重一个先发生另一个后发生。
P(AB)=AB/S,P(A|B)=AB/B=P(AB)/P(B)
可以看出,联合概率和条件概率的区别:虽然分子都是两个事件的交集,但是分母(样本空间)是不同的。
贝叶斯公式 P(B)P(A|B)=P(A)P(B|A) 的由来?
由概率论乘法公式联合而来,P(AB)=P(B)P(A|B),P(AB)=P(A)P(B|A)
乘法公式
P(AB)=P(B)P(A|B)
P(AB)=P(A)P(B|A)
P(A1A2...An)=P(A1)*P(A2|A1)*P(A3|A1A2)*P(An|A1A2...An-1)
P(ABC)=P(A)*P(B|A)*P(C|AB)
条件概率 P(B|A) 的几何意义?
画图的话就是A中的B,而不是全集中的B
全概率公式 如何理解?
利用条件概率 P(B|Ai) 的几何意义,可以看做是各个Ai里面的B拼起来
全概率公式和贝叶斯公式
全概率就是表示达到某个目的,有多种方式(或者造成某种结果,有多种原因),问达到目的的概率是多少(造成这种结果的概率是多少)
贝叶斯公式就是当已知结果,问导致这个结果的第i原因的可能性是多少?执果索因!
条件概率 意义及意义例子?
举个例子,比如让你背对着一个人,让你猜猜背后这个人是女孩的概率是多少?直接猜测,肯定是只有50%的概率,假如现在告诉你背后这个人是个长头发,那么女的概率就变为90%。
所以条件概率的意义就是,【当给定条件发生变化后,会导致事件发生的可能性发生变化】。
P(AB)的值?
A与B相互独立时,P(AB)=P(A)*P(B)
A与B不一定独立时:P(AB)=P(A)*P(B|A)或P(AB)=P(B)*P(A|B)
贝叶斯公式 和 全概率公式的本质区别?
导致发烧的原因可能是感冒、肺炎、白血病
全概率公式就是知道原因推结果:得这三种病以及这三种病发烧的概率,求发烧的概率是多少
贝叶斯公式就是知道结果推原因:推导致发烧的原因中哪个的概率最大
事件的独立性
A的概率不受B发生与否的影响
P(A|B)=P(A)
A,B独立 <==> P(AB)=P(A)*P(B)
独立和互不相容 不同时成立?
A,B独立:P(AB)=P(A)P(B)>0
A,B互不相容:AB=Φ:P(AB)=0 !== P(A)P(B)>0
两事件独立最大的意义是什么?
P(AB)好算:P(AB)=P(A)P(B)
独立和互不相容 对公式的简化 ?
互不相容:P(A+B)=P(A)+P(B),原來是P(A+B)=P(A)+P(B)-P(AB)
独立:P(AB)=P(A)P(B),原来是P(AB)=P(A)P(B|A)
事件的独立性:例子:P(A+B)=0.9,P(A)=0.4,求AB互不相容和AB独立时候的P(B)?
AB互不相容:AB=Φ,P(A+B)=P(A)+P(B)-P(AB),P(AB)=0,故P(B)=0.5
AB独立:P(AB)=P(A)P(B),P(A+B)=P(A)+P(B)-P(AB)=P(A)+P(B)-P(A)P(B),故P(B)=5/6
我们看到的多元线性回归中的概率公式推导,就是用的 事件之间的独立性?
P(A1A2...An)=P(A1)P(A2)...P(An)
伯努利模型:例:彩票每周开一次,十万分之一几率中奖,十年买520次 ,问从未中奖的概率是多少?
P_520(0)=C_520^0*(10^(-5))^0*(1-10^(-5))^520=0.99999^520=0.9948
二、随机变量及其分布
随机变量的概念
为了便于描述和解决问题,往往需要对每一个可能的结果指定一个数值,随机变量可以将样本空间中的点与数字联系起来,或者说把事件与数值能联系起来
随机变量(random variable)表示随机试验各种结果的实值单值函数。随机事件不论与数量是否直接有关,都可以数量化,即都能用数量化的方式表达。
随机事件数量化的好处是可以用数学分析的方法来研究随机现象。例如某一时间内公共汽车站等车乘客人数,电话交换台在一定时间内收到的呼叫次数,灯泡的寿命等等,都是随机变量的实例。
例:公交车站,每5分钟一辆,候车事件:X表示为[0,5];等车1-3分钟的事件{1<=x<=3},对应概率P{1<=x<=3}
离散型随机变量及其概率分布(抛硬币实例)?
抛硬币:样本X:1,0,对应概率P:1/2,1/2
大写X表示具体变量,小写x表示样本取值
其实就是把样本各个取值及其概率画图表画出来
离散型和连续性随机变量的概率表示方式?
离散型随机变量:概率分布
连续型随机变量:概率密度函数
频率密度直方图?
如果y轴为频率/组距,那么是 频率密度直方图,
每个小长方形的面积等于该组的频率,因为y轴是频率/组距,
所有的小长方形的面积之和为1
介于x=a,x=b之间的面积,近似等于它落在(a,b]之间的频率
概率密度函数?
频率密度直方图:如果y轴为频率/组距,那么是 频率密度直方图
求频率就是求面积(积分):介于x=a,x=b之间的面积,近似等于它落在(a,b]之间的频率
X~f(x):P{a<x<=b}=∫(a->b)f(x)dx:f(x)是概率密度函
概率密度函数 某一个x对应的值的意义是什么?
x对应的y并不是概率的大小,因为某个点的概率为0
x对应的y的值是取x附近的概率值的大小
P{x<X<x+△x}≈f(x)△x
分布函数
设X是一个随机变量,x是任意实数,函数F(x)=P(X<=x)称为X的分布函数。有时也记为X~F(x)。
直观理解分布函数?
分布函数就是变量小于等于某个特定值a的概率(或者频率,如果是用数据统计出来的话),也即F(a)=P(X<=a)
假设现在有全世界所有人的身高的分布函数,而你的身高是175cm,那么分布函数在175cm处的取值就是所有比你矮或者和你一样高的人占全世界所有人的比例。
姚明的身高是226cm,那么分布函数在226cm处的取值就是所有比姚明矮或者和姚明一样高的人占全世界所有人的比例。
分布函数F(x)=P(X<=x)对离散型和连续型都成立?
分布函数对离散型和连续型都成立,但是具体对离散型和连续型的求法不一样
泊松分布通俗理解
泊松分布可以通过无限细分的二项分布推出来,求极限的话就是得到的结果就是泊松分布
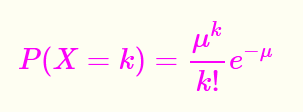
超几何分布
【从a个白球和b个黑球中抽取n个球】:最经典的引入超几何分布的模型就是,从a个白球和b个黑球中抽取n个球,那么以X表示抽取出的白球的数目,它的分布律满足
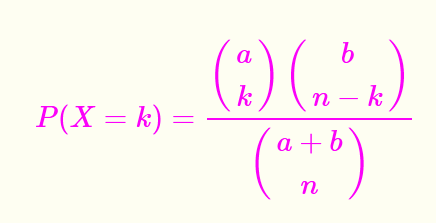
离散型常见分布?
01分布、几何分布、二项分布、泊松分布、超几何分布
超几何分布和二项分布的近似计算?
二项分布用泊松分布来计算:二项分布n>=100,np<=10,用泊松分布近似计算λ=np
超几何分布最终还是用泊松分布来计算:超几何分布在N大,n/N小时可以用二项分布来计算,不过还是不好算,最终还是要转化为泊松分布
指数分布
指数分布:X~Exp(λ)
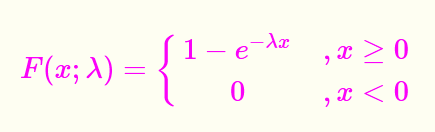
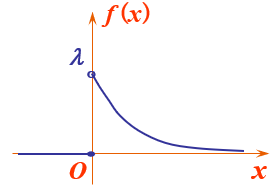
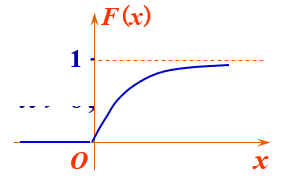
指数分布有什么用?
指数分布应用广泛,在日本的工业标准和美国军用标准中,【半导体器件的抽验方案都是采用指数分布】。
【此外,指数分布还用来描述大型复杂系统(如计算机)的平均故障间隔时间MTBF的失效分布】。
【机器或系统的失效分布模型】:指数分布虽然不能作为机械零件功能参数的分布规律,但是,它可以近似地作为高可靠性的复杂部件、机器或系统的失效分布模型,特别是在部件或机器的整机试验中得到广泛的应用。
常见随机变量的分布 的简单总结
几何分布:几何分布是第k次首次发生,前k-1次未发生
泊松分布:比如我们记录的人群每分钟闯红灯情况等例子
超几何分布:从a个白球和b个黑球中抽取n个球
指数分布:f(x)从λ到0的这一段线
离散型随机变量函数的分布
已知X是某分布,比如求Y=3X+5的分布。
已知x是如下离散分布,求Y=X^2的分布

连续型随机变量函数的分布
设X的f_X(x),y=g(x),Y=g(X)
第一步:F_Y(x)=F_X(x),两边对x求导
第二步:f_Y(x)=f_X(x),
分布函数F(x)和概率密度函数f(x)的关系
分布函数求导是概率密度函数
概率密度函数积分是分布函数:概率密度函数积分是求面积,那么自然结果是分布函数
连续型随机变量函数的分布 的求法
设随机变量X的密度函数为f_X(x),并假设y=g(x)及其一阶导数是连续函数,则Y=g(X)是连续型随机变量,现在来求Y的密度函数f_Y(x)
第一步:建立随机变量Y的分布函数F_Y(x)与X的分布函数F_X(x)之间的关系,或者求出随机变量Y的分布函数F_Y(x)
第二步:对F_Y(x)求导便得f_Y(x)
连续型随机变量函数的分布:例:设随机变量X的密度函数为f_X(x),Y=3X+2,求Y的密度函数f_Y(x)
1、建立随机变量Y的分布函数F_Y(x)与X的分布函数F_X(x)之间的关系:F_Y(x)=P{Y<=x}=P{3X+2<=x}=P{X<=(x-2)/3}=F_X((x-2)/3)
2、两边求导:f_Y(x)=1/3*f_X((x-2)/3)
3、如果知道f_X(x),直接将它替换成f_Y(x)即可:f_X(x)=1/4,(0<=x<=4),那么对应的f_X(x)=1/3*1/4,(0<=(x-2)/3<=4)
线性和非线性?
线性:2x+3y; x1+x2-x3; x+8y+17z+5
非线性:y=x^2; sinx; 1/y; lnz; tan(x^2+1)
三、多维随机变量及其分布
二维随机变量及其分布函数
二维随机变量表示要研究的问题是两个。比如比如打靶弹着点x和y
【F(x,y)=P{X<=x,Y<=y}】:设(X,Y)为二维随机变量,x,y为任意实数,二元函数F(x,y)=P{X<=x,Y<=y}称为二维随机变量(X,Y)的分布函数,或称为X与Y的联合分布函数
多维随机变量?
之前描述的问题都只有一个变量,比如身高,体重啥的
但是有些问题一定需要多个变量,比如打靶弹着点,比如弹着点的x和y
比如研究家庭生活情况的衣食住行四个方面
二维随机变量?
设E是随机试验,其样本空间为Ω,X,Y是定义在Ω上试验E的两个随机变量,称以X,Y为分量的向量(X,Y)为试验E的二维随机变量,或称二维随机向量
比如研究人的身高体重,身高体重就是(X,Y)向量
二维随机变量联合分布函数?
【F(x,y)=P{X<=x,Y<=y}】:设(X,Y)为二维随机变量,x,y为任意实数,二元函数F(x,y)=P{X<=x,Y<=y}称为二维随机变量(X,Y)的分布函数,或称为X与Y的联合分布函数
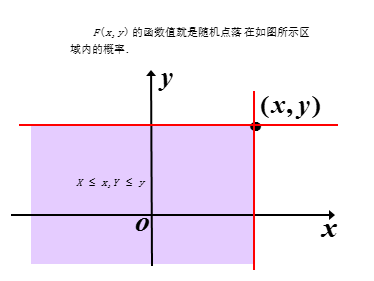
二维离散型的联合分布和边缘分布
二维离散型:X,Y取离散值
联合分布:离散的概率表:二维离散型随机变量(X,Y)的概率函数为联合分布
边缘分布:行或列求和:在二维离散型随机变量(X,Y)中,称分量X(或Y)的概率分布为(X,Y)的关于X(或Y)的 边缘分布。
二维离散型的联合分布

二维离散型的边缘分布 的直观理解
例中对行求和就是X的边缘分布,对列求和就是Y的边缘分布

二维连续型的联合分布和边缘分布
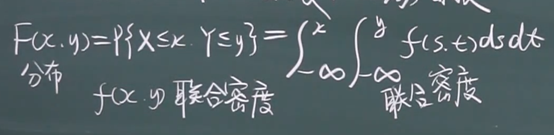
二维连续型的边缘分布
边缘分布用公式特别好求,直接用联合密度函数,X的边缘就对y积分,Y的边缘就对x积分

条件分布
条件分布就是在某条件之下发生的分布,比如某概率密度函数在x>1条件下的分布
比如身高体重,身高限定在1.7,看体重的分布
离散型随机变量的条件分布
就是样本空间发生了改变
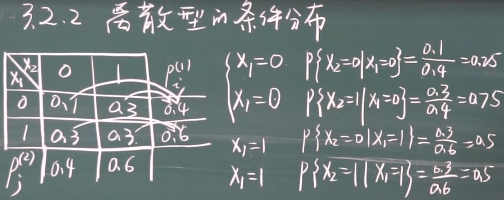
离散型随机变量的条件分布 公式
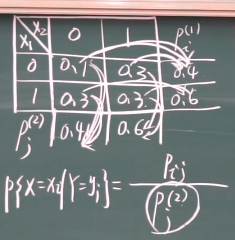
连续型随机变量的条件分布
和离散型一样,也都是用联合密度比上边缘密度
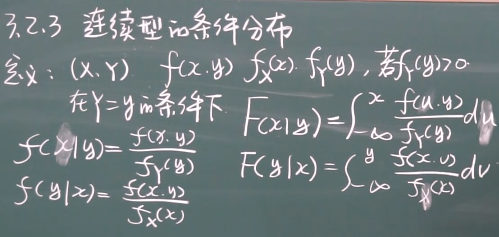
二维离散的独立性
比如独立就是右边,0.5*0.4=0.2,0.5*0.6=0.3,所有的都满足
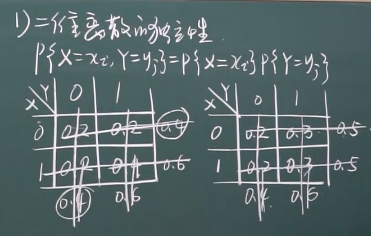
二维离散型随机变量函数的分布
就是把xy对应位置相乘就好,如果相同就加起来

四、随机变量的数字特征(期望、方差、协方差、相关系数等)
连续型变量的数学期望
就是对x*f(x)求积分,x是取值,f(x)是概率

连续型变量的数学期望 例子?
就是直接套连续型变量的数学期望的公式就好
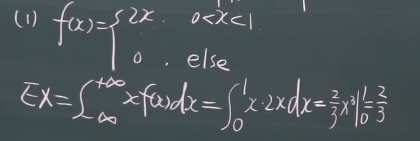
随机变量函数的数学期望
就是知道x的期望,此时Y=g(x),求Y的期望
离散性的期望就是xi*pi求和,如果求Y,就是g(x)*pi求和
连续的也是一样,直接把x换成g(x)

数学期望的性质
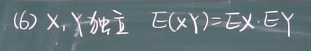
条件期望
条件期望 就是如果有两个变量,一个变量取定了某个值的前提下,另一个变量的期望
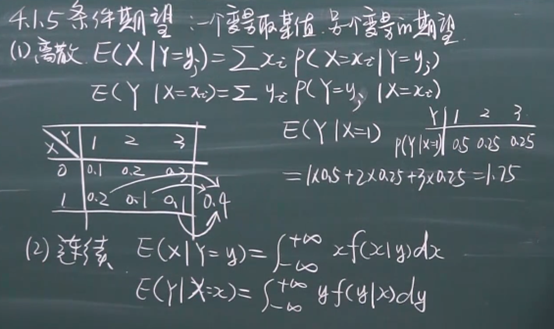
方差的定义
图中最下面的公式用的比较多,是根据方差的定义展开来推出来的

常见分布的期望和方差


协方差
Cov(X,Y)=E(XY)-EXEY
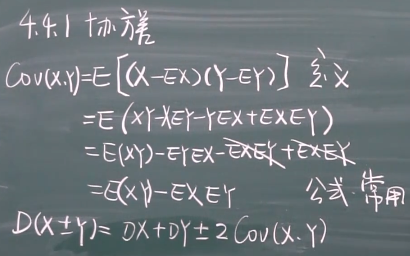
协方差和相关系数通俗理解
【协方差表示两变量的关系】:协方差可以通俗的理解为:两个变量在变化过程中是同方向变化?还是反方向变化?同向或反向程度如何?
【相关系数看做特殊协方差】:相关系数就是用X、Y的协方差除以X的标准差和Y的标准差,相关系数也可以看成协方差:一种剔除了两个变量量纲影响、标准化后的特殊协方差。
协方差通俗理解
【两变量变化关系】:两个变量在变化过程中是同方向变化?还是反方向变化?同向或反向程度如何?
【同向变化协方差为正】:你变大,同时我也变大,说明两个变量是同向变化的,这时协方差就是正的。
【反向变化协方差为负】:你变大,同时我变小,说明两个变量是反向变化的,这时协方差就是负的。
【协方差的数值表示同向变化的程度】:从数值来看,协方差的数值越大,两个变量同向程度也就越大。反之亦然。
相关系数
相关系数就是衡量和变量X,Y之间的相关关系
相关系数:就是协方差除以两个的标准差
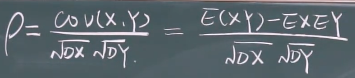
X,Y不相关 和 X,Y独立 怎么区分?
X,Y不相关:指的是X,Y线性不相关
X,Y独立:指的是X,Y之间没有任何关系,包括线性关系,非线性关系
X,Y独立,则X,Y不相关
中心矩与原点矩
原点矩:EX^k,期望是EX,所以期望是一阶原点矩
中心矩:E(X-EX)^k:一阶中心距E(X-EX)^1=EX-EX=0;二阶中心距E(X-EX)^2 就是方差
中心矩以EX为中心:E(X-EX)^k
原点矩是因为以原点为中心:E(X-0)^k
中心矩和原点矩的几何意义是什么
【原点矩就是几何图形的重心】;
【中心矩反映几何图形上点的分布规律,相当于将坐标原点移到重心上,此时的原点矩】。
五、大数定理与中心极限定理
大数定理
大数定理:大量重复试验的平均结果(期望)的稳定性。
切比雪夫不等式:描述了这样一个事实,事件大多会集中在平均值附近。
切比雪夫不等式
切比雪夫不等式:描述了这样一个事实,事件大多会集中在平均值附近。
切比雪夫不等式 就是期望和方差存在的时候,总体可以看成左边的概率小于右边的值
X-EX 就是这个数和期望的距离:
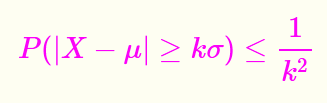
其中 k>0 ,μ是期望,σ是标准差。

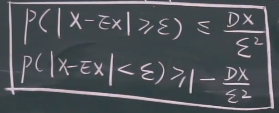
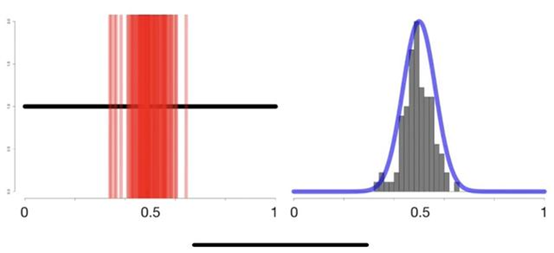
通俗理解中心极限定理
中心极限定理(CLT)指出,如果样本量足够大,【则变量均值的采样分布将近似于正态分布,而与该变量在总体中的分布无关】。
0-1均匀分布取点例子?
随着我们从均匀分布中抽取越来越多的随机样本,并在直方图上绘制样本均值,我们得到一个正态分布结果如下(见右曲线)
切比雪夫大数定理
变量均值收敛于期望均值

中心极限定理
中心极限定理:大量独立同分布的变量和的极限分布是正态分布:如果样本量足够大,则变量均值的采样分布将近似于正态分布,而与该变量在总体中的分布无关。
标准化之后,期望为0,方差为1,没标准化的话,期望为为nμ,方差为nσ^2
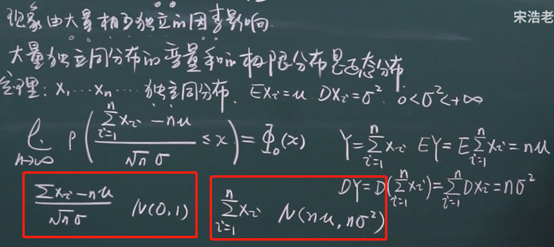
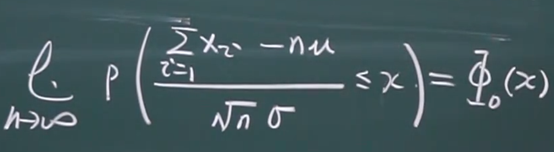
六、数理统计的基本概念
总体与样本
总体就是全体集合,样本就是抽的样本
样本变量与样本观测值
样本变量是Xi,样本观测值是xi
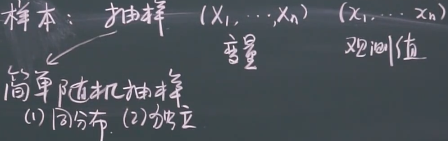
统计量定义:不含任何未知参数的样本的函数。

常用统计量
均值、样本方差、标准差、原点矩、中心距等都是常用统计量

七、参数估计(就是来估计参数)
参数估计-点估计
参数估计:【就是用样本的值来猜总体分布的参数值】:用样本构造函数来估计参数的值
比如班上同学身高服从正态分布,但是这个正态分布的均值μ和方差σ^2我们不知道,这个时候我们可以取80个同学测身高,会得到一个具体的正态分布,这样来估计均值μ和方差σ^2

参数空间?
参数空间就是参数的取值范围
什么是点估计和区间估计?
【点估计只猜一个点】:比如猜身高,猜了一个数,比如185,那么就是点估计
【区间估计猜一个区间】:区间估计就是,比如猜身高,我的身高在150-250之间
参数估计-极大似然估计
概率大的事件比概率小的事件更容易发生
将使A发生的P最大的参数值作为估计值
极大似然估计:就是总体的某些参数未知,通过样本取样来估计这些参数,极大就是最大,似然就是可能性,合起来就是对参数的最大可能性估计

极大似然估计 为什么要连乘起来
本来是联合概率函数,因为独立,所以分开来写
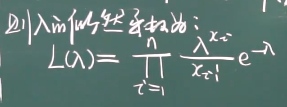
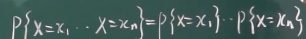
极大似然估计 做题步骤
1、确定总体的概率(对离散型)密度(对连续型)函数
2、写似然函数L(λ),λ是参数
3、两边去ln(因为是连乘),得lnL(λ)
4、对λ求导,得最大值的话,就是令导数为0

极大似然估计 泊松分布例子(离散型)
就是照着极大似然估计 做题步骤的四步走


 浙公网安备 33010602011771号
浙公网安备 33010602011771号