

python超简单实用爬虫操作---6、模拟登录获取数据
python超简单实用爬虫操作---6、模拟登录获取数据
一、总结
一句话总结:
爬虫获取登录才能获取的数据也很简单,在爬虫请求的请求头中加上cookie即可,爬所有登录才能获取数据的网站都可以这么干
import requests headers = { "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36", } cookies={ "_ga":"GA1.2.1718512095.1585155221", "_gid":"GA1.2.1552723320.1594148642", ".Cnblogs.AspNetCore.Cookies":"", } url ="https://www.cnblogs.com/Renyi-Fan/p/13277298.html" response = requests.get(url,headers=headers,cookies=cookies) print(response.status_code) print(response.text)
二、模拟登录获取数据
博客对应课程的视频位置:6、模拟登录获取数据-范仁义-读书编程笔记
https://www.fanrenyi.com/video/35/323
一、爬虫介绍
爬虫介绍
爬虫就是自动获取网页内容的程序
google、百度等搜索引擎本质就是爬虫

虽然大部分编程语言几乎都能做爬虫,但是做爬虫最火的编程语言还是python
python中爬取网页的库有python自带的urllib,还有第三方库requests等,
requests这个库是基于urllib,功能都差不多,但是操作啥的要简单方便特别多
Requests is an elegant and simple HTTP library for Python, built for human beings.
爬虫实例
比如我的网站 https://fanrenyi.com
比如电影天堂 等等
课程介绍
讲解python爬虫操作中特别常用的操作,比如爬取网页、post方式爬取网页、模拟登录爬取网页等等
二、爬虫基本操作
# 安装requests库
# pip3 install requests
# 引入requests库
# import requests
In [3]:
import requests
# 爬取博客园博客数据
response = requests.get("https://www.cnblogs.com/Renyi-Fan/p/13264726.html")
print(response.status_code)
# print(response.text)
In [7]:
import requests
# 爬取知乎数据
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36"
}
response = requests.get("https://www.zhihu.com/",headers=headers)
print(response.status_code)
#print(response.text)
In [8]:
import requests
response = requests.get("http://httpbin.org/get")
print(response.text)
# "User-Agent": "python-requests/2.22.0",
三、获取各种请求的数据
import requests
response = requests.get('http://httpbin.org/get')
response = requests.post('http://httpbin.org/post', data = {'key':'value'})
response = requests.put('http://httpbin.org/put', data = {'key':'value'})
response = requests.delete('http://httpbin.org/delete')
response = requests.head('http://httpbin.org/get')
response = requests.options('http://httpbin.org/get')
import requests
response = requests.post('http://httpbin.org/post', data = {'key':'value'})
print(response.text)
结果
{
"args": {},
"data": "",
"files": {},
"form": {
"key": "value"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "9",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-5f05ee86-26bd986d7947684573f04544"
},
"json": null,
"origin": "119.86.155.123",
"url": "http://httpbin.org/post"
}
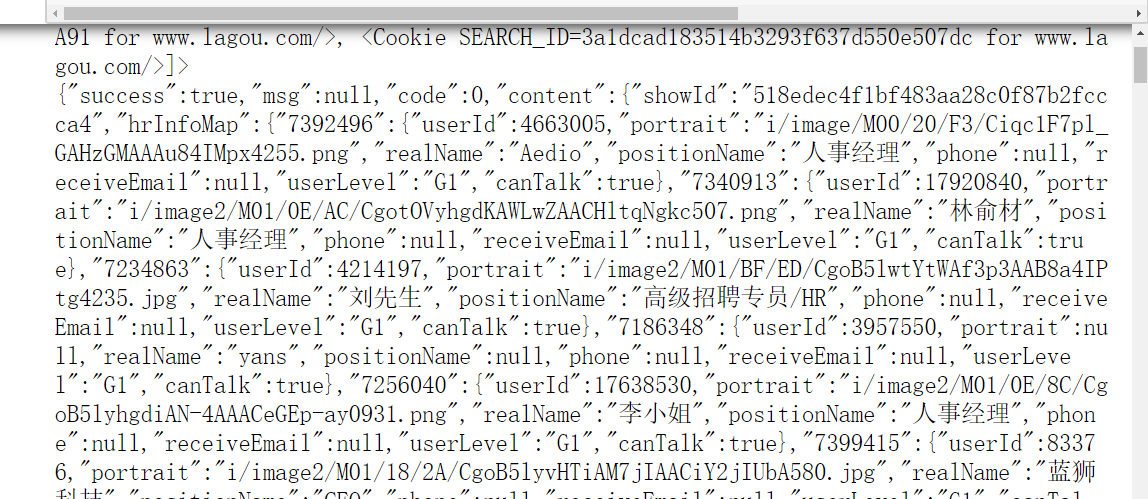
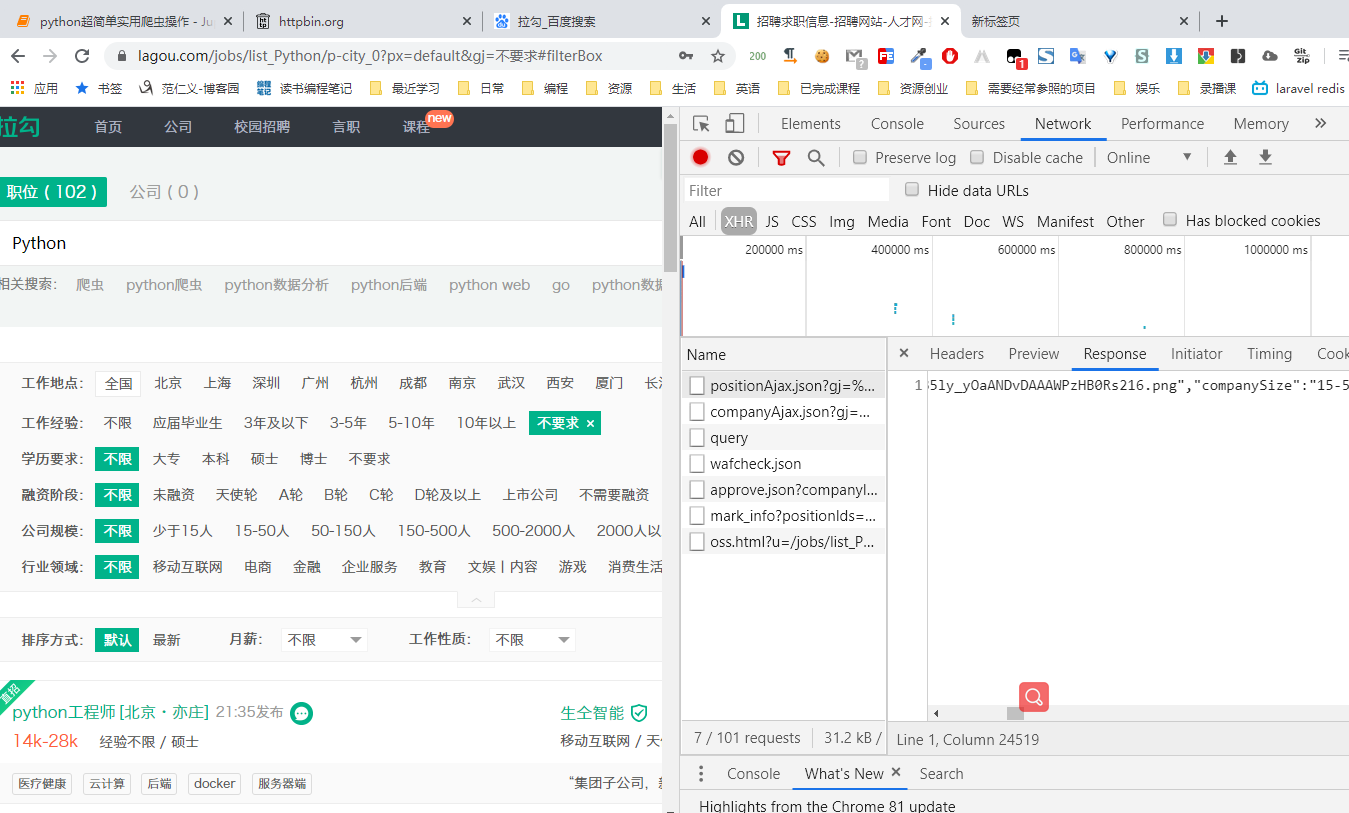
# 爬取拉勾网的post请求数据
url = "https://www.lagou.com/jobs/positionAjax.json?gj=%E4%B8%8D%E8%A6%81%E6%B1%82&px=default&needAddtionalResult=false"
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36",
"referer":"https://www.lagou.com/jobs/list_Python/p-city_0?px=default&gj=%E4%B8%8D%E8%A6%81%E6%B1%82"
}
# 用session对象,可以保持cookie等参数的一致
session = requests.Session()
response = session.get("https://www.lagou.com/jobs/list_Python/p-city_0?px=default&gj=%E4%B8%8D%E8%A6%81%E6%B1%82#filterBox",headers=headers)
print(response.cookies)
response = session.post(url,cookies=response.cookies,headers=headers)
print(response.text)
四、爬取图片
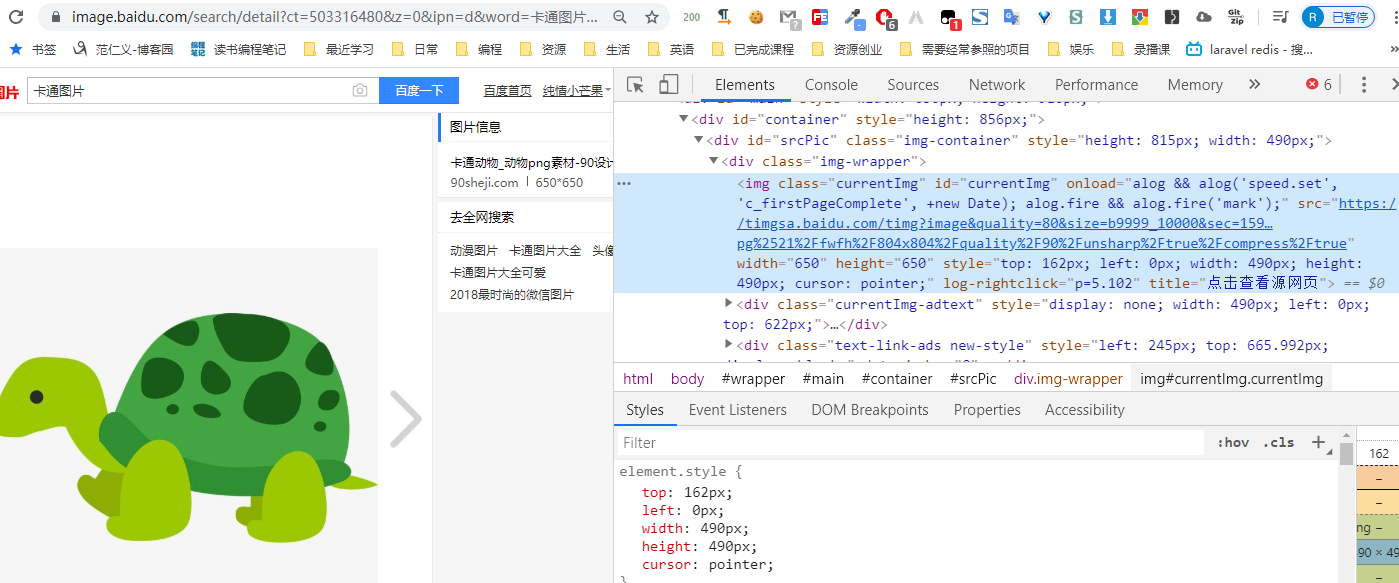
import requests
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36",
}
url ="https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1594286367651&di=7f176da3578634bc67e5f38e24438b0c&imgtype=0&src=http%3A%2F%2Fbpic.588ku.com%2Felement_origin_min_pic%2F16%2F07%2F10%2F205782447d16b2a.jpg%2521%2Ffwfh%2F804x804%2Fquality%2F90%2Funsharp%2Ftrue%2Fcompress%2Ftrue"
response = requests.get(url,headers=headers)
print(response.status_code)
# print(response.text)
# print(response.content)
with open("test.jpg","wb") as f:
f.write(re
五、爬取视频
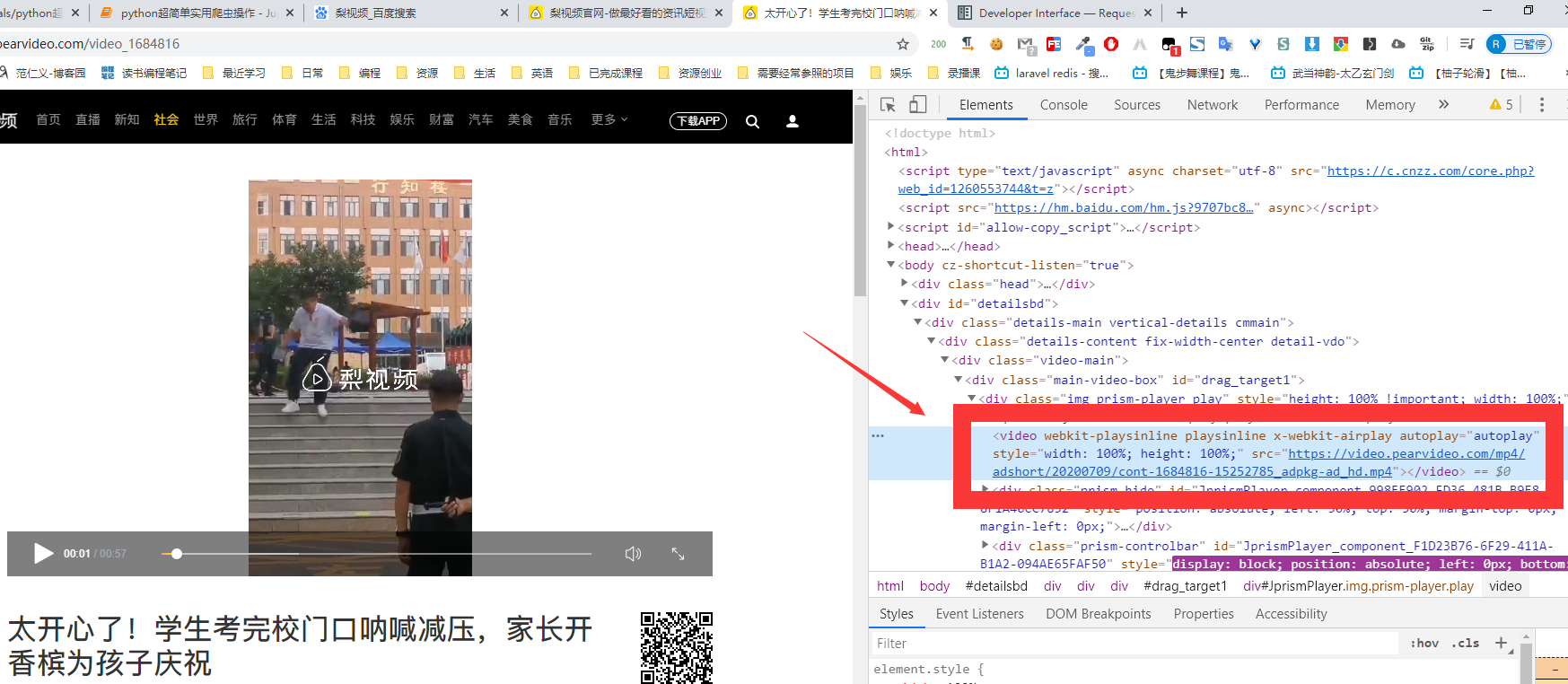
import requests
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36",
}
url ="https://video.pearvideo.com/mp4/adshort/20200709/cont-1684816-15252785_adpkg-ad_hd.mp4"
response = requests.get(url,headers=headers)
print(response.status_code)
# print(response.text)
# print(response.content)
with open("v.mp4","wb") as f:
f.write(response.content)
print("下载完成")

# 用流的方式来爬视频
import requests
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36",
}
url ="https://video.pearvideo.com/mp4/adshort/20200709/cont-1684816-15252785_adpkg-ad_hd.mp4"
response = requests.get(url,headers=headers,stream=True)
print(response.status_code)
# print(response.text)
# print(response.content)
with open("v.mp4","wb") as f:
for i in response.iter_content(chunk_size=1024):
f.write(i)
print("下载完成")

# 显示下载视频的进度
import requests
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36",
}
url ="https://video.pearvideo.com/mp4/adshort/20200709/cont-1684816-15252785_adpkg-ad_hd.mp4"
response = requests.get(url,headers=headers,stream=True)
print(response.status_code)
print(response.headers['content-length'])
content_size = int(response.headers['content-length'])
# print(response.text)
# print(response.content)
n = 1
with open("v.mp4","wb") as f:
for i in response.iter_content(chunk_size=1024):
rate=n*1024/content_size
print("下载进度:{0:%}".format(rate))
f.write(i)
n+=1
print("下载完成")
六、模拟登录获取数据
import requests headers = { "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36", } cookies={ "_ga":"GA1.2.1718512095.1585155221", "_gid":"GA1.2.1552723320.1594148642", ".Cnblogs.AspNetCore.Cookies":"", } url ="https://www.cnblogs.com/Renyi-Fan/p/13277298.html" response = requests.get(url,headers=headers,cookies=cookies) print(response.status_code) print(response.text)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号